Automating Windows as a Service
Bold lines are important. Blue lines are most important. (read with care) TL;DR; at the end - if you need it.
Hello together,
first of all I need to apologize again for the length of this blog post, but I personally think that the following topics need to stick together to be understood into depth and I don´t want to leave any chance for missunderstandings.
It took me some time (100h+) to create this article and it will take probably some time to read it.
But before you continue reading you should be aware of Windows as a Service and what really stands behind it.
(if not read Demystifying Windows as a Service – wake up! please and Update to the Windows as a Service Model)
I will start with a short intro and some theory - moving on to the procedural automation and to technical adoption in theory and finally to technical adoption with automation.
Disclaimer:
I´ve received so many negative feedback regarding WaaS after my previous extensive article and I have heard so many times that WaaS is so extremely complex and no one would ever be possible to adopt this in any way. First - nearly all of the topics, which I am speaking about, are mandatory know-how - either regarding to Project Management, ITIL, ALM, Security Management (updates) or obvious technical background. I am actually not explaining something new - I am only explaining how professional IT can and should be adopted. The answer is - professional.
I am also writing this as a private person, who thinks that DevOps is not only a buzzword. I see a huge need to show a theoretical approach for automating WaaS and also to show a technical Proof of Concept - otherwise it seems that no one will ever believe me.
By writing this article as a private person you might also recognize that I am doing this in my free time. (having not too much of it!)
Introduction
WaaS is not something "Microsoft-special" and nowadays there is this cruel necessity to keep up the pace and adopt the newest technologies just in time. With WaaS this is accomplished for the Operating System, where by speaking of the coming "new wonderful Features" we are mainly speaking about Security and Administration Features, which are increasing the Clients´ Security with hardening. Additionally we introduce new technologies like Windows Hello for Business with Companion Devices, Exploit Guard, Application Guard and later on also features using Artifical Intelligence on or with the OS like Advanced Threat Protection and even the Antivirus.
I see companies grumbling about this change, but this is just a kind of Digital Transformation. There is no time anymore to release new Operating Systems manually every 3 to 5 years.
I love to quote Jeffrey Snover: “If you want to fail in a transformative change just treat it as an incremental change.”
Video from PSConfEU 2017 - 13:10 ff. MUST see.
Theory
First of all I want to clarify our latest changes to make sure, that everyone is on the line. WaaS is an always recurring process in identical time frames as shown in the following picture:

One OS is supported 18 month. You will always have around 6 months between each OS release.
So you know when specific OS Versions are in Insider Preview, get released, become ready for broad deployment and when they run out of support. Always.
Michael Niehaus consolidated this vast information and complexity in its latest blog article.
It is probably the shortest article ever and he is right. This is the main information.
Everything else, that I am describing and explaining is just:
- how to do it professionally
- how to save time in the future
- and the most important one: how to do it structured!
Lets start by diving into a more detailed view:
The latest changes result into completely predictable time frames, which you should simply address in a recurring manner.
So - what has to be done for one specific OS Version?
Michael separated this into 3 phases (see here ), which makes it very simple to understand - and you should be aware of these 3 phases:
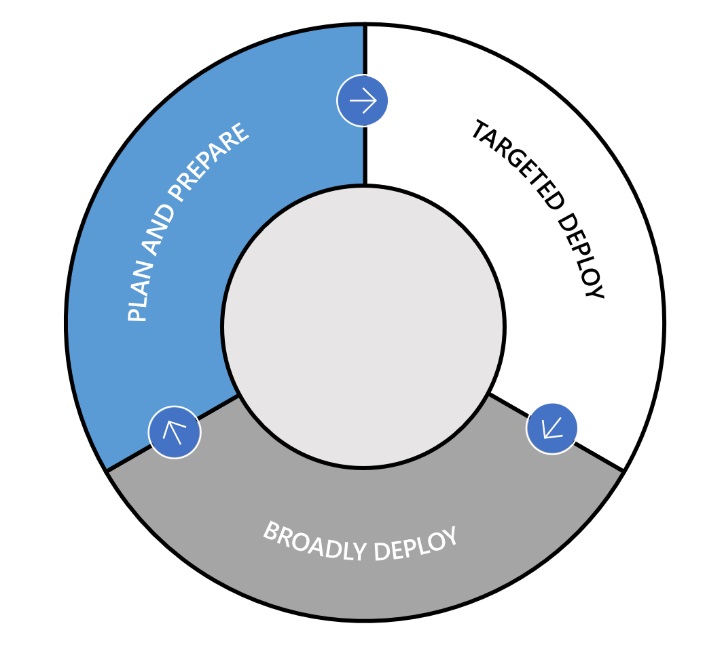
- Plan and Prepare. Leverage the Windows Insider Program to follow along with the development of new Windows 10 features (so that you can prepare to deploy those features), while at the same time validating compatibility and providing feedback on any issues or concerns.
- Targeted Deploy. Starting as soon as a new Semi-Annual Channel feature update is released, begin targeted pilot deployments to a targeted group of machines (we typically suggest around 10%) to validate app, device, and infrastructure compatibility.
- Broadly Deploy. Once you are satisfied with the results of the pilot deployments, begin broadly deploying throughout the organization. For some organizations, broad deployment can begin quickly; for others it can take longer. It is up to each organization to determine when to make that transition.
(see here)
As a result of this we will now dive deeper and take a detailed look for one specific OS Version - for example Windows 10 1803 - starting from Insider Preview up to its end of life and what has to be done in each time period.
Granular View for one Release:
[video width="800" height="1080" mp4="https://msdnshared.blob.core.windows.net/media/2017/08/WaaSArticle2.mp4"][/video]
The video ends up in this slide and demonstrates the transition from the specific acronyms and timestamps to fully understand the model and how all the time frames are actually working together:
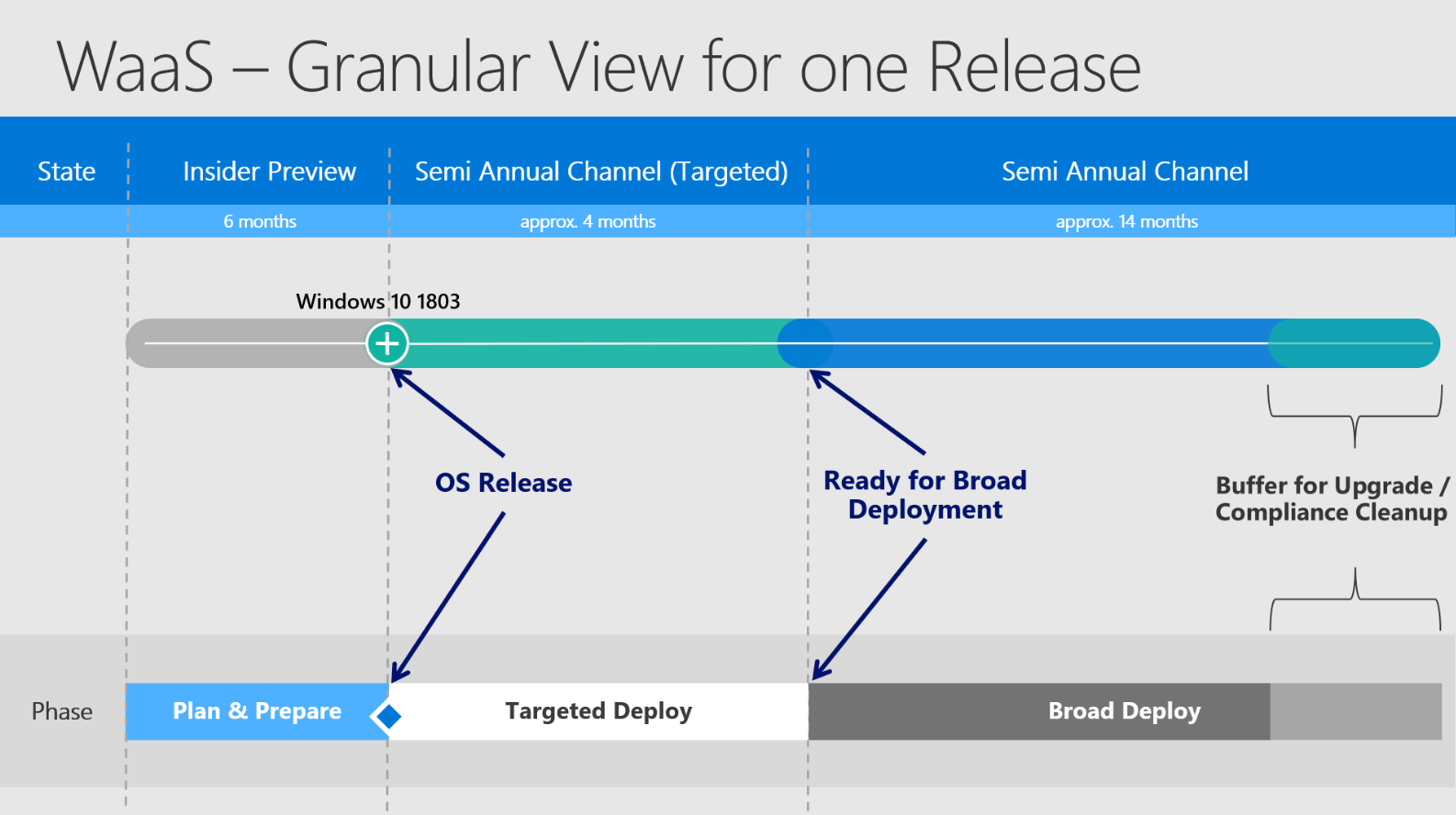
Starting from left to right you see the different states of the OS Version. Starting in Insider Preview and then becoming finally available in SACT - moving on to SAC and finally moving out of support.
The timestamp when a release finally becomes officially "Ready for Broad Deployment" may vary to different circumstances like feedback from Premier Support, feedback via Feedback Hub, feedback over Telemetry and also internal feedback. But as mentioned in my last article - it does not affect the general support time of 18 months.
Legend:

Also some more detailed words to the "Buffer for Upgrade":
Buffer for Upgrade = Compliance Cleanup = a defined time buffer, which is placed at the end of broad deploy to make sure having some time, if something does not work as desired and to target computers, which were not able to upgrade by any means. This ones need to be addressed specifically and therefore the naming "Compliance Cleanup" is used.
