Compressing messages in WCF part four - Network performance
The aim of compressing the messages sent from a WCF service is to reduce the amount of traffic on the wire. You could be doing this because you're in a hosted environment such as a cloud service and you have to pay for bandwidth. The tradeoff for compression is an increase in CPU usage. In this post, I will examine exactly what that means.
The test environment is shown in the following diagram.
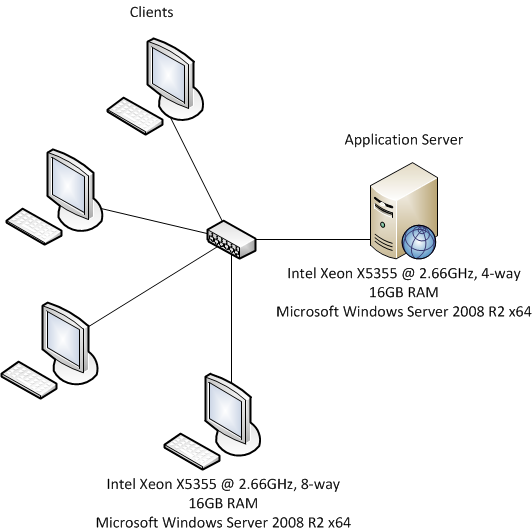
The server is a single processor quad-core and each of the four clients are dual processor quad-core. This is done so the four client machines can easily push the server to 100% CPU before hitting bandwidth limitations. Each machine has a 1Gb NIC. The network is isolated.
For this test, I'm using the same test code that I used in the previous post. This means that the client sends a small request containing an integer n. The service responds with a collection of n Order objects. In the previous post we saw that Deflate has a slight performance advantage over GZip because of the time required to create the CRC. We'll see if that difference becomes smaller or larger in this environment.
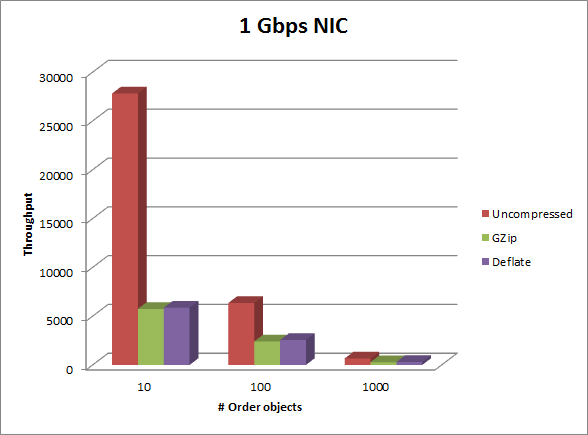
| # Orders | Uncompressed | GZip | % diff | Deflate | % diff |
|---|---|---|---|---|---|
| 10 | 27810 | 5746 | 79.34 | 5864 | 78.91 |
| 100 | 6357 | 2411 | 62.07 | 2555 | 59.81 |
| 1000 | 666 | 290 | 56.46 | 306 | 54.05 |
To be clear, these numbers are operations per second. Each operation is a request and response.
You can see that the effect of compression on throughput increases in this environment. But in this case the server has a 1Gbps NIC so the only bottleneck is the CPU. What would happen to these numbers if we were to change that to a 100 Mbps NIC? This would make network bandwidth the bottleneck. The table below shows what happens in this case:
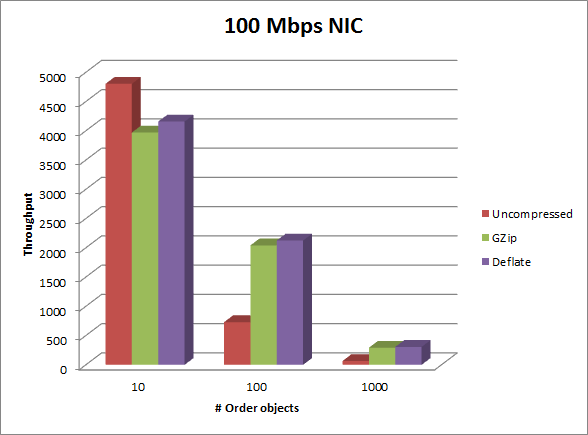
| # Orders | Uncompressed | GZip | % diff | Deflate | % diff |
|---|---|---|---|---|---|
| 10 | 4804 | 3971 | 17.34 | 4158 | 13.45 |
| 100 | 730 | 2042 | (179.73) | 2125 | (191.10) |
| 1000 | 67 | 293 | (337.31) | 307 | (358.21) |
Here we can see that as the messages get larger, the benefit of compression increases. The most interesting thing to note is that for the 1000 Order case, GZip and Deflate throughput numbers are the same because of the CPU bottleneck. But without compression, the standard transport suffers greatly, dropping to 1/10th of its original throughput.