Ask Learn
Preview
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign inThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Japan Data Platform Tech Sales Team
高木 英朗
前回の記事では、HDInsight の概要と実際に Azure のポータル画面からデプロイする方法をご紹介いたしました。今回は HDInsight へのアクセス方法や Hive、Spark の実行についてご紹介いたします。
前回の記事でデプロイした環境を使って試していきましょう。
Ambari へのアクセス
デプロイが完了すると管理画面にアクセスすることができます。ここではクラスターのスケール設定、インスタンスの削除等の管理ができます。管理画面の [クイック リンク] からクラスター ダッシュボードのメニューに入ると、HDInsight を管理・操作するためのリンクが表示されます。HDInsight のクラスター管理は Apache Ambari を使用します。[HDInsight クラスター ダッシュボード] をクリックしてすると Ambari にアクセスすることができます。
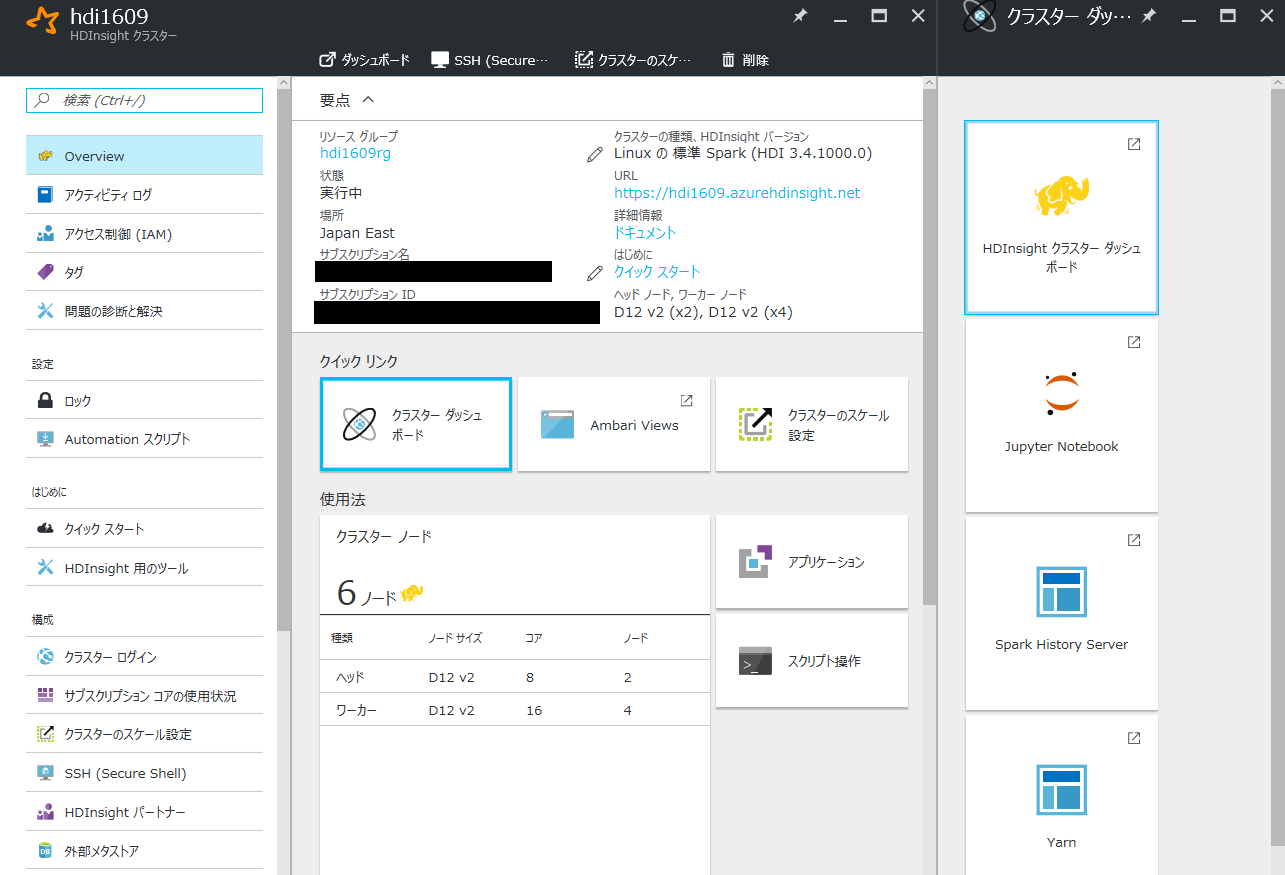
資格情報で設定したユーザー名とパスワードを入力してログインします。
ログインすると Ambari のダッシュボードが表示されます。ここでクラスターの監視、構成の変更、Hiveクエリ実行、YARNのスケジューラー管理等を行うことができるようになっています。
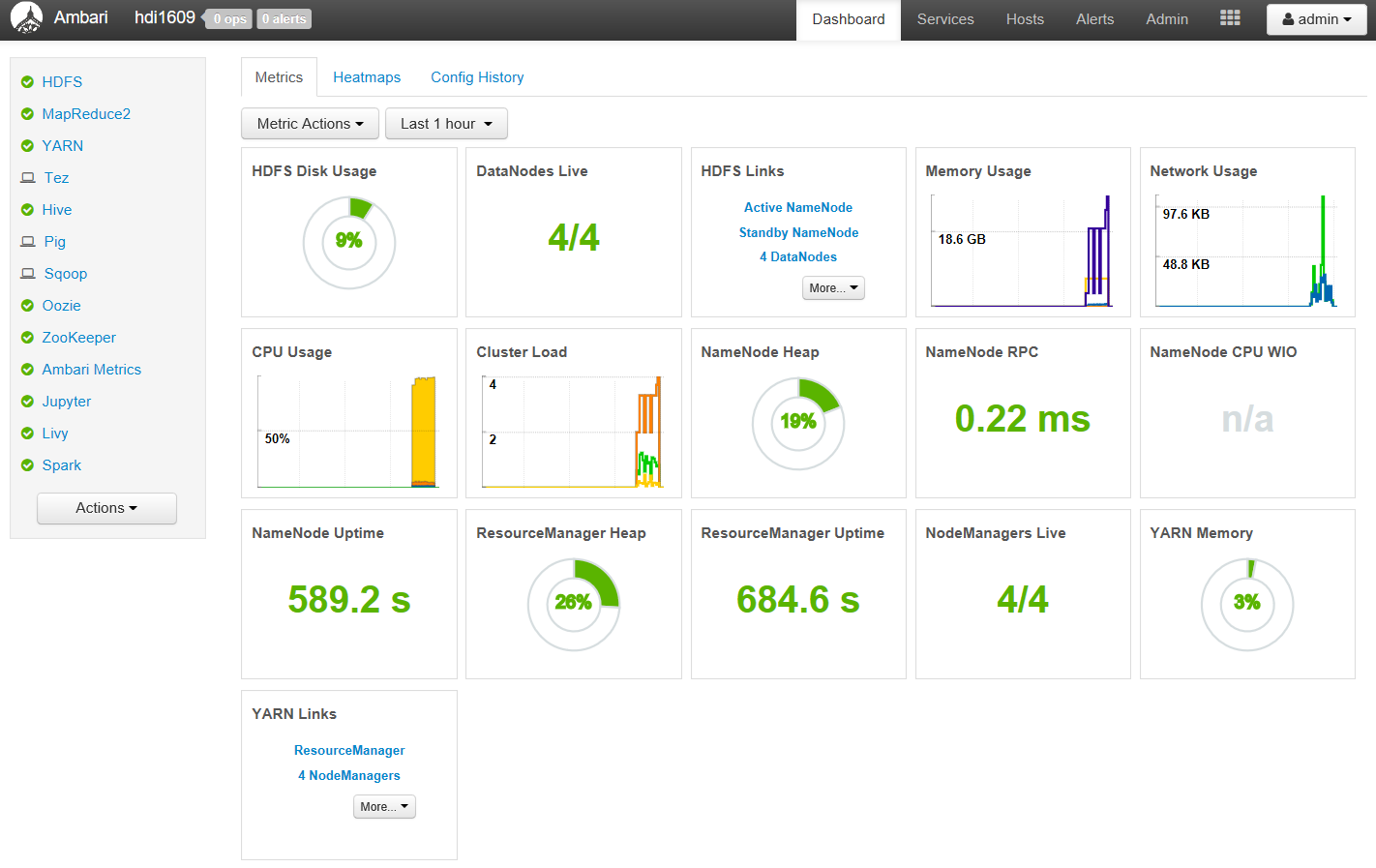
SSH でのアクセスも試してみましょう。Azure ポータルの HDInsight 画面にもどり [SSH (Secure Shell)] メニューに入ると SSH での接続先が表示されます。この接続先に対して設定した資格情報(パスワード認証または公開鍵認証)でログインします。
この例では Putty でログインしています。ホスト名に "hn0" と入っており、ヘッドノード (HeadNode0) に接続されていることがわかります。現バージョン (HDI3.4) は Ubuntu 14.04.5 LTS で稼働していることがわかります。
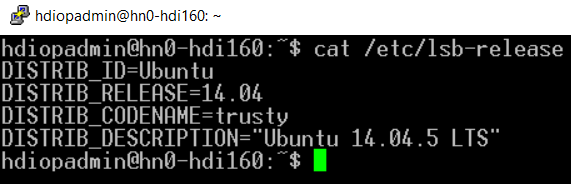
現時点では日本のリージョンにデプロイしても、システムのロケールやタイムゾーン等は日本向けに設定されていないのでご注意ください。
HDInsight の構成