This was actually everything, what changed. Only names. Nothing less, nothing more. Now let´s continue and move from Theory into the Procedural Adoption.
Procedural Adoption
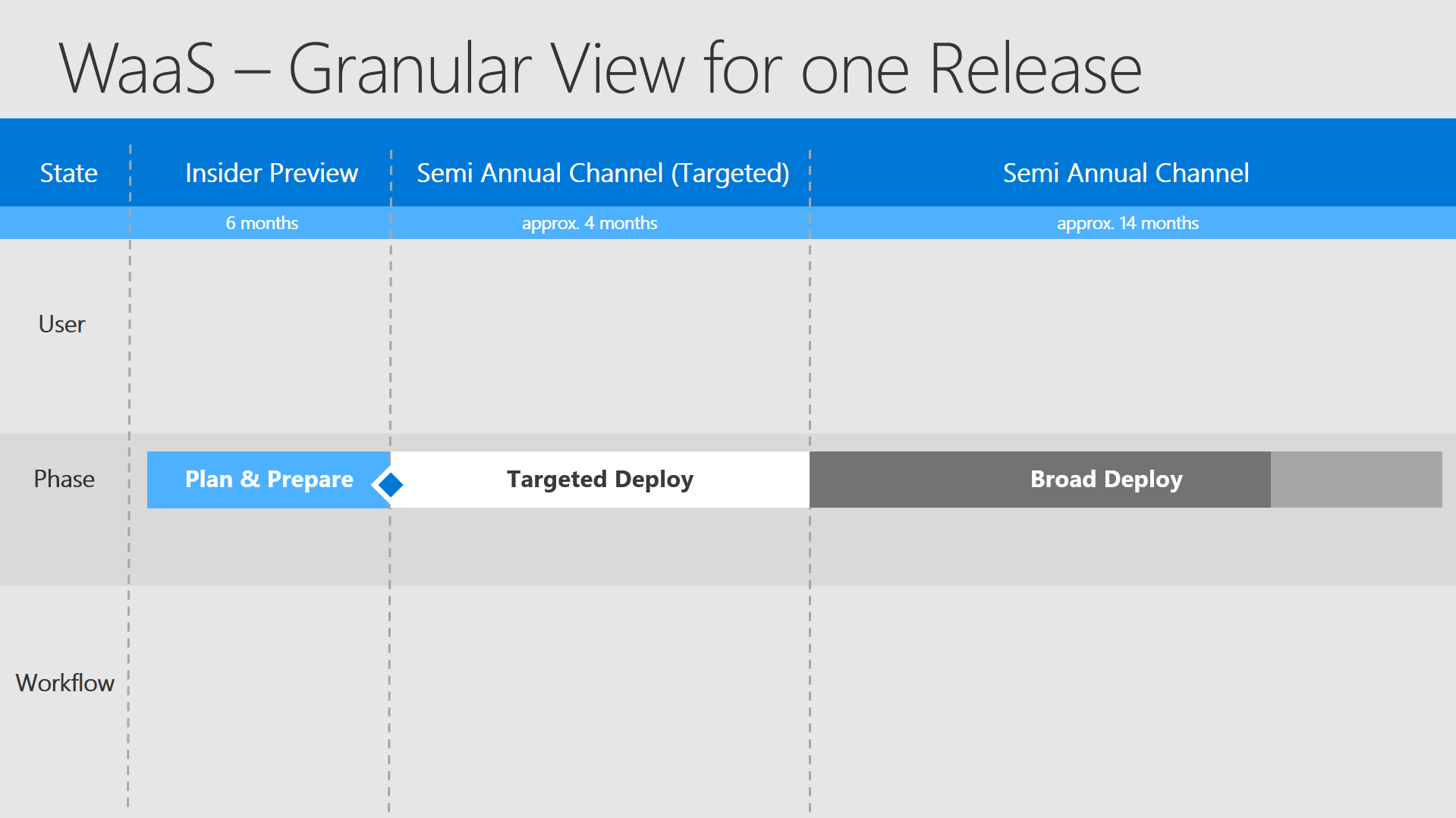
Speaking in times:
- around 6 months Insider Preview
- 18 months supportability
- consisting of approx. 4 months SACT
- and approx. 14 months SAC
- evaluate 10 months for broad deploy
- and 4 months for Compliance Cleanup and Buffer
This slide will show you what "User"-group (team/persons) has to accomplish which "Workflow" (tasks / processes) in which defined "State" (timeframe):
- State - predictable timeframe regarding the specific OS Version. Due to the fact of the OS releases in March and September every timeframe can be defined pretty exactly.
- User - a group of persons / a team / a outsourcer who has the lead for the defined tasks in this timeframe
- Phase - one of the 3 known phases to divide the OS deployment - for better explanation: Plan & Prepare, Targeted Deploy, Broad Deploy
- (scroll down) State 2 - Separation of the working tasks into Proactive Testing, Reactive Testing & Production and Upgrade
It describes what the approach should be at the shown timeframe. You start in Proactive Testing to set up the configuration and test LoB apps, but also moving in your internal first tests. In Reactive Testing you deploy your upgrade to dedicated machines (starting with small numbers) to find any incompatabilities, which were not identified without causing a high impact.
By defining small numbers and well chosen computers you predefine the possible impact and completely control your testing approach.Afterwards you move fluently into Production and at the end upgrading special or very sensitive machine. (VIP, industry computers, etc.) - Workflow - Defined work tasks that have to be accomplished in the current time frame.
You predefine the upcoming processes and because it is completely predictable you are able to set up a detailed recurring project plan! Let us go through each State in detail to discuss the Workflow and the specific "User"-group.
Plan & Prepare

In this timeframe we now define our phases by our events - so we have the "Plan & Prepare" phase , where you start the first preparations for the upcoming OS version. The most important steps here are to test the most important LoB apps and to validate the new features. Regarding the new features you have to make the decision, if you want to use it and also to take a look at the prerequirements and including these tasks into your internal roadmap. Additionally you should also take a look at closing, deprecated or removed features, which might affect you. It is also a good idea to test the inplace upgrade itself - does the computer with a bunch of software installed on it still upgrade as intended? Are there any modifications made to the computer, which need to be addressed after the upgrade? For the first releases every customer is doing this process manually. Why? It was ever done this way and there was no need to change this. But now coming with updates every 6 months this won´t be possible anymore. So you should start building a procedural and technical workflow which addresses all recurring and automatable tasks completely.
Targeted Deploy

The "Targeted Deploy" is initialized by the official release and it is the most complicated phase and I will explain you why. The first things you need to achieve with the released version is to get everything ready for the broad deployment. This means that you have to create GPOs, enabling new features, making some modifications to configuration, CI or even other technologies and so on.
So you want to have some test/dev computers where the new release is just installed on as soon it is published. This should be done via Inplace Upgrades, because you passively just test, if the technical upgrade process itself works well and how the computer looks like after this upgrade. The project team (for probably new features) and the IT department can now set up the whole configuration and test on these dedicated machines. As you see - we have a defined collection of computers which should be upgraded automatically after this event (the release of the new OS Version). This task should take as less time as possible to push out the first testing rings.
Testing rings? You want to deploy the new OS as fast as possible to a small but very representative number of computers. The very first testing rings should include mostly IT-people which can handle small problems and give good feedback to - for example - missing GPOs or additional fixes which have to be made after the inplace upgrade. You want also to test applications in this phase - as you see in the picture I have mentioned the Application Holder and the App Test Users. While the configuration is evolving to its finish the first rings targetting the applications should start firing. And here it gets tricky - it´s not only about applications - there is much more that should be taken into consideration:
- Applications
- Organizational Units
- Network Segments
- Geographical Locations
Applications are pretty understandable. Who are the best testers? People who actually work with the software products. So you want to deploy as soon as possible the new OS version to people working with applications - BUT - you don´t want to have an huge impact. So you start with very small numbers trying to target ALL applications. It would be great if you upgrade a number of computers with all existing applications installed on it at least once.
Why Organizational Units? OUs are very similar to the transversal cut through all applications. There are some applications which only are used in specific teams, which at many customers are managed in specific OUs. Additionally to this you want also to test all different GPOs and don´t want to find some coincidences too late coming from specific settings and creating unusual errors.
Why Network Segments or Geographical Location? Actually you know the answer - you don´t want to find network-related errors too late for a whole building or even region. A great benefit by doing this - you create indirectly caching points in the whole field. For example - if you have 10 buildings and 100 machines in each building (depending on the technology for sure) the devices will reach out for the feature updates in the same building or even NAT. Therefore the best strategy would be to upgrade in the first place one computer for each building and then increasing this number step by step. Even if machines are offline - there will be pretty fast the situation that you have at least one caching point sitting in each building.
As you see - there are a lot of benefits for this approach - but how can you adopt this technically und fully automated? This is where the "tricky" begins.
The combination of all these transversal cuts split up into some rings will be the hardest part to accomplish in the automation of WaaS. Setting up the collections for the rings with well-chosen computers is hard - but manageable. And the good thing - if you have accomplished this task once you will never need to do it again, because it will be automated! We will take a more dedicated look at some possible solutions later on in the technical part.
Broad Deploy

As you can see in the following image the Broad Deploy area is divided into 3 parts. The first two parts are considered the typical "Broad Deploy" - pushing out the upgrade in a high number into the field. The second ring of this two though will mostly focus on some special machines which should not result in problems by any mean. So they will be deployed in the timeline rather late to have run through a vast amount of proactive and reactive testings before. And in the last region the computers become uncompliant.
Why?
In IT you should always calculate with time buffers. Therefore you should move your upgrading target date to around 4 months earlier, before the client itself gets out of support. So you would try to place all your upgrades between Insider Preview up to 2/3 of Broad Deploy (SAC). Then you can define a precise task for Compliance Cleanup, which is targetting all machines that did not upgrade / or could not being upgraded.
In the next picture (below) I added (by purpose) an additional "State" directly below the "Phase". The shown information is crucial to understand and adopt WaaS:
Understanding Reactive Testing

In WaaS you do "Proactive Testing" and you configure everything without making any mistakes and running through quality gates. (sure you do)
But - due to the fact of not having unlimited time like in Windows 7 - there will come a point in time, where you just suggest that everything will work.
