Designing for Resilience in n-Tier applications (part 1)
The n-Tier headache
The huge growth of the Multitier application architectures has drastically changed the way we envision, develop and support software solutions. The notions of greater scalability, reutilization of services and independent software developing processes are concepts that play a fundamental role in the IT world. Keywords like SOA, Cloud and n-Tier are basic lexicon of developer teams today and while the technology approaches may vary, there are a lot of common challenges that the IT crowd has to face in this brave new world.
Software development frameworks have evolved a lot to simplify the task of developing n-tier applications (look back at SOAP toolkit and look where we stand with WCF today) but, generally speaking, the development process has become much more complex. The applications we build can no longer be encased in a single executable which we can control from the ground up. Instead, our solutions are usually built around the concept of distinct pieces of software that integrate between themselves and provide well defined interfaces which can be used to further extend our applications.
The advents of cloud computing, which is becoming more and more a common trend in today’s architectures, will up the bar once more for all of us who have to design, develop and support software solutions. For guys like me, who spend a considerable amount of time helping MS customers troubleshoot and solve problems in their applications, the n-Tier model drastically “ups the game” in terms of the tools we need and the processes we must use to understand what is wrong, to troubleshoot issues and to come up with solutions. Debugging and pin-pointing problems was never a simple task, but is becoming more and more complex as the software industry adventures further in this path.
Tier Dependency Performance Issues
One of the most common problems that we face as support engineers is performance issues. Usually, the problem is explained to us as the application being “slow”, “hanged”, “crashed”, “stopped”… well, you name it really! Depending on who’s talking to you and the amount of information gathered about the problem, usually our first task is determining what are the correct symptoms, which many times it’s a challenge on its own.
One fairly common case is what I usually refer as “Tier dependency performance issues”. For the sake of keeping our model simple, let’s assume we have a simple web front end application hosted in a server. This application makes WCF calls to a service hosted on a backend server and this service interacts with the database.
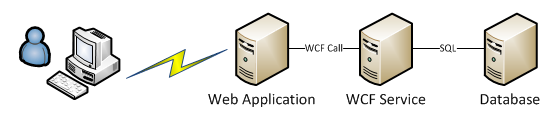
Users report that the application is “slow” or “hanged”. Typically, fingers are pointed at the web front end application because that’s where the symptoms become visible to users. But in fact, the problem may be in the services tier or even at the database. So where do we look first? There is no good answer to this. You might get lucky and get it right the first time but usually this is not the case. So, it’s an iterative process where you start discarding tier after tier until you pin-point the problem to a specific one (or in some cases, more than one).
There are many techniques we can use to determine this, from performance counters to memory dumps, but this post doesn’t aim to detail the troubleshooting steps required to successfully identify problems in nTier systems.
Let’s assume our issue is indeed at the database level, where we are performing some queries that are simply taking too long to execute. The services tier methods are therefore taking longer than expected to complete, so the web pages in the web front end application also load slower than usual because they have to wait for the WCF calls to complete. Makes sense right?
It’s really quite simple when you think about one single request that traverses all tiers in this system, but because we are talking about a web application in the front-end, we may run into some tougher situations to diagnose.
Let’s assume, our ASP.NET web application is under heavy load when the problems in the database start to happen. Hundreds of users are hammering the server with Http requests and everything is going on as expected. For each request that comes in, ASP.NET will choose one thread from its thread pool and assign it to handle the request (these are called worker threads). However, this particular request will need to perform a WCF call to our services tier, and this call will take a lot of time to complete (maybe even timeout, but we will get to that later). While the thread is waiting for the WCF service to deliver a response, this thread is unavailable to serve other requests and the user that originated the initial request is still waiting for a reply from the web server.
In the meantime, however, hundreds of other requests arrived at our web front end application and most of them will also need to access the services tier. ASP.NET will handle it as usual, assigning one thread from the thread pool to each request until it has no more free threads available. All the threads will be waiting for the WCF calls to complete so it’s really easy to reach this situation under heavy load if one of your backend tiers is suffering from poor performance.
