Decision Matrices for Inter-Site CCR Recovery in E2K7
Thought I would take the opportunity to re-blog my CCR decision matrices that I first blogged back in June this year. They have been reviewed by a number of colleagues and have been revised somewhat and think the flow is a bit more logical in some places ...and a couple of mistakes have been rectified. I hope you find them of use....
The ability to continue to provide a full service to your user community in the event of the loss of a data centre is an increasingly common requirement. The use of Cluster Continuous Replication (CCR) with Exchange 2007 is an obvious choice in providing some of the functionality to meet this requirement. One advantage to this approach is that the reliance on expensive storage replication solutions might be reduced. In addition a disaster recovery scenario is managed from within one team rather than several. In most cases the messaging team can manage the restoration of service without the intervention from the storage team, or from a remote 3rd party hardware vendor for example. The use of Exchange Server data replication as opposed to storage replication solutions also gives us more options to use Powershell scripts to assist administrators in simplifying and controlling service and data recovery.
An example Exchange 2007 design using CCR is as follows:
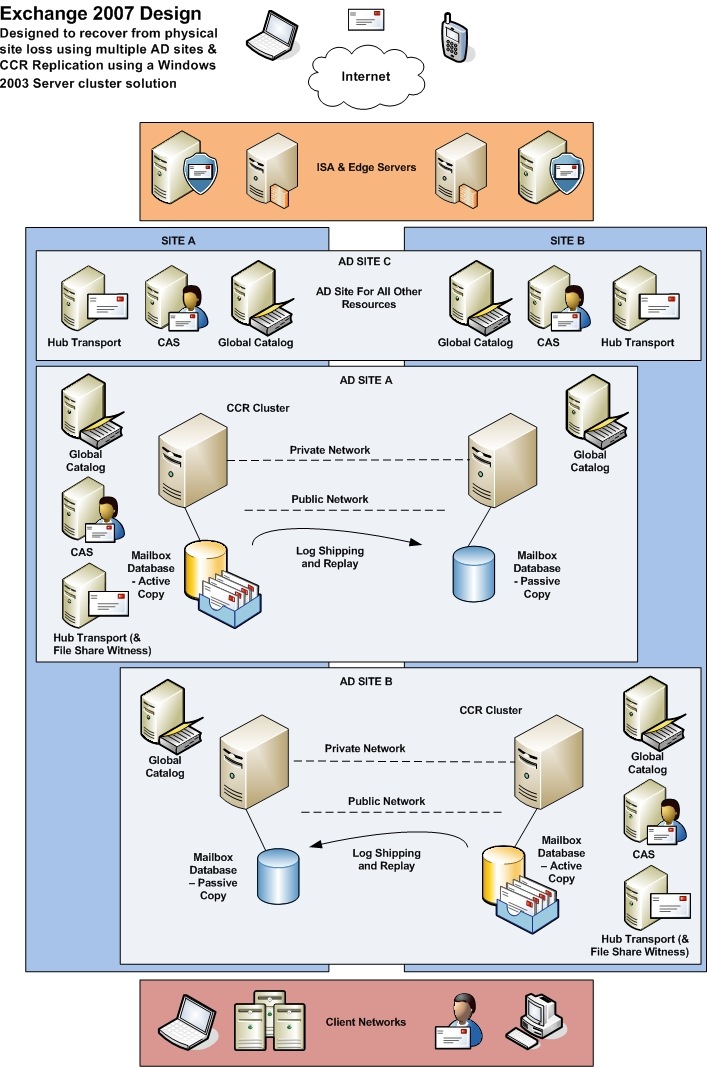
With any design it is important to understand the processes and decision making that might be involved when certain scenarios present themselves. If we are designing for high availability administrators need to understand what decisions might need to be made and the processes that would be required should a particular set of circumstances occur. For example, what should the recovery strategy be in the event of the loss of a single mailbox database? Should the Exchange cluster group be moved to the passive node at this stage? If so this would mean the temporary loss of service to all users on this server for the sake of those on one mailbox store.
The following flowcharts show the likely processes and decision making flow that might be involved in certain disaster recovery situations based on the above Exchange 2007 design.