This approach is called risk based approach, which is specifically targetting applications. (further information in previous WaaS Article)
The first question I always get is - WHAT? You want to possibly impact some of our machines in the field?
The answer is - Yes!
Who are the best testers? People who actually work with the applications!
What is the impact? You define the impact by defining the number of computers which are upgraded at the same time, in the same OU with the same applications.
What is the impact for the chosen users who will run into problems? They will call either Support desk or their Application Holder and then roll back --> 30 minutes to 60 minutes
What is the outcome? You will get very early dedicated and precise information, what is not working.
What is next? You have to prepare a workflow for this scenario. Depending on the application impacted - pausing further deployment and resolving the problem:
- internal validation
- validation by Application Holder
- Support Call at Manufacturer
- Contacting Premier Support from Microsoft
- Validating fallback or alternative options
After having fixed the issue you can just continue with your deployment.
Take a look later at "Target Deploy" in the topic "Technical Approach in Theory".
More information here.
Dividing into fixed Procedural Steps
As a result of this you should collect a list for who has to do what starting at a specific point in time and completing in a specific time frame with an end date and what should be the outcome.
This sentence is extremely important and therefore we will take all the necessary information out of it: 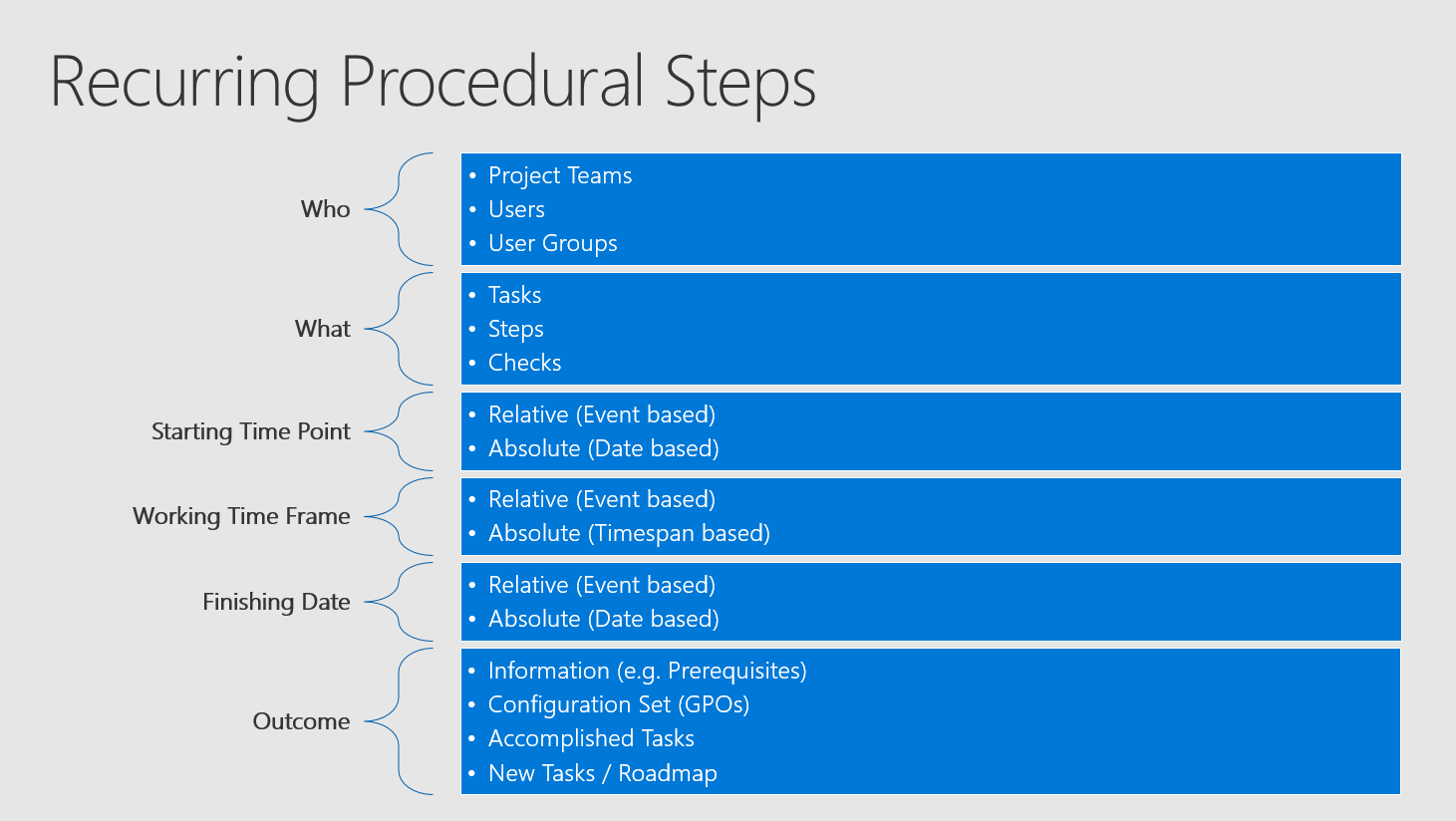
This is simple project management and setting up all the tasks should be easy work. The cool thing about this (every project manager should love this) - these tasks need only to be set up once. With every Feature Update normally only the settings of these tasks are optimized - sometimes there may be also some tasks added or removed, but - all in all the whole task list is a pretty solid setup (this has to be your target). And now you may see the first problem here:
You need to set it up with a decent amount of time and care.
Because of its impact you want to make absolutely sure, that the defined task list is complete and correctly "configured".
How?
Communication!
What else?
Project Management!
To retrieve a complete and well configured list of tasks you should set up meetings and firstly brainstorm from a technical, but also procedural and business-depending point of view. Just grab every idea from every team or person and write it down. Discuss about removing unnecessary or unappropriate tasks. Think also of consolidating or dividing tasks. Then you should define at least the values for who, what and the outcome for all tasks.Decide whether it makes sense to use Date-based or Event-based (prefer this one the most of the times) and then visualize all the tasks and put them into your timeline for ONE specific OS Version. In the end it is about fine-tuning.
The whole process can be seen in the next picture - depending on your company this process may take some time. (hopefully not months) 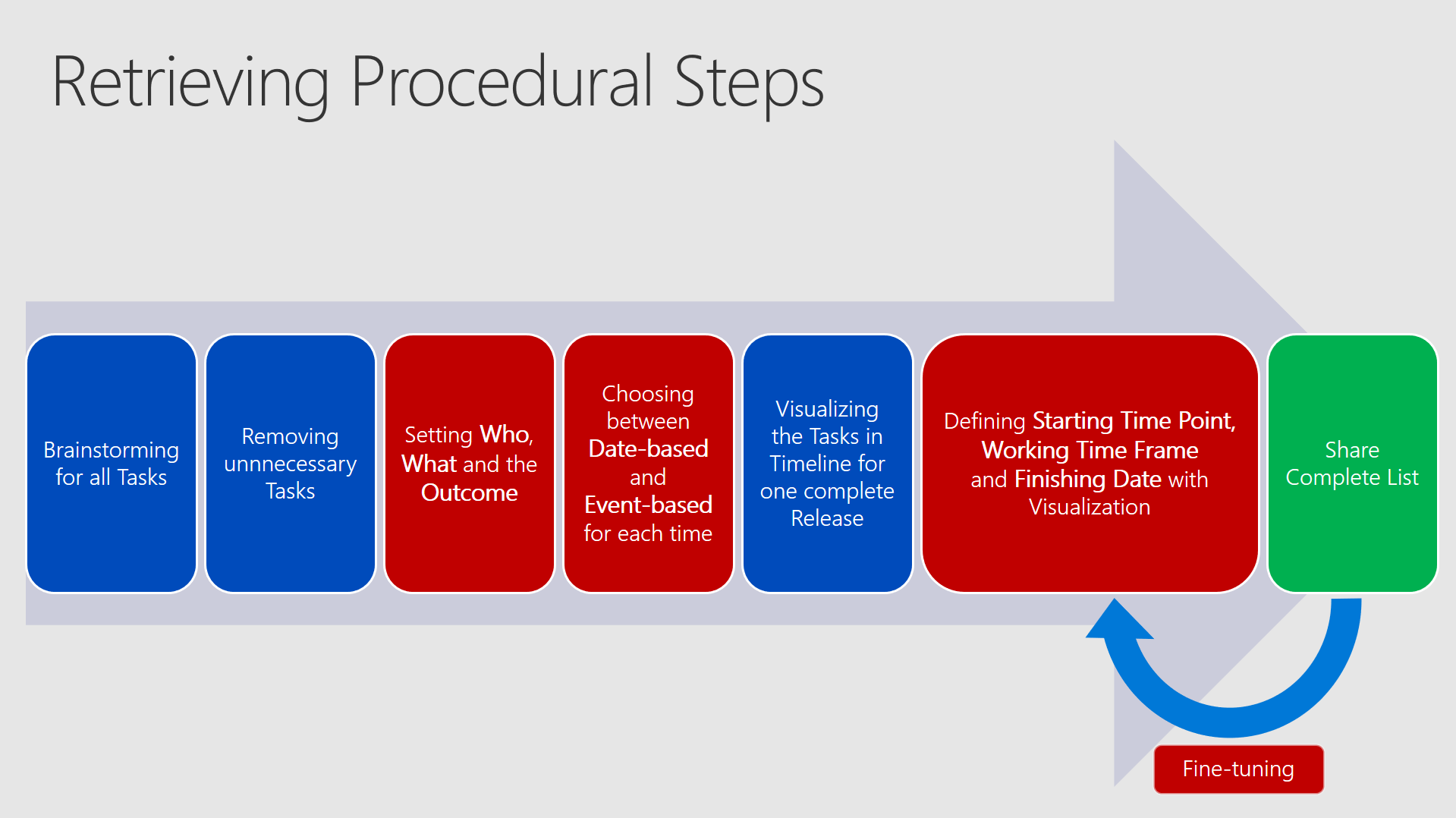
The blue boxes can be done with ease, but the red ones need to be really handled with care and should be well-considered.
Let us take a look at two demos of the mentioned tasks:


This is the same example for "Validating new Features" - the first one with absolute dates and the second one based on events. You need to decide by your own, which makes more sense, but we will see later on, that the distribution of each Windows 10 Feature Update (Upgrade) is implemented technically event-based.