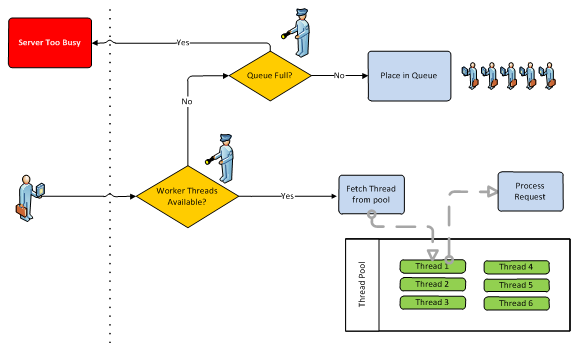
ASP.NET uses a queue in order to avoid refusing requests immediately. Any incoming requests are then placed in the queue hoping that one of the worker threads assigned to a previous request finishes what it has to do and returns to the thread pool. You can think of it as a gate that is closed at the ASP.NET level, but newcomers stick around waiting for it to be lifted again.
But if the WCF calls don’t start returning any time soon, or the rate of new requests is too high, the queue will eventually fill up and the application will refuse any incoming requests with the message “Server too busy”. And I’m guessing most of you have seen this dreaded message some time in the past right?
This message usually raises a lot of warning bells and whistles about the performance of the front end server, but as you can see, the problem may reside in a completely different place (or tier).
Resilience
The simple example we just described illustrates one of the common issues we see in n-Tier applications and is deeply tied to the notion of resilience. Although tiers are built to be independent, the truth is a bit trickier than that. Unless we implement some resilience mechanisms on our application, a tier will be dependent on the performance of the next tier and so on.
Resilience should be thought of as the ability for an application to react to problems in one of its components and still provide the best possible service. I’ve seen many customers that take a very loose approach to this topic and just decide to accept that if one of their pieces is behaving badly, the whole solution is not going to work, provided they have the processes in place to solve the problem quickly. Usually, this decision is not made because they feel comfortable with it, but because the solution was not designed with resilience in mind in the first place, and the effort and cost required to change it is too high.
If we take the time to build our applications with resilience in mind, we can avoid most common hang symptoms and create a more reliable and stable solution. As I was discussing this topic with some colleagues at lunch the other day, we thought it would be interesting to raise a more deep discussion around this complex subject, so I took the initiative of laying down the problem and hope for the rest of the team to jump in the bandwagon with their views and knowledgeable input, and see how far we can go.
Before we get started, let me clarify that there is no perfect answer to this problem, although we can think of a few mechanisms that can reduce the impact of these issues. This series of post is not intended to provide you with an all-around solution, but mostly to raise some awareness to these issues and hopefully illustrate some common approaches that we see in the field and that can help you build a better experience for your users and your IT department.
What about asynchronous?
When you know beforehand that some operations will always take a lot of time to complete and the nature of the requests allows it, the good choice may very well be to implement asynchronous calls. In an asynchronous world, any calls between tiers are replied to immediately after receiving the request and the actual work is done later on.
These mechanisms are resilient by definition, in the sense that we will not hurt the performance of front tiers if we run into problems in one of our backend servers. Even if the database becomes unavailable, any work items that were received are being stored and waiting for a chance to complete. The request that originated the work item is long gone and we didn’t fill up our server with requests that take a long time to finish. In the Microsoft world, Biztalk Server is often used for these scenarios.
However, asynchronous design is not the perfect solution for all applications. Looking at our example, where we are using an interactive web site as our front end application, this is not an option. We are talking about actual people using a web browser. Each request is expected to complete fast enough for the user to see the result (usually a web page). Even if we implemented an asynchronous model where we reply with enough information to build a page, and done some AJAX magic to allow the browser to check for completion of the request, the user may very well give up before the request gets completed.