HDInsight をデプロイすると様々な役割をもったサーバやネットワーク、データベース等が配置されて構成されます。以下の図は仮想ネットワーク内に Spark クラスターをデプロイした際の (おおまかな) 構成になります。
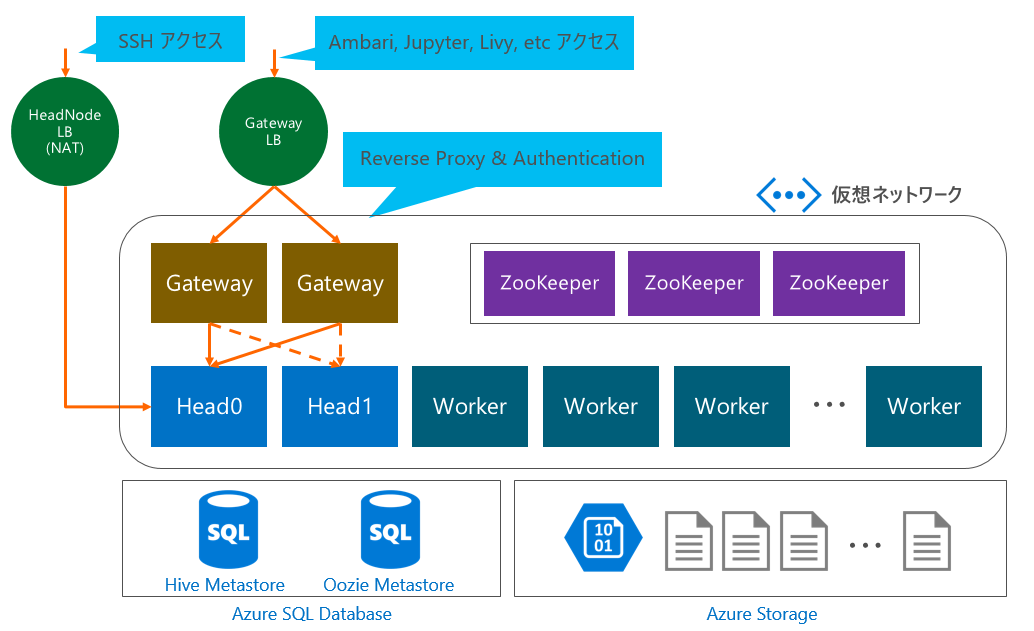
*本記事投稿時点でのアーキテクチャであり、今後変更になる可能性があります。
ヘッドノード (Head0, Head1)
HDFS の NameNode、YARN の ResourceManager、Ambari Server、 Hiveserver2 などが稼働します。HDFS や YARN などの一部のサービスは、常にどちらかのヘッド ノードで「アクティブ」になり、もう一方のノードで「スタンバイ」になります。 Hiveserver2 などは両方のヘッドノードで「アクティブ」になります。
ワーカーノード (Worker)
ジョブを実行するノードです。DataNode や NodeManager が配置されます。
Gateway
ヘッドノードに HTTPS でアクセスする際に Reverse Proxy として中継します。その際に管理者アカウント等の認証の役割も担います。
ZooKeeper
ここではヘッドノードのアクティブ / スタンバイ構成を支援するために構成されます。
Azure SQL Database
標準で Hive と Oozie の Metastore として利用します。これは設定で変更することも可能です。
Azure Storage
HDInsight ではストレージとして Azure Storage (Blob) を使用します。Azure Storage は大容量・低価格・高信頼性を兼ね備えており、他サービスとのデータ連携や性能面においてもメリットがあります。明示的に指定することで HDFS を使用することも可能ですし、設定を変更することでメインストレージを HDFS に変更することもできます。 HDFS はワーカーノードのローカルディスクによって構成されています。
各ノードへのアクセス
仮想ネットワーク内の Gateway 以外の各ノードには SSH を使ってアクセスすることができます。内部のホストを探すには以下のように Ambari REST API を使うと便利です。
curl --user '管理者ユーザー名:パスワード' https://クラスタ名.azurehdinsight.net/api/v1/hosts
リクエストを投げるとクラスター内のノードの FQDN を含んだ情報が JSON で返ります。Private IP のアドレス体系は仮想ネットワークのサブネット設定に依存します。
以下はレスポンスの一部の例です。
