SQL Server: Impact of renaming the partitioned table on data
Hello all,
Recently I helped an application team to rename a partitioned table of a production database. The application team had questions around data availability when the table is being renamed and ensure that the existing data is intact even post renaming the table. In this blog, I am covering the scenario of renaming the partitioned table and switching the partition data to a newly created table.
Let’s get started.
For the purpose of experiment, let’s create a database named Partitiondb and create the partitions.
USE master;
GO
DROP DATABASE Partitiondb;
GO
CREATE DATABASE Partitiondb
ON PRIMARY(
NAME = partitiondb
, FILENAME = 'C:\TEMP\partitiondb.mdf')
,FILEGROUP partition_fg1(
NAME = partition_fg1
,FILENAME = 'C:\TEMP\partitionDb1.ndf')
,FILEGROUP partition_fg2(
NAME = partition_fg2f1
,FILENAME = 'C:\TEMP\partitionDb_fg2f1.ndf');
GO
-- Creating database Partition Function
CREATE PARTITION FUNCTION Partition_range (INT)
AS RANGE LEFT FOR VALUES(3);
-- Creating database Partition scheme
CREATE PARTITION SCHEME Partition_scheme
AS PARTITION Partition_range TO (partition_fg1, partition_fg2);
-- Creating a table to use partition
CREATE TABLE dbo.partitiontable( c1 INT NOT NULL CONSTRAINT PK_partition_table_c1 PRIMARY KEY CLUSTERED
) ON Partition_scheme(c1);
-- Partition 1 = {1, 2, 3}, Partition 2 = {4,5, 6}
INSERT INTO dbo.partitiontable(c1) VALUES (1), (2), (3), (4), (5), (6);
Properties of the table “Partitiontable” gives the partition details:
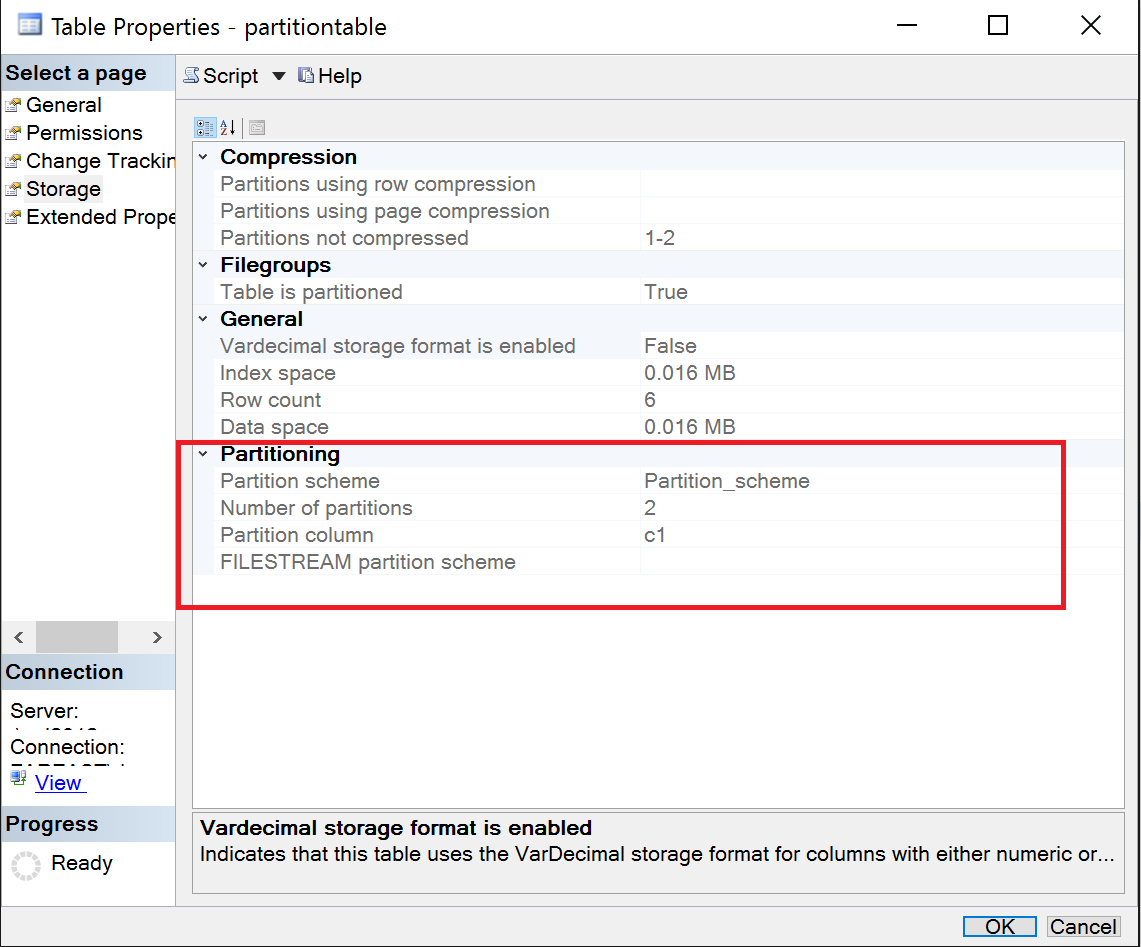
Figure 1. Partitiontable table properties
Alternatively we can also use the below query to fetch the partition details.
SELECT OBJECT_SCHEMA_NAME(pstats.object_id)AS SchemaName, OBJECT_NAME(pstats.object_id)AS TableName ,ps.name AS PartitionSchemeName, ds.name AS PartitionFilegroupName ,pf.name AS PartitionFunctionName
,CASE pf.boundary_value_on_right WHEN 0 THEN'Range Left'ELSE'Range Right'END AS PartitionFunctionRange ,CASE pf.boundary_value_on_right WHEN 0 THEN'Upper Boundary'ELSE'Lower Boundary'END AS PartitionBoundary ,prv.value AS PartitionBoundaryValue ,c.name AS PartitionKey
,CASE WHEN pf.boundary_value_on_right = 0
THEN c.name +' > '+CAST(ISNULL(LAG(prv.value)OVER(PARTITIONBY pstats.object_idORDERBY pstats.object_id, pstats.partition_number),'Infinity')ASVARCHAR(100))+' and '+ c.name +' <= '+CAST(ISNULL(prv.value,'Infinity')ASVARCHAR(100))
ELSE c.name +' >= '+CAST(ISNULL(prv.value,'Infinity')ASVARCHAR(100)) +' and '+ c.name +' < '+CAST(ISNULL(LEAD(prv.value)OVER(PARTITIONBY pstats.object_idORDERBY pstats.object_id, pstats.partition_number),'Infinity')ASVARCHAR(100))
END AS PartitionRange ,pstats.partition_number AS PartitionNumber ,pstats.row_count AS PartitionRowCount ,p.data_compression_desc AS DataCompression
FROM sys.dm_db_partition_statsAS pstats
INNER JOIN sys.destination_data_spacesAS dds ON pstats.partition_number = dds.destination_id
INNER JOIN sys.data_spacesAS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemesAS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functionsAS pf ON ps.function_id = pf.function_id
INNER JOIN sys.indexesAS i ON pstats.object_id= i.object_idAND pstats.index_id = i.index_id AND dds.partition_scheme_id = i.data_space_id AND i.type<= 1 /* Heap or Clustered Index */
INNER JOIN sys.index_columnsAS ic ON i.index_id = ic.index_id AND i.object_id= ic.object_idAND ic.partition_ordinal >= 0
INNER JOIN sys.columnsAS c ON pstats.object_id= c.object_idAND ic.column_id = c.column_id
LEFT JOIN sys.partition_range_valuesAS prv ON pf.function_id = prv.function_id AND pstats.partition_number =(CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1)END) WHERE pstats.object_id=OBJECT_ID('partitiontable')
ORDER BY TableName, PartitionNumber;

