
Explore Azure Cosmos DB with .NET Core and MongoDB
Have you had to design general purpose “metadata” tables in your SQL database that basically store column names and values? Do you often serialize/de-serialize XML or JSON from your SQL tables to handle volatile schemas and data? .NET developers have traditionally worked with relational database management systems (RDMS) like SQL Server. RDMS systems have withstood the test of time and are production-ready. Like many tools, however, RDMS systems aren’t always the best solution. You may benefit from a different approach called NoSQL. Contrary to popular belief, NoSQL doesn’t mean “NO SQL” but rather “Not Only SQL.”
NoSQL comes in a variety of “flavors” but the most common are column, document, graph, and key/value.
Column databases
Column databases decompose documents into individual properties and store and index those properties. The column approach makes it possible to look up specific properties quickly in otherwise larger documents. Consider a document that looks like the following example:
The following document is a conceptual example of how the data will be stored:
Organizing the database this way improves the effectiveness of reads and writes, especially when only partial properties are being queried.
Document databases
Document databases store structures that are not tied to a specific schema. It is common to store data in JSON or a binary-optimized BSON format, but XML and other types of stores also exist. A major benefit of document databases is that you can store documents with different schemas and versions in the same location (called a collection). Just because the schemas vary doesn’t mean the data isn’t indexed. In fact, most document databases were built specifically to handle fast queries over large data sets. Document databases typically accommodate gigabytes to petabytes of data. Here is an example document that has nested entities:
Graph databases
Graph databases store relationships. The entities are referred to as vertices and describe the things being related. Relationships are referred to as edges and contain data about the connection. The canonical example of a graph database is airports and flight paths. Each vertex is an airport code, the name of the airport, and its coordinates. Each edge is a route between airports that contains information such as airline, distance, and average time. Graph databases can also be used to store genealogical data, hierarchies, and other types of relationships.

Key/value databases
Key/value databases are persistent dictionaries optimized for key-based lookups. The “value” may represent one or many columns and, like document databases, can have different schemas for each entry. If you often have the key, and are simply looking up information (such as loading user preferences or transforming a short code into a longer description) a key/value databases is ideal.
Enter Azure Cosmos DB
Azure Cosmos DB is a globally distributed, multi-model database. Cosmos DB provides the ability to elastically scale throughput and replicate storage across multiple regions. All of these benefits are possible with just a few clicks. Cosmos DB provides guarantees related to availability, throughput, consistency of your data and latency to access it. One way to think of Cosmos DB is as a serverless data platform stores your data and manages it like an experienced Database Administrator (DBA).
As a multi-model database, Cosmos DB supports several popular protocols and implements all of the common NoSQL patterns. Support for NoSQL databases includes:
- Column database support with the Cassandra API
- Document database support with the SQL and MongoDB APIs
- Graph database support with the Gremlin API
- Key/value database support with the Table API
Many of the supported APIs have been around for years and are used in legacy systems. By supporting these APIs, Cosmos DB makes it easier to migrate existing data to the cloud. It also allows you to tap into the existing ecosystem of community tools and drivers for those APIs.
Try Cosmos DB for free with no Azure subscription or credit card required.
The USDA Example
To help you get started with Cosmos DB, I created a simple cross-platform .NET Core application that uses the existing MongoDB driver. MongoDB is a very popular database with many existing implementations. It also has a very mature .NET driver available to both .NET and .NET Core. You can access the repository here:
Using .NET Core provides several advantages. The solution file is as easily opened and built from Visual Studio 2017 as from Visual Studio Code. You can build and run the project from your Windows machine, a MacOS, or even Linux. The project demonstrates how you can share code between traditional Web API projects and serverless function apps. It also uses best practices to pull connection strings from environment variables to make the connection.
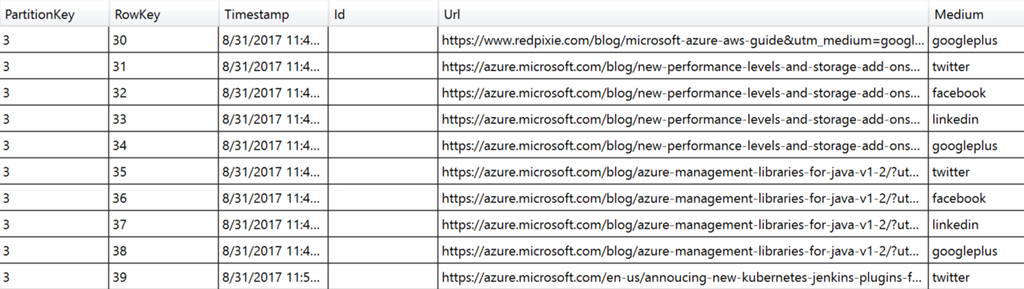
The usda-importer project parses files from the USDA database website and loads them into a document database using the MongoDB driver. The source database is a relational database with 12 tables.