Process Optimization
Some lines above I have spoken about the visualization of the tasks. A project manager normally should jump up and and shoot out, that he knows some techniques to accomplish this. We are now moving into some tasks of his job and therefore it may look complicated for some people. (it isn´t that complicated) Personally I would say, that there are two good approaches on this - depending to your company size:
Gantt Chart
The good thing about the Gantt Chart is, that nearly everyone has seen or worked with similar charts. It is straightforward und easy understandable - even for non project managers. But it has one devastating downside - if you want to manage and improve a lot of tasks with the Gantt Chart this will become unhandy and confusing. Therefore you should retrieve your amount of possible tasks and decide in one of the first steps, if the Gantt Chart is the technique you want to focus on.

Critical path method
The other possibility, which I have seen a couple of times is to work with the Critical Path Method or some similar methods. There is one downside here aswell - setting it up and staying up to date takes more time than with the Gantt Chart. But you can control even better your gaps and holds and optimize all the processes in a centralized way.
Due to its complexity you could even use both: Use process automation in the Critical Path Method by dedicated and trained project managers, but deliver simplified Gantt Charts - to the dedicated teams (with only partial outputs). By doing it that way you would have a complex (but effective) project management with the possibility to visualize it in a simplified way for all the teams and involved persons. 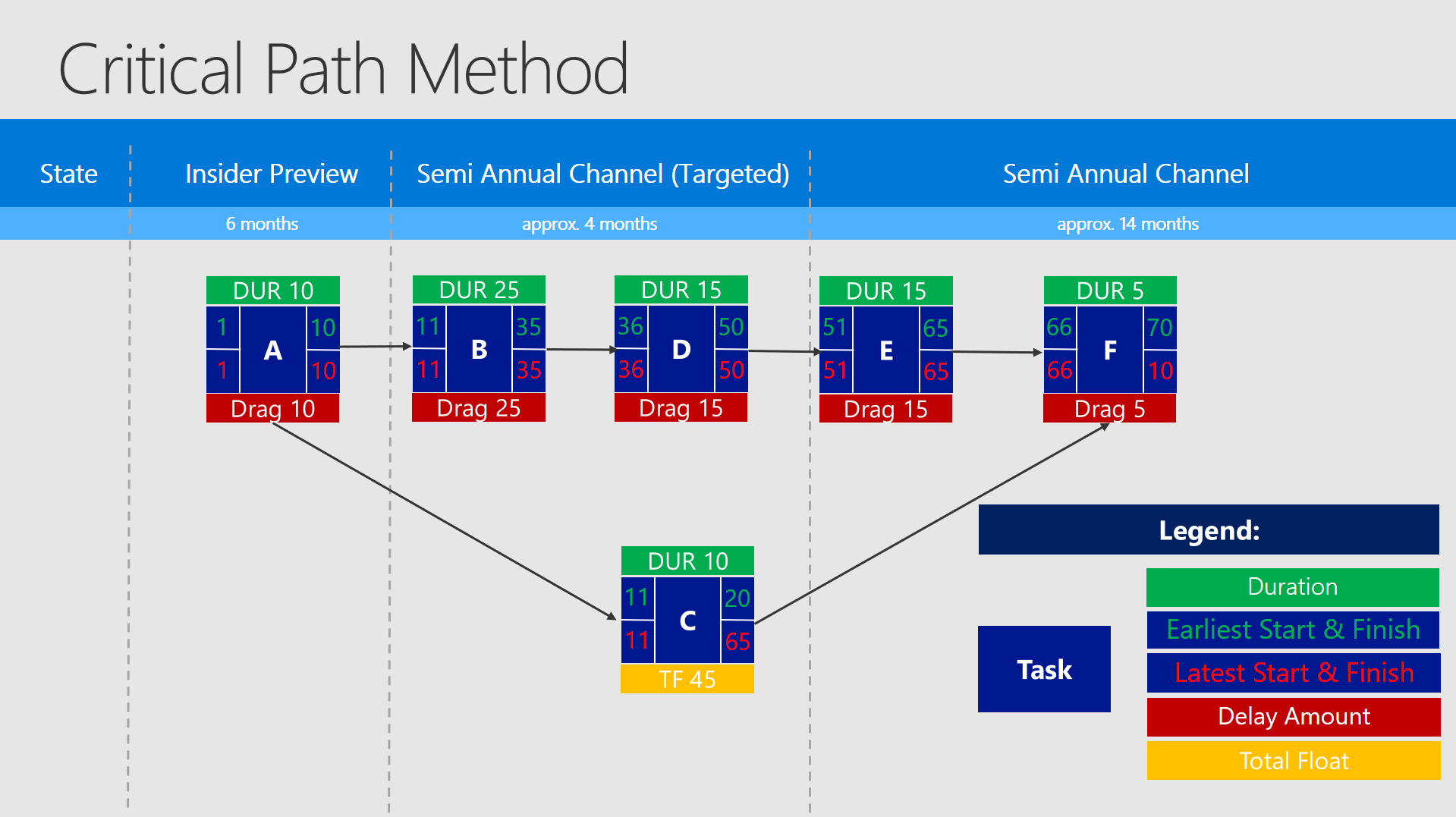
Outcome
The outcome should be an optimized list of tasks which should be addressed for one dedicated release. I will just brainstorm to give you a brief overview, which tasks could be implemented:
- ADMX - Download & Install
- Manage GPOs
- Validating (new) Features
- Knowledge Management
- Internally
- Teams
- Users
- Validating Feature Closings
- Setting Infrastructure Requirement
- new projects
- Test Inplace Upgrade
- Upgrade itself
- Look & Feel afterwards
- Technical functionality afterwards
- LoB Testing
- Setting up OSD TS
- Download ISO/WIM
- Report evaluation
- Upgrades
- Versions
- ALM
- Feedback Management
- Retrieval
- Push
- Pilot Deployment
- Outcome
- Targeted Deployment
- Outcome
- Broad Deployment
- SLA
- Compliance Cleanup
- Change Management
- Security evaluation
- Evaluation with Legal (Telemetry etc.)
- Evaluation with workers council (new features / changes)
- Upgrading depending technologies (Configuration Manager, O365 etc.)
- Remediation Task
- Application Incompatibility Workflow
- more
Technical Approach in Theory
After knowing about the 3 phases we will now divide all the phases into smaller chunks.
This is what we (Microsoft) call rings - targeting a defined collection to be applied to a specific timestamp which is relative to one of the events "Insider Preview", "SACT" and "SAC". What does this look like?
[video width="800" height="1080" mp4="https://msdnshared.blob.core.windows.net/media/2017/08/WaaSArticle2_Rings.mp4"][/video]
The video showed how the timeline is split into these rings and ended up in this slide (beware count of rings only for demo purposes):
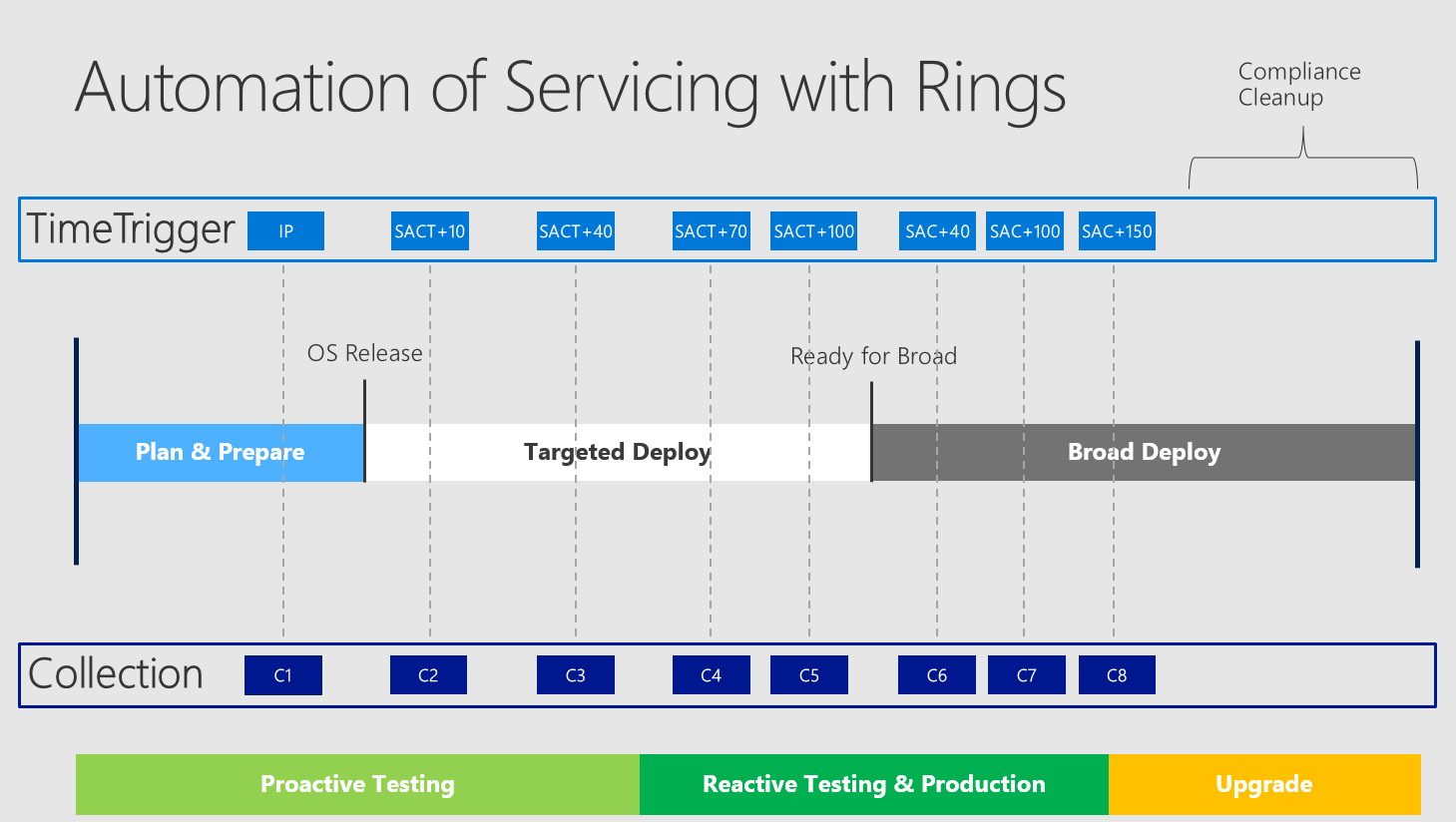
So you divide your complete timeline for one OS version into rings ("TimeTrigger" with specific "Collections"). These specific collections are used for the automatic upgrade and do have different purposes.