Interactive applications have to deal with a factor that is very hard to measure: user patience. It is frequent that we see users hitting refresh very often when a page takes long to complete, which just contributes to make our problem bigger and to cause even more load on our application. The main problem about building a fully asynchronous application in this scenario is that you are not truly in control of your whole solution. That little piece called “the browser“ has its own rules of engagement which you can understand and prepare for, but you cannot change to suit your own needs as a software developer.
Aren’t timeouts supposed to solve this problem?
Timeouts can be thought of as resilience helpers if you want, but they do not provide a complete solution. It’s very typical that someone in your IT department will come and suggest you either increase or decrease your timeout in order to “solve” the problems in your application.
Let’s take a look at how changing the timeout values can affect our scenario. Let’s assume our timeout for WCF calls is set at 10 seconds, and because the database is currently slow, the calls are taking around 25 seconds to complete. Should we raise the timeout to 30 seconds? Sure that will cause our requests to complete but will it solve our problem? In fact it will worsen it: the worker threads from our web application will sit around waiting even longer and the chances of the queue filling up and we start refusing requests is much bigger. Also, your users will probably not sit around waiting for 30 seconds and will therefore hit refresh which means that they will not see the answer to their original request and they are starting over causing one more request to pop up at your server’s gate.
Let’s now assume that our timeout is set at 30 seconds and you are experiencing hang symptoms due to bad performance from the database. Should we decrease the timeout in order to alleviate the symptoms in our web server? Well, that will cause a more efficient handling of requests but you have to be careful to make sure you provide enough leeway for your application to work. So, you may run into a situation where you don’t really hang, but your application is not actually doing anything relevant. For the sake of argument, let’s say we reduce the timeout to an unrealistic value of 2 seconds. Sure, you will not run into hang issues because the ASP.NET worker threads will return to the pool very fast but you can run into some grim situations this way. Let’s say this is a home banking solution. A request for a transfer comes in, your application calls the WCF service to complete the transfer but gives up after 2 seconds and informs the user it has not completed. Meanwhile, your WCF service already issued the SQL operation that will decrease the current user account’s balance. Fun times right?
This shows that timeout are not a full solution. Sooner or later you will run into a situation where your timeout value works against you. So, this raises an important question: how should we set our timeouts?
As a rule of thumb, timeouts should be enough to cover the time needed for your calls to complete when everything is working as intended PLUS some added margin for small hiccups that can occur in your application or servers. Because the exact value is difficult to predict, you should regularly monitor your application and server’s performance and log every timeout event, so that you can reach a more accurate value.
Timeouts, however, are not meant to be raised or lowered as a way to solve performance issues when you are facing them. At best, they can hide the problem, but then you are not actually treating the illness, you are just curing the symptoms.
While we can think of timeouts as something that will help us react to performance problems, by itself it won’t do much if your application is not prepared to understand that a timeout occurred and treat it as something different than any other exception. Yes, the solution to this type of performance issues actually resides on detecting and handling timeouts, but if all you’re doing is logging it and sending an error message to your users, it won’t be enough in most cases to make your application resilient.
Reacting to timeouts
Let’s look at how we would like to react to timeouts.
Option A – Log it!
The bread and butter of error handling, the most common approach out there. It timed out, let’s write something in the event log and inform the user that something went wrong. The user will try again, so will the other hundreds of users you have in your application currently. Your application will keep trying to access the service every time it is requested to do so and it will probably keep failing. Granted, this might be enough in most cases but if your user load is high, you will run into the hang symptoms we covered in our scenario.
All worker threads will be waiting for service calls to complete and the queue is filling up. As an added “bonus”, requests that would not involve service calls are also not being handled because there are no threads available to service them. So essentially, you are preventing all requests, even simple ones, from executing because you’re application doesn’t keep track of the state of each service, and therefore always tries to complete every single request.