The import project builds a set of domain objects that are natural C# classes you work with every day. It stores the data in just three collections: two to enable retrieving a list of food groups and nutrients, and a third that contains food items. The food item entries contain a list of weights used to measure them, and references to nutrients all in the same document. De-normalizing the content not only simplifies development but also makes the programming model more natural. Read more about the process here: JSON and the MongoDB Driver for the .NET Developer.

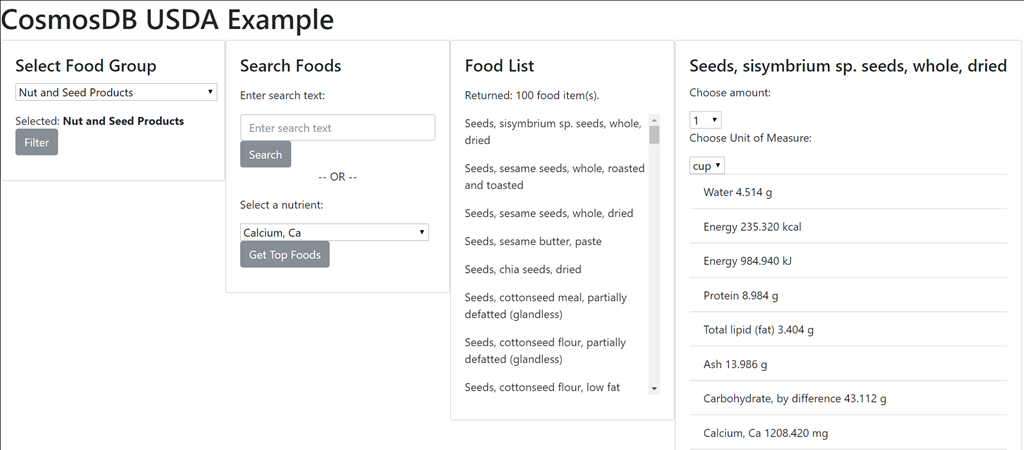
The usda-console-test project verifies the import when it is done. The usda-web-api project is an ASP. NET Web API project with endpoints that allow you to query the database. It lists food groups and nutrients and allows you to search for food items. You can also sort food items by nutrient content to answer questions like, “Which vegetables contain the most protein?” or “What nuts and seeds have the highest calcium content?”
Take a look at the following code snippet.
The example will dynamically sort foods by nutrient content (passed in as the tag). The projection ensures only the portions of the document that are needed are returned. The query limits it to a specific food group and takes the first 100 items. The code is all part of the MongoDB driver, and doesn’t require an additional ORM to map between the database and your domain objects. You can also query using LINQ.
Part of the power of Cosmos DB is that the engine automatically generates indexes as you store data. Queries are lightning fast. I almost always receive results querying the top 100 nutrients within milliseconds of submitting the request. Even text searches that look for strings inside the title or description return results quickly.
The usda-web-vuejs project contains a simple HTML document and JavaScript file. It uses the Vue.js framework to create a single page application (SPA). The application uses the Web API to query the database. You can open the file locally or use the included Dockerfile to build and run a Docker container. The repository contains all of the necessary instructions to get up and running. You will find most queries return results immediately from the application.
Summary
It is important that developers choose the right tool for the job. There is no rule that states you cannot use multiple data platforms in your applications. Every .NET developer should be aware of the NoSQL option. In many cases, it can simplify your application development by eliminating the need for an ORM. You also can store documents exactly as they are modeled in your application. Azure Cosmos DB makes it possible, and easier than ever, to create a highly available and reliable cloud database for your apps.
Click here to get started with the Cosmos DB sample.
 Light
Light Dark
Dark
0 comments