Centrally-Controlled vs. User-Controlled Upgrade
The date which is event-based could be the starting point of the deployment or a forced and fixed upgrading date.
I usually recommend that we (administrators) define the time frame where the upgrades are available (1-4 weeks - afterwards forced) and the user defines the point in time, when he initializes the upgrade.
Depending to your environment either the one or the other or even both methods could make sense and should be used. This is something that you have to discuss.
If the user initializes the upgrades he definitely needs to be aware of, what that means for him and his machine. (1h upgrade time)
Okay - let us take now a closer look to the collection numbers. What are the right numbers for collections? To discuss this question let us take a look at the 3 areas in detail:
Plan & Prepare / Insider
As you have read above, the main target here is to evaluate new or possible deprecated / removed Features and probably aswell some or all LoB Apps.
How many collections do you need in the space of the Insider Preview / Plan & Prepare?
I would say - not much. One might come into consideration - for example with a virtualized machine, which can easily be rolled back to defined checkpoints and easily by repaired by recreating it. This one could also be greatly shared along different teams to connecting remotely to it. But using also some dedicated machines should be discussed. (2nd devices, dedicated testing machines, etc.) You would configure Insider Preview - Fast Ring on these machines.
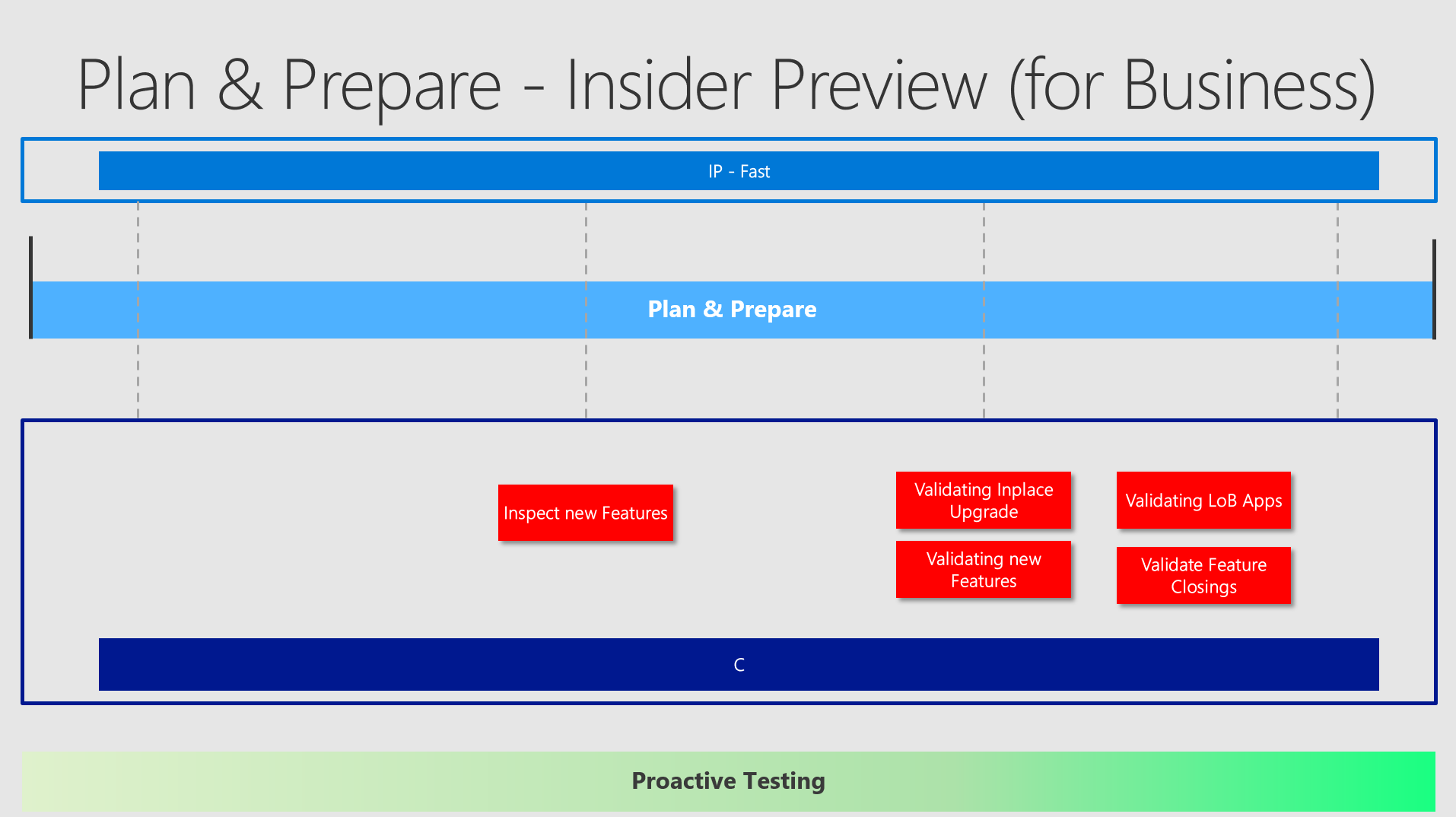
Additionally you could add two more rings and having the following three:
- Insider Preview - Fast
- Insider Preview - Slow
- Preview Release
Targeted Deploy / Semi Annual Channel (Targeted)
Okay - now it gets more complicated. What are the first aims in the Targeted Deploy? Definitely to set up the client configuration and to get everything ready for broad deployment:
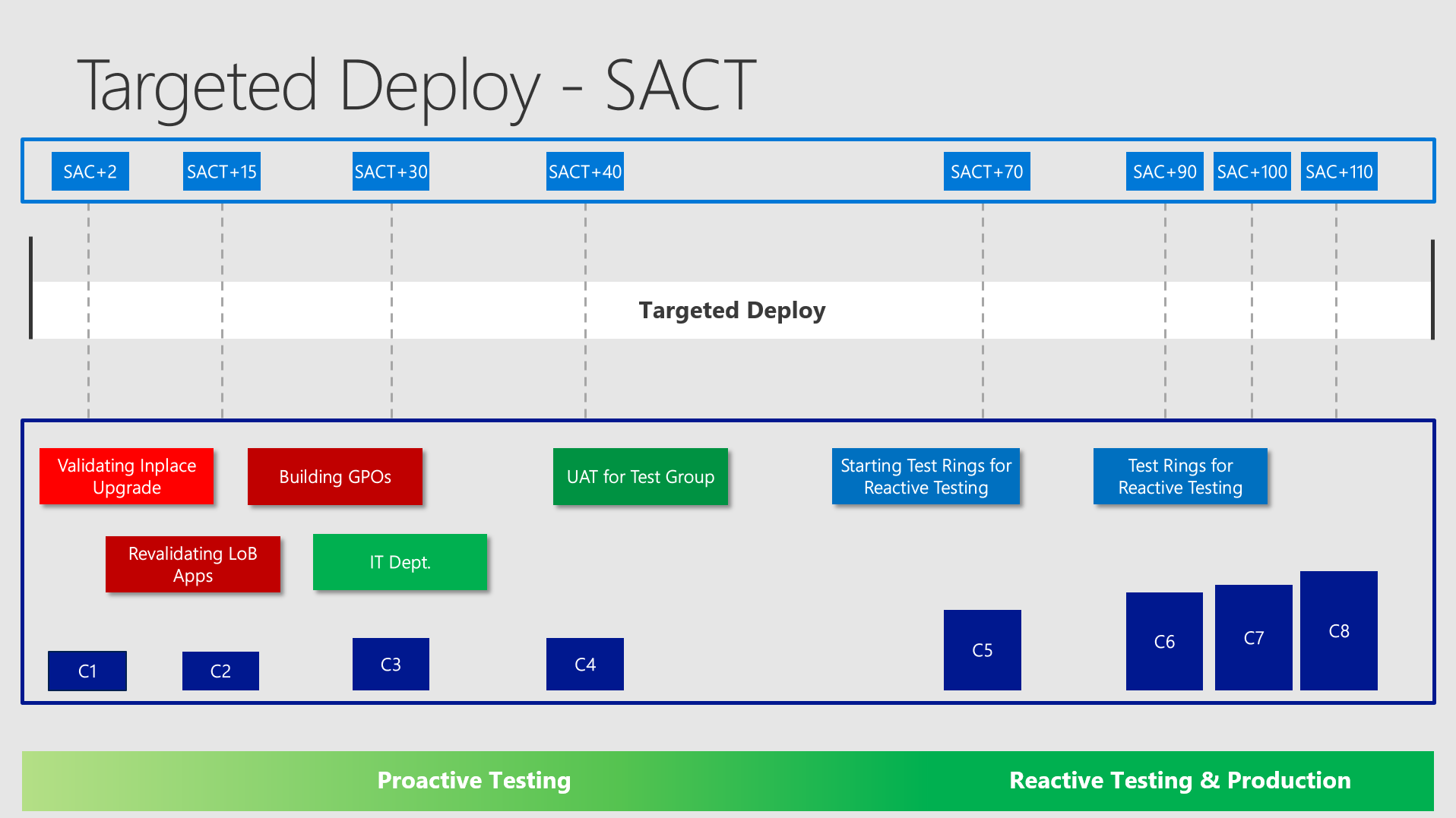
You would probably set up machines for the GPO team and Application Testers on VMs or dedicated machines and so on. You should take a look at your complete task list and decide whether you need a specific collection for some tasks and define the earliest time of usage.
Targeted Deploy - Reactive Testing
This part is for sure some of the biggest challenges. As you have read you should target a transversal cut of:
- Applications
- Organizational Units
- Network Segments
- Geographical Locations
and divide them into representative collections. For this you will need many information and some script / tools to assist you in doing this. I will discuss some of the ideas in the Technical Approach later in this article.