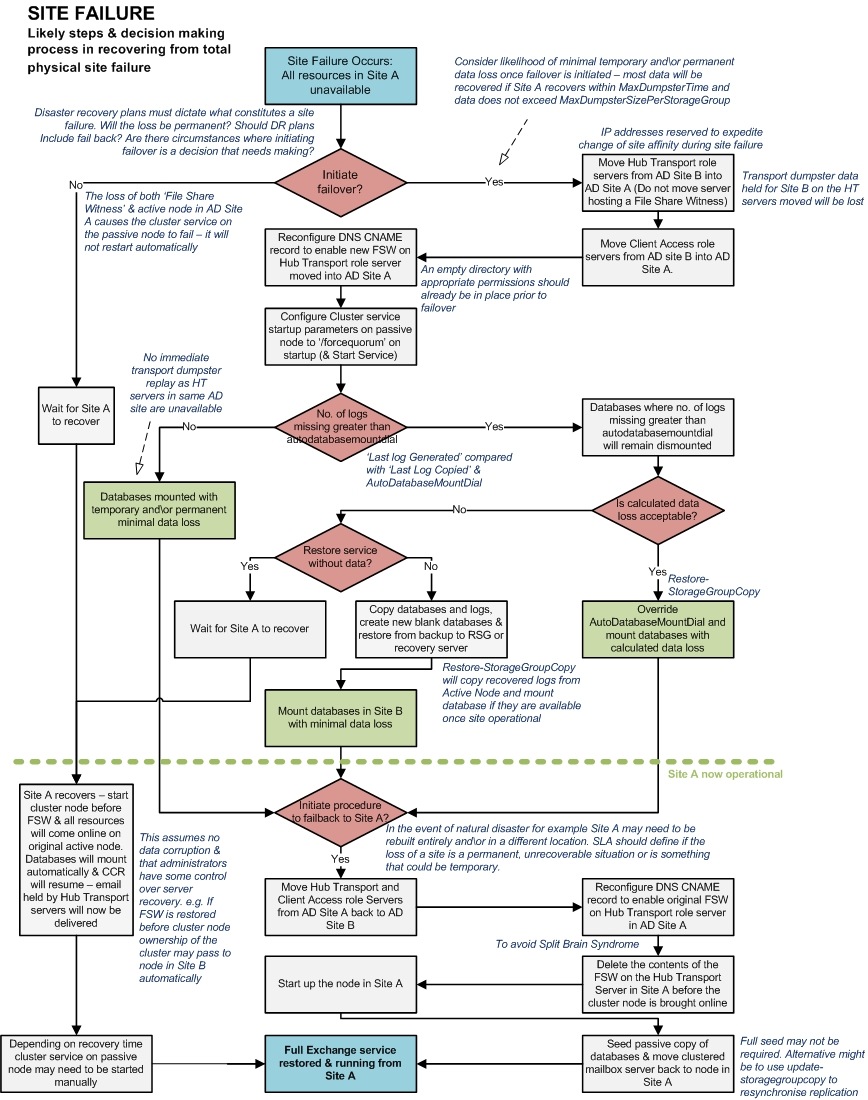
Total Site Failure - Likely steps & decision making process in recovering from total physical site failure
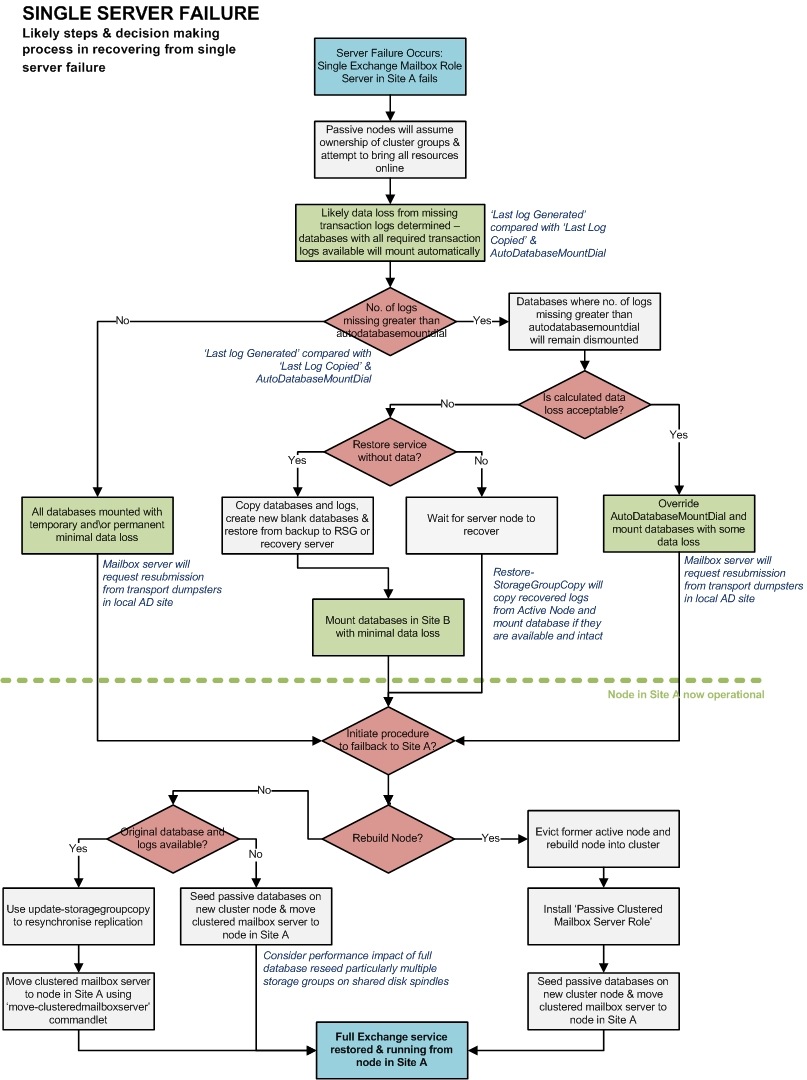
Single Server Failure - Likely steps & decision making process in recovering from single server failure
{kind=link}
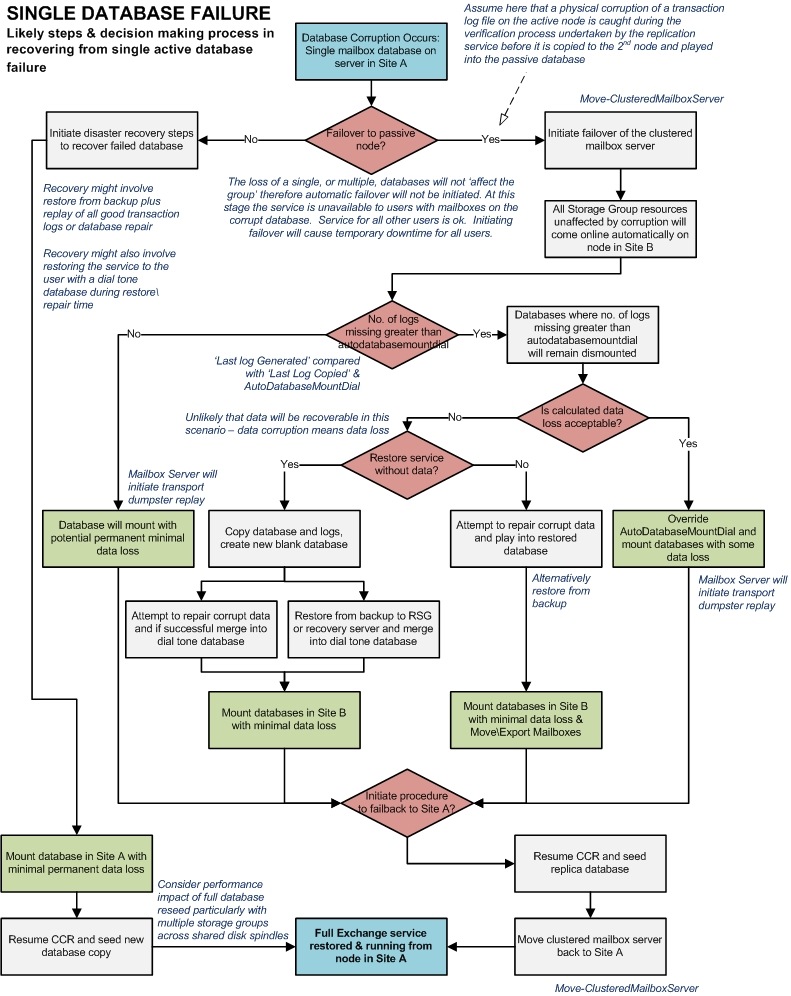
Single Database Failure - Likely steps & decision making process in recovering from single active database failure
{kind=link}
Of course with the introduction of Standby Continuous Replication (SCR) in Service Pack 1, CCR or LCR within the same physical site and SCR to the remote location might be a preferred solution. Even so it will still be important for administrators to understand what their recovery paths might be and what decisions will need to be made to properly control and expedite service and data recovery.