Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (1)
Microsoft Japan Data Platform Tech Sales Team
高木 英朗
Microsoft の Hadoop への取り組み
Apache のオープンソースプロジェクトである Hadoop は多様で大規模なデータを分析するための非常に強力な基盤として多くの企業で活用されています。「Microsoft が Hadoop?」と思われる方もいらっしゃるかもしれませんが、実は Microsoft は Hadoop のオープンソースコミュニティに参加し、開発に積極的に貢献しています。プロジェクトメンバーやコミッターについてはこちらを参照ください。
昨年 Microsoft は、エンジニアリング作業に 6,000 時間以上を費やし、オープン ソース コミュニティとのパートナーシップを通じて、Hadoop プロジェクトのさまざまな部分にコードを提供しつつ革新を進めてきました。さらに、Hadoop のコミッターを擁しており、また Hadoop の Apache ワーキング グループの議長を務めるのは Microsoft 社員の Chris Douglas です。
–David Campbell (Microsoft 社員、CTO)
https://azure.microsoft.com/ja-jp/solutions/hadoop/
HDInsight とは
Microsoft は HDInsight という Hadoop のディストリビューションを Azure 上で PaaS 型で提供しています。HDInsight は 100% Apache Hadoop をベースとしているため、現在 Hadoop を利用されている方、またはこれから Hadoop を学ぶ方ともに共通の Hadoop のスキルで HDInsight を利用することができます。
HDInsight は、オンデマンドでテラバイトからペタバイトに至るまで、どんな量のデータでも処理できます。任意のタイミングで任意の数のノードを迅速に作成できます。使用したコンピューティングやストレージに対してのみ料金が発生します。
HDInsight は Hortonworks Data Platform(HDP) で構成されており、Hadoop ユーザーの皆様に使い慣れた Linux または Hortonworks 社と共同で移植した Windows 環境を選択できます。
*HDInsight の Apache Spark 版は Linux 環境のみで動作します。 
HDInsight の Hadoop エコシステム
HDInsight は 100% Apache Hadoop をベースとしていますので、各種 Hadoop のエコシステムが利用可能です。下表は HDInsight に含まれる Hadoop エコシステムの一部です。
*本記事の投稿時点では HDInsight のバージョンは 3.4 (HDP2.4) です。 
詳細な情報はこちら (https://azure.microsoft.com/ja-jp/documentation/articles/hdinsight-component-versioning/) をご確認ください。
HDInsight のデプロイ
HDInsight は Microsoft Azure のポータル画面からデプロイすることができます。
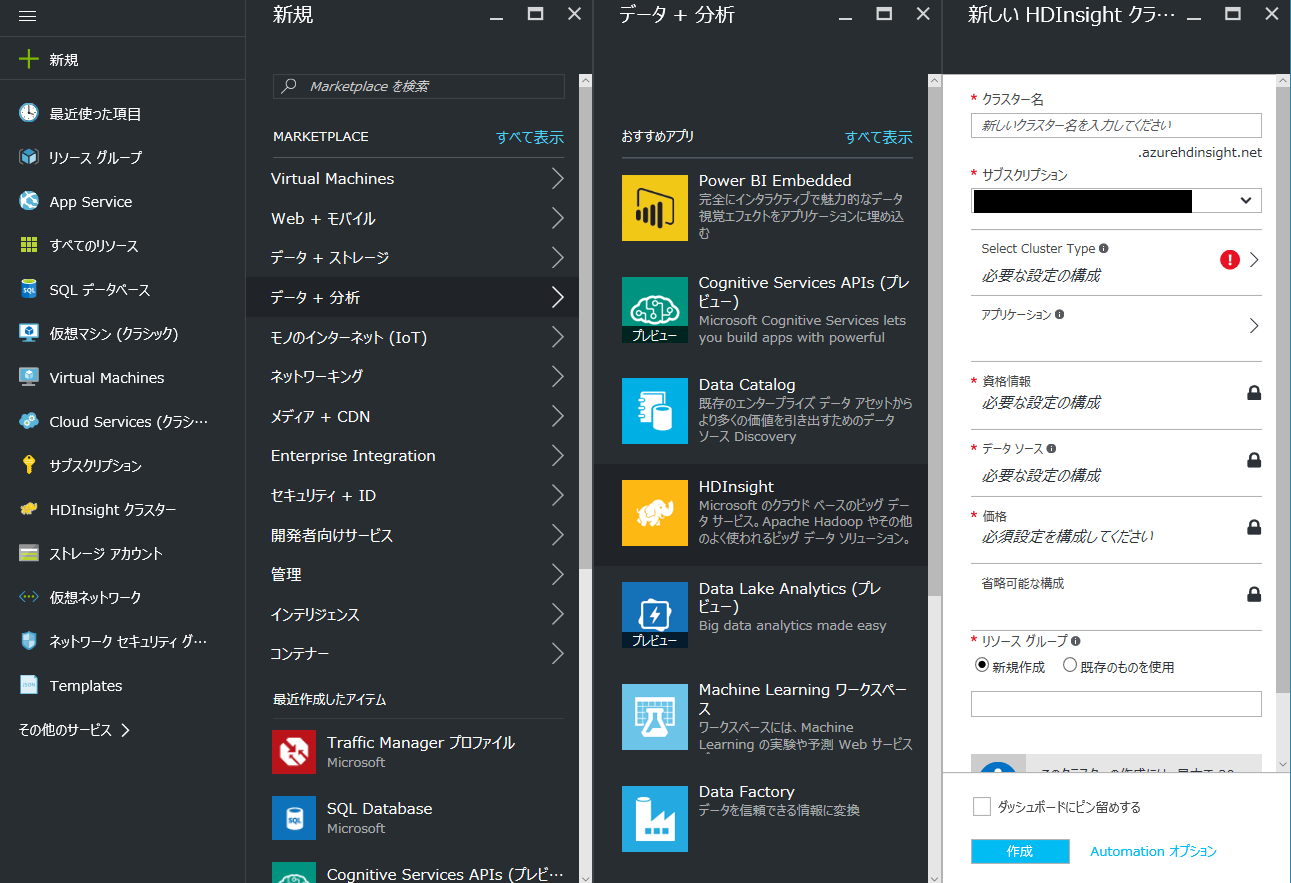
各パラメータについて解説します。
クラスター名