Testing Rings
In targeted deploy you want to get as soon as possible ready to push out your testing rings. In the example I am starting the "UserAcceptanceTest" (UAT) 40 days after release and the "Testing Rings" after 70 days. The earlier you can address this - the better!
A good advice here is to upgrade around 10% of all the devices in your environment in Targeted Deploy to be ready for broad deployment. You don´t want to find any suprises in Broad Deployment - therefore you provoke them as soon as possible. (By experience these suprises are easily handleable as long you detect them very early and in small number counts!)
Broad Deploy / Semi Annual Channel
In this phase you push out the higher numbers - depending on how many rings you want to define here and how many clients you have in total, you could easily have numbers above 10k for one collection.
In the middle you see the group of sensitive machines and VIPs. There may be this kind of machines which should possibly never fail / or you want to reduce the chance for this to a very maximum.
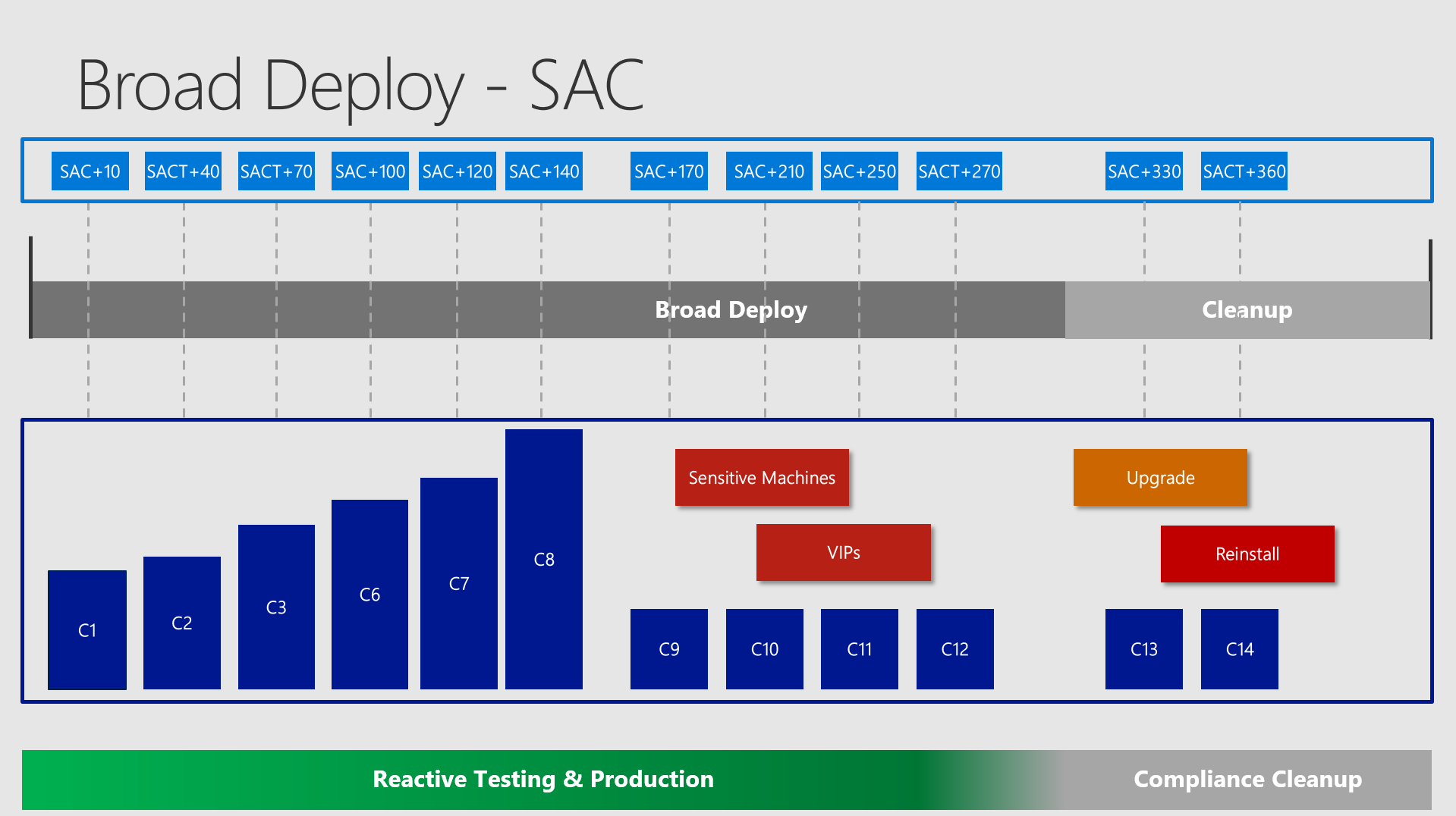
In the end you have the Compliance Cleanup where you want to make sure to address the computers, which had problems and did not upgrade properly. A good idea would be to set up collections finding all the computers which are sitting on the old version and then pushing out another upgrade. The last instance would be to reinstall them - surely with the newer OS Version on it.
Defining the numbers of total rings
We can easily ignore the Insider Preview / Plan & Prepare Phase for this, because more than 3 rings in this phase wouldn´t make sense at all. But speaking of the rings placed in SACT and SAC this decision could easily get harder. I want to show and discuss the following numbers:

For Insider Preview you could set up 1-3 and letting the machines always upgrade for themselves as configured. (Fast / Slow / Release Preview)
For Targeted Deploy I would always say the absolute minimum is 3. You will need one at the very beginning, but you want also to start reactive testing at the end of the time span.
For Broad Deployment you should evaluate the number of clients in your environment, aswell the number of locations and possibly also the number of OUs or the specialization of your teams. The more complex your environment is - the more rings you should just use to control the impact.
And how many do you exactly need? It depends.
I would say a pretty solid approach is the illustrated 1 - 8 - 12 - 2 approach.
If your company has more than 50k Clients I would definitely recommend starting to increase the numbers. After hitting 100k you should evaluate the maximal recommendation count. I hope that you also did understand till here, that these collections don´t need to be created nor filled manually.
Technical Approach
Okay - as we have read now all the theoretical approaches, we should move on and trying to adopt it technically. This part is actually the most simple one, after you have determined all the processes and also planned for a specific number for all the rings. To give you an overview we should take a look at the possibilities and evaluate them:
- Windows Update for Business
- WSUS standalone
- System Center Configuration Manager + WSUS
- Upgrade-Tasksequence
- Servicing Plans
- Third-party Deployment Tool
More information here.
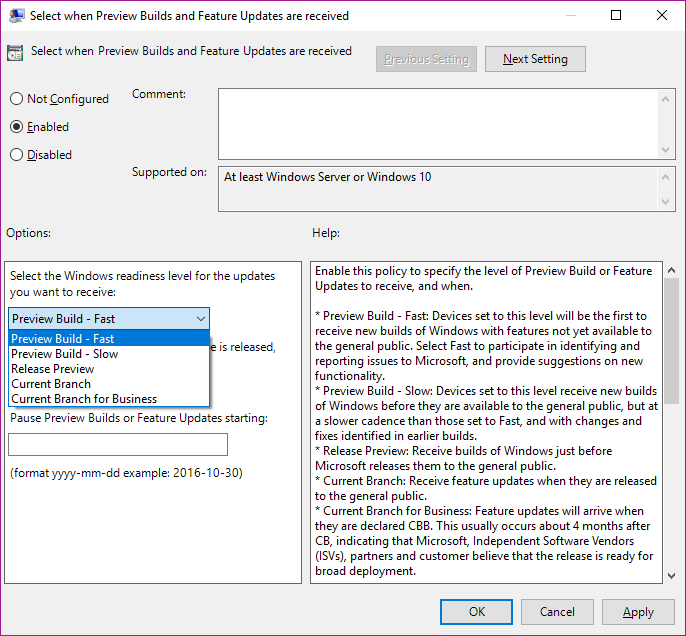
Windows Update for Business
WUfB is the client-side Windows Update Agent which is configured via GPOs. As for know these GPOs look like this (SAC and SACT will show up in 1709):
More information here.
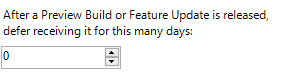
As you see you can choose between the different "States" of the OS and postpone it by days, which was decribed in the previous topic "rings". The main management would be done with GPOs or even AD groups to set up the rings.