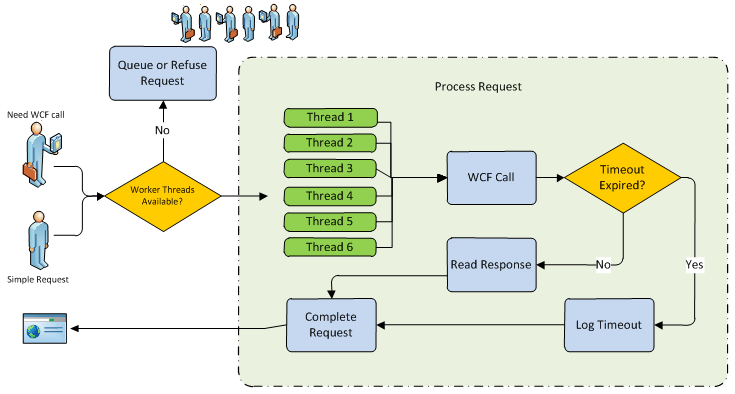
Option B – Log it and remember it!
If a call to a service timed out the last 3 times it was called, there is a very good chance that it’s going to timeout a fourth time. So, is there a point in keep trying until the problem is fixed?
Wouldn’t it be interesting if the application, armed with the knowledge that the service is having performance problems, could inform the user that that specific operation is not currently available right now and avoid calling the service until it knows the problem is fixed? How would that help us?
You can think of it as an additional gate in your application that prevents making the WCF call if the service is flagged as unavailable or offline.
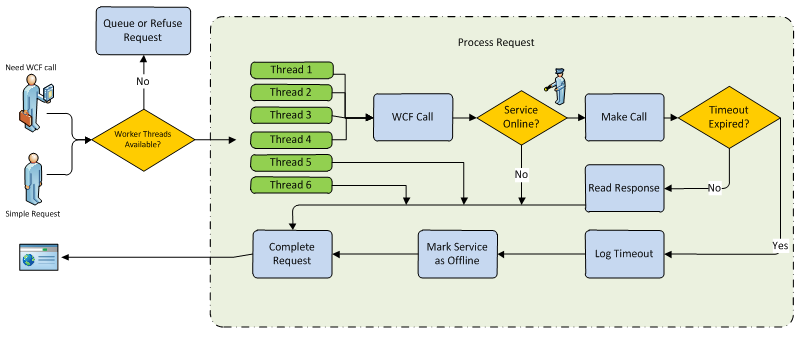
Looking at the diagram, we can spot some benefits to this approach. Let’s assume the “Mark Service as Offline” task checks a global retry counter of some sort, finds out it has been reached, and decides it will mark the service has being offline (loose term meaning that the service is not giving timely responses).
From then on, until the service is marked as online again, all requests that require a WCF call to that service will be replied to immediately, because the application makes an assumption that the call will not return in due time and as such it does not attempt to query the service. That means that we provide a fast response to the users of our application and we won’t leave the thread hanging, waiting for an answer that probably won’t come.
So, even if we already started to have some queuing (depending on how we check and set the retry counter), all threads will start to execute fast, meaning it will be less likely that we suffer from exhausting the thread pool, queuing or refusing new requests with the “Server too busy” message. Also, we don’t stop the application as a whole from working because all requests that do not require a WCF call will have free threads to process them and they will complete as expected.
If we make this very granular and keep track of the state of all the services we call in our application, we can make sure that one rotten apple will not spoil our lunch as the application will keep working and it will even perform WCF calls to all services that are working as intended.
Next Step
Obviously this introduces more complexity into our application logic and raises a few good questions:
1. How do I keep track of the state of the service?
2. Should I complete the request be telling the user to try again later or should I store the operation locally and try to finish it when the service is back online? What are the drawbacks of each approach? How do we handle user interaction in each case?
3. How do I recover from this? Meaning, when we are no longer experiencing problems in our service, how does the application find out?
In the next post of this series we will see how we could accomplish this and how to deal with the complexity involved. We will start with a very simple model and hopefully we will expand the series to build on that example and provide some more advanced alternatives that can be tailored to a wide spread of resilience and performance requirements.
Until then, have fun!