Hadoop クラスターの名前を設定します。管理画面のアクセス先などにも使用されます。
クラスター タイプ
クラスターの種類、OS、バージョンを指定します。ここでは以下のように設定しています。
| クラスターの種類 | Spark |
| オペレーティング システム | Linux (Spark 版は Linux のみ) |
| バージョン | Spark1.6.1 (HDI3.4) |
| Cluster Tier | STANDARD *PREMIUM (プレビュー) を選択すると Microsoft R Server が含まれ、R スクリプトを MapReduce または Spark で動かすことができます。 |
クラスタータイプ設定画面
資格情報
管理画面 (Ambari) 等の管理画面の資格情報や、SSH の資格情報を指定します。SSH はパスワード認証または公開鍵認証を設定できます。こちらの例では公開鍵認証を設定しています。
データソース
HDInsight は HDFS の代わりに Azure Storage (Blob) を標準ストレージとして使用します(もちろん HDFS を使用することもできます)。ここでは新しくストレージアカウントを作成しています。[既存のコンテナーの選択] はストレージアカウント内に作成されるコンテナー名です。この中に各種データが格納されることになります。
[クラスター AAD ID] は Microsoft Azure の BigData サービスである Azure Data Lake Store と連携するための設定です。ここでは設定を省略します。
価格
ワーカーノードのノード数と、ヘッドノードおよびワーカーノードのサイズを選択します(Cluster Tier を PREMIUM にした場合は Microsoft R Server 用のノードも選択します)。デプロイ後はワーカーノードのノード数を柔軟に変更することは可能ですが、ノードのサイズを変更することはできませんのでご注意ください。ここではヘッドノード、ワーカーノードともに D12 v2 を選択しています。
省略可能な構成
[省略可能な構成] では必要に応じて HDInsight を配置する 仮想ネットワーク の選択、規定 (SQL Database) 以外の外部メタストア、デプロイ時に実行するスクリプト操作、追加のストレージ アカウントの設定ができます。ここでは仮想ネットワークを設定しています。設定する仮想ネットワークは事前に作成しておく必要があります。
スクリプト操作では追加でコンポーネントをインストールする際に便利です。詳細は スクリプト アクションを使用して Linux ベースの HDInsight クラスターをカスタマイズする をご参照ください。例えば Hue、Solr、Giraph のインストールなどがあり、サンプルのスクリプトもご紹介しています。なお、スクリプトアクションは HDInsight デプロイ後の実行中のクラスターに対して適用することもできます。
設定が完了したら [作成] を押してデプロイを開始します。デプロイにはおよそ30~40分程度の時間がかかります。
今回は HDInsight をデプロイする流れをご紹介いたしました。次回はデプロイした HDInsight へのアクセス方法や、Hive、Spark の利用についてご紹介します。
関連記事
- Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (1)
- Microsoft Azure の Hadoop ディストリビューション HDInsight を使ってみよう! (2)