This technology should be considered for devices, which are mainly attached to the Internet. You should also configure some kind of caching technology - for WUfB this would be Delivery Optimization:
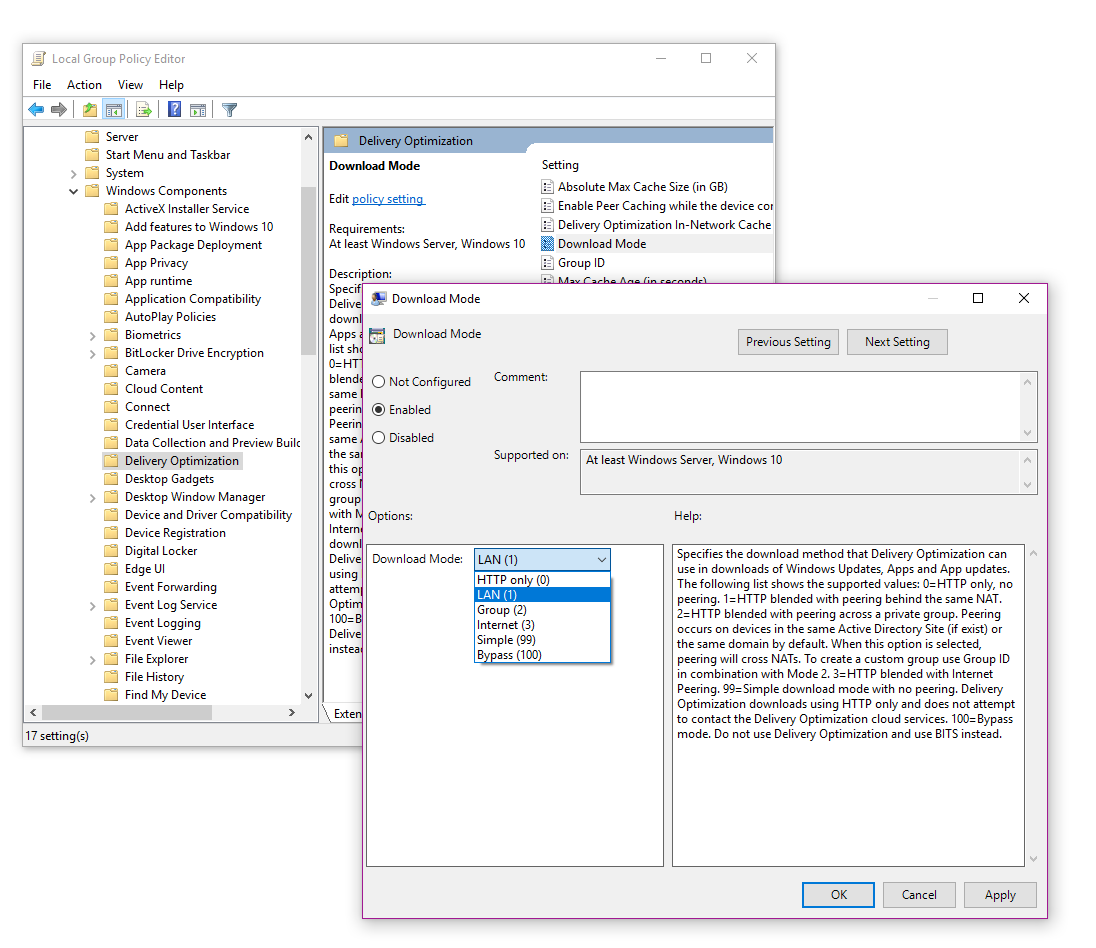
A good way of controlling which computers share with each other is configured as "LAN" and also by "Group". By "Group" can be configured to your specific environment - you would then also define the specific groups via GPO:
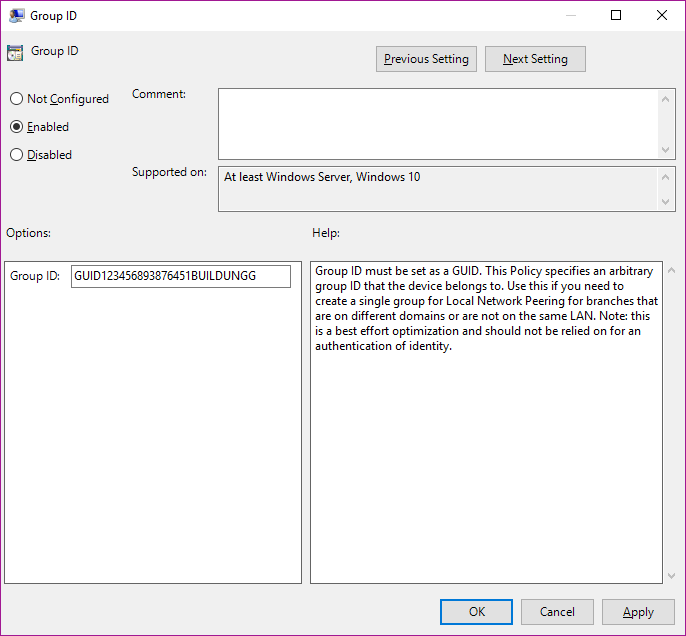
More information here.
The good thing about WUfB is that the Windows Update Agent gathers by default with UUP only the delta ESD material for Upgrades. (read here)
WSUS standalone
There are not many companies which are using WSUS standalone, though it is also possible to apply the ring-model to this:
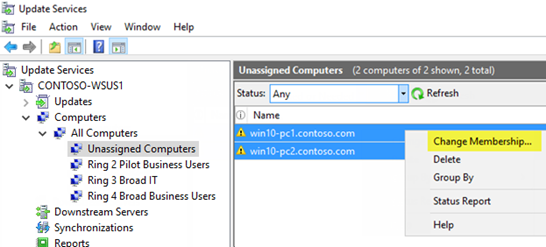
We have improved our official docs - take a look here for a real good description, how it can be configured.
System Center Configuration Manager + WSUS
In this area we have actually two possible ways for adoption:
- Upgrade-Tasksequence
- Servicing Plans
The main difference between these two is that in the Tasksequence a complete WIM is used, where in Servicing Plans you are sending out the Feature Updates consisting of an delta ESD. We are technically speaking from a difference of 3,6GB vs approx. 2GB. As you have read this you may think, that Servicing Plans is the way to go. It is, but unfortunately it seems that no customer has even tested Servicing Plans and the cause is pretty understandable. The Upgrade-TS is a known and very approved way how to create and work with deployments in SCCM. All admins know how it works and how to set it up. Additional to this - lazy - argument you can also include easily and many steps before and after the upgrade. In the past this may be often been necessary. e.g. till Windows 10 1703 all apps were reinstalled to the computer and there have been some issues with Language Packs and some of the Personalization Settings.
We are working on these issues and targetting an upgrade without the necessity for too many post-upgrade tasks. As for know my personal recommendation is this:
- Implement the Upgrade-TS with all necessary steps
- communicate necessary steps / cleanup tasks / neccesities for repairs to TAMs / PFEs
- Build up the structure for Servicing Plans aside
- Define the rings
- Define the collections and what computers are in there
- Train yourself and get the understanding how it is working
- Understand the Reporting
As you have read you may have catched that I personally think Servicing Plans will replace Upgrade TS pretty fast in the future. Let us take a closer look and you will see some more arguments for Servicing Plans.
Upgrade-Tasksequence
The Upgrade-TS gives you control to define a complete workflow before and after the upgrading process.
This unfortunately allows to do steps, which are normaly not intended to be done in Upgrade.
Examples for don´ts:
- Upgrading applications before OS Upgrade (Application Lifecycle Management! Update the package in your environment before moving to next OS version)
- Upgrading all your software ( you should have a working Application Lifecycle Management in Place continuously updating your applications!)
- Reinstalling all your software - just in case (What ? no. Find the errors why upgraded packages / applications stop working after an upgrade and fix them correctly in the package itself)
- [...]
There might be some scenarios where additional steps are necessary and therefore Upgrade-Tasksequences are the better choice.
Example for do´s:
- Moving from BIOS to UEFI --> MBR2GPT
- Moving from 3rd-party disk encryption to Bitlocker
- Multi-Language environments with unsolvable issues (till now)
- LTSB feature updates. With the LTSB servicing branch, feature updates are never provided to the Windows clients themselves. Instead, feature updates must be installed like a traditional in-place upgrade.
- [...]
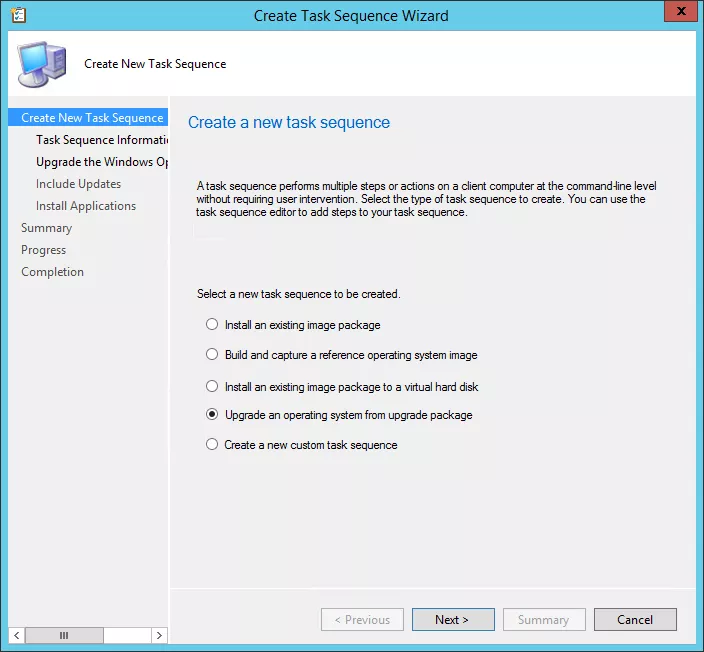
The problem with this technology is the requirement to prepare all collections in the first steps for all the rings and the necessity to fire each ring manually or by script. This needs a huge workload as overhead to automate WaaS as described. I don´t say it is not possible - it actually is, but I doubt that this kind of time investment is necessary for the adoption of all rings.
Therefore I recommend only using Upgrade-Tasksequence for manual deployment and not as complete solution for the rings.
More information here.
Servicing Plans
This whole article is actually targetting Servicing Plans. Let us take a look at the Servicing Dashboard: (old namings visible - I will replace with newer and better pic asap)
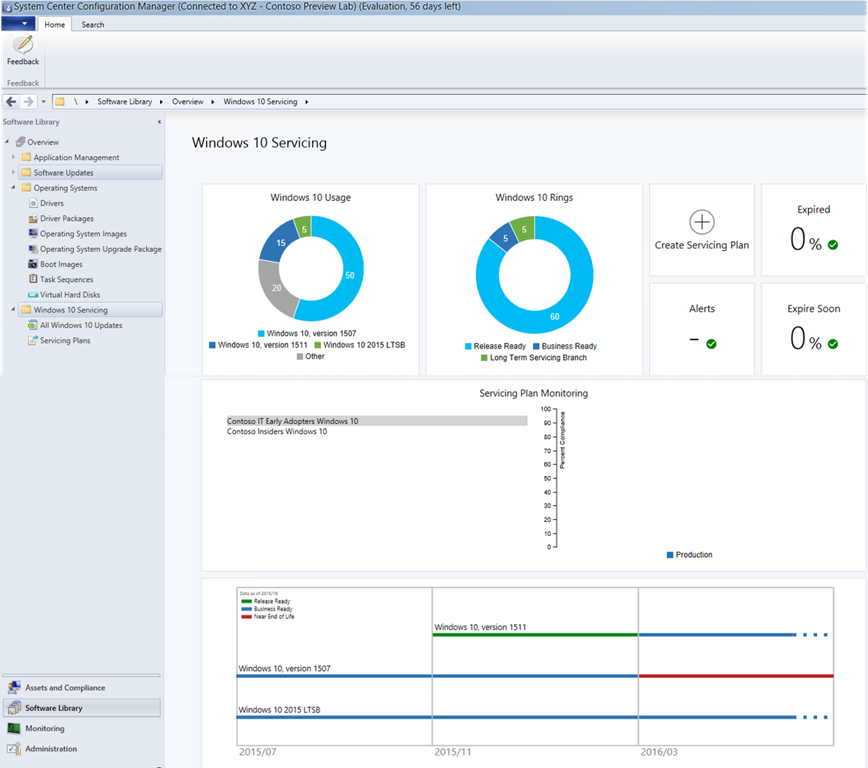
I recommend reading the great blog article from Niall C. Brady, Enterprise Client Management MVP - it is a perfect guide for how Servicing Plans are manually created.