{
"href": "https://10.254.1.19:8080/api/v1/hosts",
"items": [
{
"href": "https://10.254.1.19:8080/api/v1/hosts/hn0-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net",
"Hosts": {
"cluster_name": "hdi1609",
"host_name": "hn0-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
}
},
(後略)
情報量が多いので探しにくいですが、jq を使うと JSON データ構造のハンドリングが容易にできて便利です。
以下は jq を使った例です。ホスト名の頭文字 hn は ヘッドノード、wn はワーカーノード、zk は ZooKeeper を示しています。
hdiopadmin@hn0-hdi160:~$ curl -s --user '管理者ユーザー名:パスワード' https://クラスタ名.azurehdinsight.net/api/v1/hosts |./jq '.items[].Hosts.host_name'
"hn0-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"hn1-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"wn0-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"wn1-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"wn2-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"wn3-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"zk0-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"zk2-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
"zk4-hdi160.dom4e4qycx5e1ii2ryvsfy0hnc.lx.internal.cloudapp.net"
*Gateway や Metastore 等は Ambari 管理下に無いためここでは表示されません。
これらのノードは仮想ネットワーク内の Private IP アドレスおよび 内部の FQDN となりますので、外部からは直接アクセスすることができず、HeadNode0 に SSH でログインしてからアクセスする必要があります。SSH ユーザーとパスワードは同じものが展開されていますが、公開鍵認証を使用している場合は それぞれのノードでも公開鍵認証が必要です。Putty であれば Pagent を使って 鍵認証をフォワーディングすると良いでしょう。
Hive の実行
簡単に Hive を試してみましょう。HeadNode0 に SSH で接続した状態から hive を実行します。
hdiopadmin@hn0-hdi160:~$ hive
WARNING: Use "yarn jar" to launch YARN applications.
Logging initialized using configuration in file:/etc/hive/2.4.2.4-5/0/hive-log4j.properties
hive> show databases;
OK
default
Time taken: 1.233 seconds, Fetched: 1 row(s)
テーブルを確認します。
hive> use default;
OK
Time taken: 0.114 seconds
hive> show tables;
OK
hivesampletable
Time taken: 0.108 seconds, Fetched: 1 row(s)
hivesampletable というテーブルが見つかったので確認してみます。
hive> desc hivesampletable;
OK
clientid string
querytime string
market string
deviceplatform string
devicemake string
devicemodel string
state string
country string
querydwelltime double
sessionid bigint
sessionpagevieworder bigint
Time taken: 0.44 seconds, Fetched: 11 row(s)
HDInsight にはあらかじめ サンプルのテーブルが作成されていることがわかりました。それではこれを使ってクエリを試してみましょう。
hive> SELECT country, count(country) AS cnt FROM hivesampletable GROUP BY country;
Query ID = hdiopadmin_20160918073336_a1c6deb3-22dc-4d1d-9672-4664ba956433