The above output confirms that there are 2 partitions created with 3 rows in each partition.
In the scenario that I worked, the application team wanted to create a new table with exact schema as that of “Partitiontable” and rename the production table and make the newly created table as the production table.
Using the script table option, we generated the schema of the table Partitiontable. The generated script, however doesn’t give details of the partition schema the table is using:
USE [Partitiondb]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Partitiontable]( [c1] [int] NOTNULL,
CONSTRAINT [PK_partition_table_c1] PRIMARY KEY CLUSTERED ( [c1] ASC)
WITH (PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)
GO
The next step is to rename the existing production table as Partitiontable_old
sp_rename [partitiontable], [partitiontable_old]
If we execute the generated create script directly, we will encounter the below error.
Msg 2714 ,Level 16,State 5, Line 11
There is already an object named 'PK_partition_table_c1'in the database.
Msg 1750 ,Level 16,State 0, Line 11
Could not create constraint. See previous errors.
So, the Create table need to be modified as below :
USE [Partitiondb]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[partitiontable]([c1] [int] NOTNULL,
CONSTRAINT [PK_partition_table_c2] PRIMARY KEY CLUSTERED
( [c1] ASC) WITH (PAD_INDEX=OFF,STATISTICS_NORECOMPUTE=OFF,IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS=ON,ALLOW_PAGE_LOCKS=ON)
) ON Partition_scheme(c1);
GO
Using the above script, we successfully created the new table. Now when we check the new table created it will have the partitions intact. The only difference in the below output is that the PartitionRowCount is 0 for the newly created table.
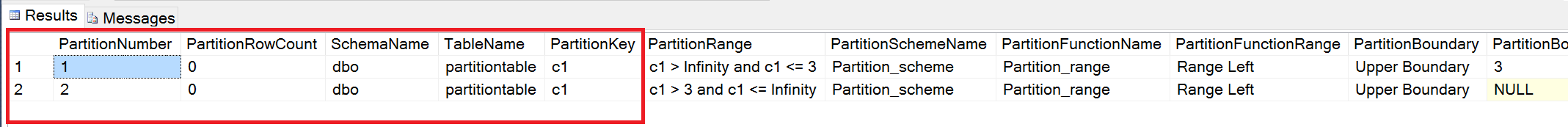
Executing the same query on the Partitiontable_old gives the below output:

This indicates that even after renaming the table, the partition data is intact.
We can migrate the data from the old table to newly created if needed using Partition switch option. The below query switches the partition 1 from old table to new table.
ALTER TABLE Partitiontable_OLD SWITCH PARTITION 1 TO partitiontable PARTITION 1
Post partition switching, executing the query which fetches the partiton information, gives the below output for the new table Partitiontable. Note that the first partition has 3 rows indicating successful partition switching.

Before Implementing the solution on the production server, testing the solution on pre-production server is highly recommended with your table schema.
I hope that the steps in this blog were useful and saved you time.
Reference:
Transferring Data Efficiently by Using Partition Switching
https://technet.microsoft.com/en-us/library/ms191160(v=sql.105).aspx
Please share your feedback, questions and/or suggestions.
Thanks,
Don Castelino | Premier Field Engineering Team | Microsoft
Disclaimer: All posts are provided AS IS with no warranties and confer no rights. Additionally, views expressed here are my own and not those of my employer, Microsoft.