So you would set up the rings with automatic deployment rules to trigger at the specific events, which you configured. This is actually the exact thing we need to have.
The good thing about this - you just need to configure it once - it will reapply for every coming OS Version. (main difference to Upgrade TS)
You should also take a look at the PowerShell CmdLets: New-CMWindowsServicingPlan, Get-CMWindowsServicingPlan, New-CMCollection, New-CMSoftwareUpdateDeploymentPackage, Get-CMSoftwareUpdateDeploymentPackage,
Get-CMWindowsUpdate, Save-CMSoftwareUpdate, Start-CMContentDistribution

For automating the creation with PowerShell you could easily create the collections, the deployments and the ServicingPlans via Script:
Take a look here or here from Kaido Järvemets.
I am currently working to set up some clever script to allow the creation of the collections, the plans and the more complicated queries for the collections used. (next topic)
Also in comparison to the Upgrade-TS there IS also the possibility to initialize post-upgrade tasks. Take a look here.
And more information here and here.
Third-party Deployment Tool
It depends to your third-party deployment tool, if it is capable to deploy and control Feature Updates in an automated manner AND with using Delta ESD material. If it does - good. If not - I would always recommend to use some of the described technologies. WUfB or WSUS standalone should come here into consideration and be discussed.
Filling Collections with representative Devices for Reactive Testing
This part is for sure some of the biggest challenges. As you have read you should target a transversal cut of:
- Applications
- Organizational Units
- Network Segments
- Geographical Locations
and divide them into representative collections. For this you will need many information and some script / tools to assist you in doing this.
Setting up well-chosen collections is the point where all this model could shine or either collapse. Unfortunately to its importance it is also - I would say - the most challenging part of this all.
Let us take a look at the different targets:
Applications
You want to reactively test all applications to not running into any suprises in the broad deployment, where you deploy your upgrade to larger collections. So you are provoking on purpose possible problems to find them as soon as possible to have enough time to react. The idea is pretty easy. The problem - do you have a complete list of all your applications and can you define good testing machines?
As mentioned in my last extensive article you should work in collaboration with the Application Holders. One approach can be to allow them to define test users. Another approach would be to let the user define his collection by himself. I will get into this later in "What I am working on"
Organizational Units
This is easy possible with a PowerShell Script running through all OUs and picking a by algorithm defined number of devices and moving them into the first collections. You want to do this to have the additional safety to not miss some applications out and also to validate some coincidences with GPOs.
Network Segments
This is about bandwith and about clever caching. By configuring - for example - the Windows Update Delivery Optimization for NAT and upgrading a small number of computers in each location, you will have caching points in place without the necessity to reevaluate this all the time. This information could be retrieved via Script from SCCM.
Geographical Locations
With this marker you just want to make sure not to find any special locations with dedicated networking problems. It should be included in OUs and Network Segment, but you should just make sure that you did not miss any location out in your tests. May be there is some naming convention in the device names which allows you to identify the locations - or it is managed via OUs.
What I am working on
I am working on two possible approaches
- PowerShell Script / Module / Tool with UI to create the rings manually, semi-manually (changing) and automatically - the idea is to define all the rings till "Targeted Deploy" C6-7 (semi-)manually and the rest automatically by just dividing the left devices into chunks and spreading them with an algorithm into all the collections
- Tool to allow the User himself from a client to move him into specific collections
Let me know your ideas and feedback - are there any other ideas to be discussed?
Exception Handler
What do you do, when you encounter some problems / application incompatibilities? As described in my last article you should have up some workflows for these situations. Working with Servicing Plans (and all other technologies) you can always pause the current deployment and just continue it, when you have fixed the cause.
Further Improvement
After reaching this kind of automation there will be still space to improve:
Knowledge and Information Management
- Update of central information stores (OneNote / SharePoint / Teams) and pushing out email to IT Teams / End Users automatically at a specific event
- Preparing the layout of emails
- Setting up Meetings automatically
- Setting up Webinars automatically
Reporting / Alerting
- Automatic control of reports
- Sending emails on defined SLAs automatically
- Sending out reports automaticaly
Automatic creation of Compliance Cleanup Collections
- Automatically inform the impacted users of the state - warning and advising them
- After defined alerts automatically create cleanup collections for forced upgrades or reinstallations
- Send out automatically reports of its success
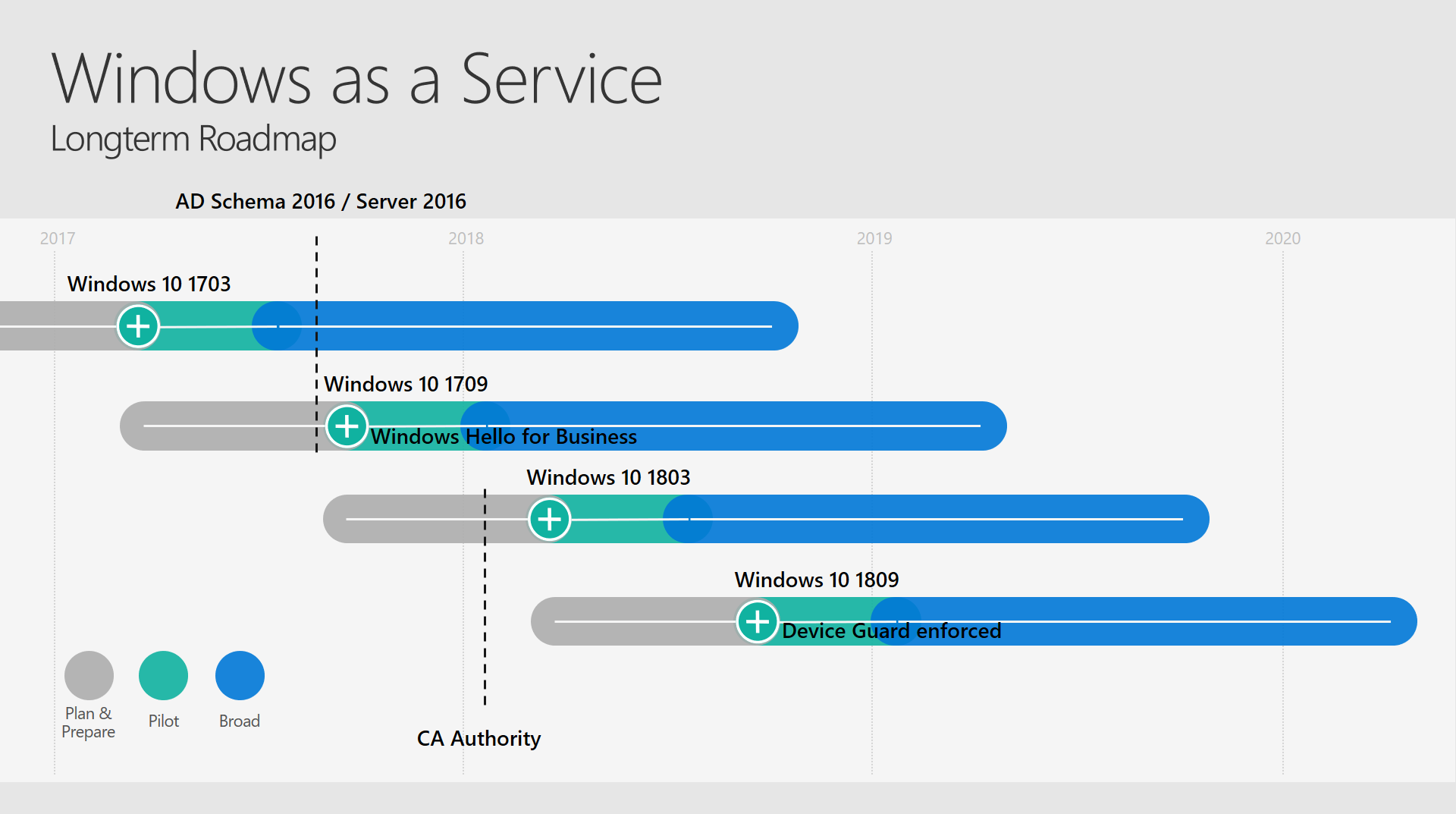
Longterm Roadmap
- Plan longterm adoption of technologies
- Define target versions for specific OS releases
- Create more automation around this
- Information and Knowledge Management
- Setting up defined Meetings automatically
- Automatic Involvement of Finance Team
Summary
If you have come this far I am very proud of you. (Yeee... too long - I know)
What are the main points?
You want to have the information at the earliest point in time where you could get it.
You want to mix proactive and reactive testing depending your company. (more proactive or more reactive)
Workflow:
- Set up processes and work with project management techniques
- Understand and define rings
- Define a method for upgrades: fixed date (centrally-controlled) vs time frame (user-controlled upgrade)
- Implement the rings technically
- Keep automating additional recurring steps - like:
- Knowledge and information management
- Reporting / Alerting
- Automatic creation of Compliance Cleanup Collections
- [...]
- Address Feedback to us
TL;DR;
Automating the Windows as a Service Model is possible and I actually recommend doing this for EVERY enterprise customer. You will need some time in the preparation phase and setting up the whole process, but in the end you will save a huge upcoming and recurring workload.
By defining well chosen computers into your rings you predefine the possible impact and completely control your testing approach. The best toolset for this task is probably SCCM with Servicing Plans, but it is also possible with WSUS standalone or Windows Update for Business (or even a third-party solution) - you have just to implement the automation steps.
The target must be to set up an technically automated environment where every team and user (who may need this information) at every time know, on which phases is currently being worked and what follows.
It needs to become a always recurring adoption cycle where manual tasks should consecutively being replaced by automation / scripts / automatic processes.
The outcome will be to integrate Feature Updates mostly in the operative work. If you ignore this recommendation you might end up struggling a lot.
Thank you all and I hope it was somehow helpful and you could take some points for your environment out of this huge article.
All the best,
David das Neves
Premier Field Engineer, EMEA, Germany
Windows Client, PowerShell, Security