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1474176033094_0004)
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
--------------------------------------------------------------------------------
Map 1 .......... SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
--------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 11.07 s
--------------------------------------------------------------------------------
Status: DAG finished successfully in 11.07 seconds
METHOD DURATION(ms)
parse 28
semanticAnalyze 1,465
TezBuildDag 542
TezSubmitToRunningDag 97
TotalPrepTime 3,350
VERTICES TOTAL_TASKS FAILED_ATTEMPTS KILLED_TASKS DURATION_SECONDS CPU_TIME_MILLIS GC_TIME_MILLIS INPUT_RECORDS OUTPUT_RECORDS
Map 1 1 0 0 2.45 3,230 29 59,793 88
Reducer 2 1 0 0 1.43 2,170 0 88 0
OK
Antigua And Barbuda 11
Argentina 3
Australia 73
Austria 9
Bahamas 25
Bangladesh 2
(中略)
Viet Nam 7
Virgin Islands (U.S.) 1
Time taken: 14.766 seconds, Fetched: 88 row(s)
このようにデプロイ後にそのまま Hive が使える環境になっており非常に便利です。また、Hive の実行エンジンには Tez が使われており、通常の Hive より高速に処理されるようになっています。Hive の設定確認は Ambari または /etc/hive/conf/hive-site.xml からできます。
/etc/hive/conf/hive-site.xml の記述
<property> <name>hive.execution.engine</name> <value>tez</value> </property>
Spark SQL の実行
今回の手順のなかで Spark クラスターをデプロイしましたので、最後に Spark を簡単に試してみましょう。spark-shell から実行することもできますが、今回は HDInsight に含まれる Jupter Notebook から実行します。
Jupyter Notebook には Azure ポータルの HDInsight 管理画面にある [クラスター ダッシュボード] からアクセスすることができます。
TOP 画面は下図のように表示されます。

ノートブックを新規作成するには画面右上の [New] から [PySpark] (Python 用) または [Spark] (Scala 用) を選びます。利用したい言語に合わせて選んでください。
*今回は Spark SQL を実行するだけなのでどちらでも良いです。
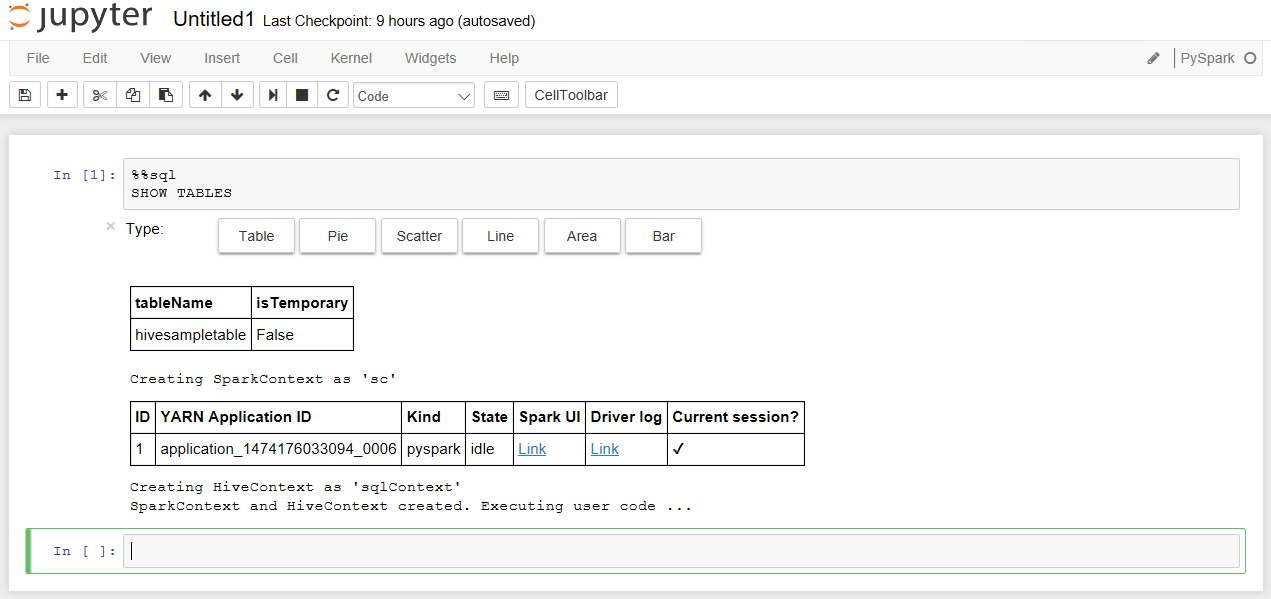
ノートブックを作成したらまずは Hive テーブルを確認します。セルにカーソルを置いて以下のように %%sql を指定すると SparkSQL を記述できます。続いて SHOW TABLES を記述します。入力が終わったら [Shift] + [Enter] を押します。そうすると処理が実行されてしばらくすると結果が表示され、先ほどの Hive テーブルが利用可能であることがわかります。
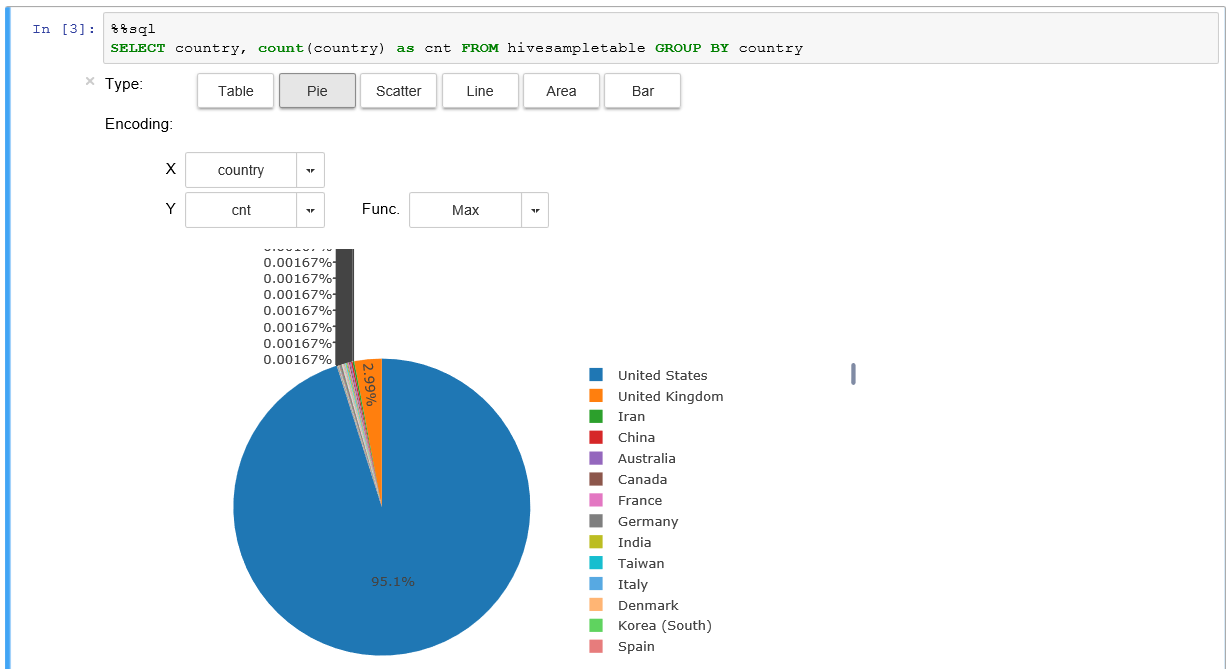
次のセルに以下のように入力して [Shift] + [Enter] を押すと、Spark SQL が実行されて結果が表示されます。
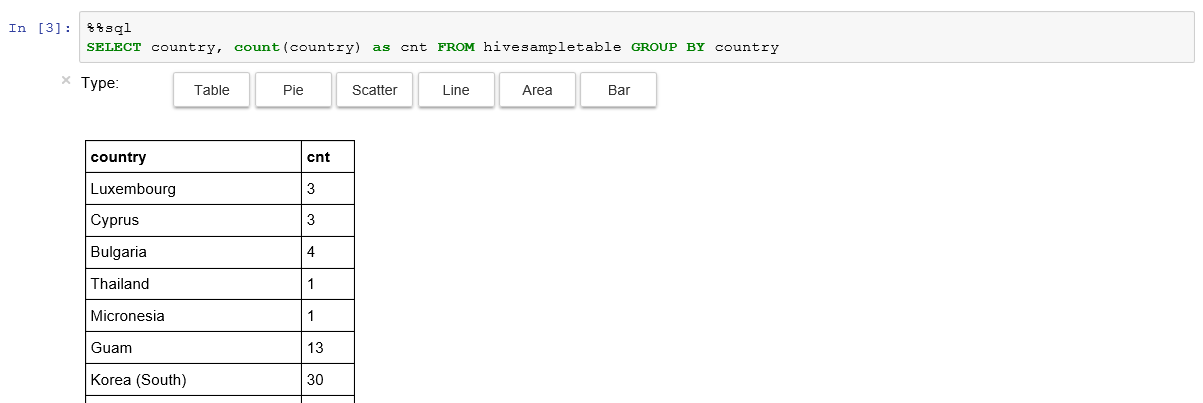
表示された結果内の Type を変更すると Jupyter Notebook の機能によって簡単なグラフを表示させることができます。このように Spark の実行環境もすぐに使い始めることができます。
分析がおわったら [File] メニューから [Close and Halt] を選択してセッションを終了させるようにしましょう。
以上、Microsoft Azure の Hadoop サービスである HDInsight の概要をご紹介いたしました。
Hadoop に興味がある方、クラウド上で分析基盤を構築したい方はぜひ試して頂ければと思います。
関連記事
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign in