Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Microsoft Data Migration Blog
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
AccessToSQL
Access to SQL
Azure Database
Azure Database for MySQL
Azure Database for MySQL - Flexible Server
Azure Database Migration Service
Azure Database Migration Service hybrid mode
Azure Data Studio
AzureSQL
Azure SQL
Azure SQL Database
azuresqldb
Azure SQL DB
Azure SQL Managed Instance
Azure SQL VM
DAMT
databases
DataMigration
Data Migration
DB2toSQL
DB2 to SQL
DEA
DMA
DM Guide
DMS
DM Team
Microsoft
MicrosoftAzure
Microsoft Ignite 2023
Migration
Migrations to Azure
Migration to Azure
MySQL
MySQLtoSQL
MySQL to SQL
Oracle
OracletoSQL
Oracle to SQL
OSSDB
SKU
sql
SQL migration
SQL Server
SQL Server Data Migration
SQL Server on Azure Virtual Machines
SQL Server on Azure VMs
SSMA
SybaseToSQL
Sybase to SQL
- Home
- Azure Data
- Microsoft Data Migration Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed
284

2,273
3,111

2,404
2,737

3,358
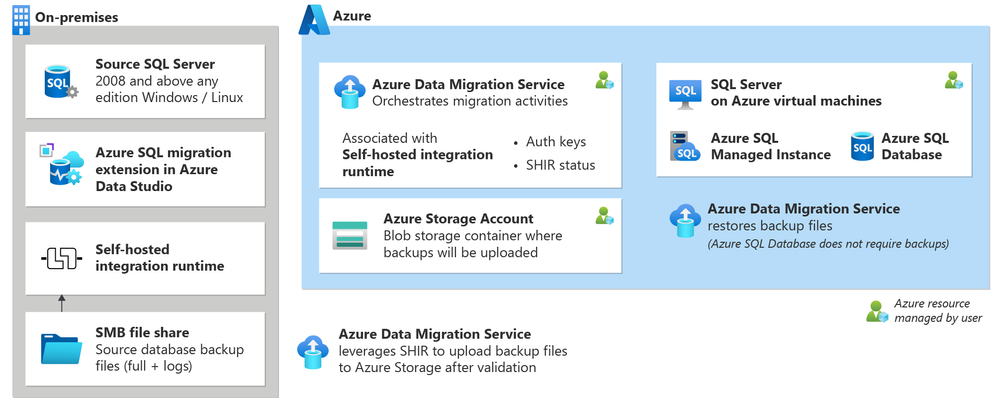
4,942

5,744
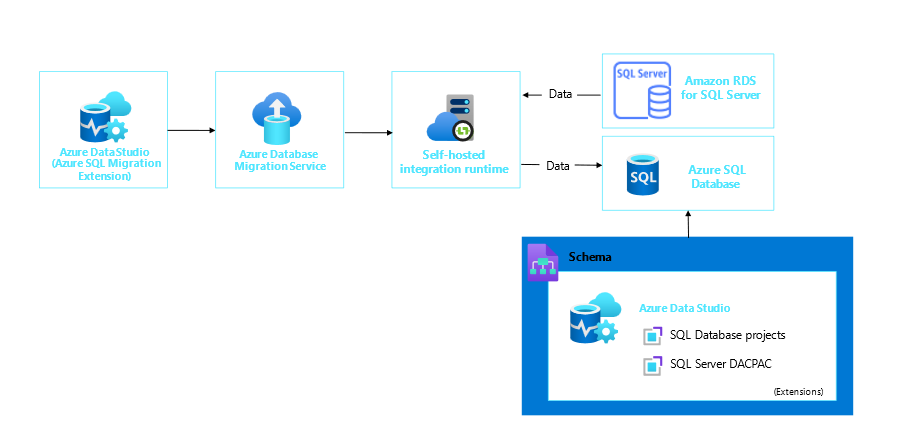
9,435

5,987
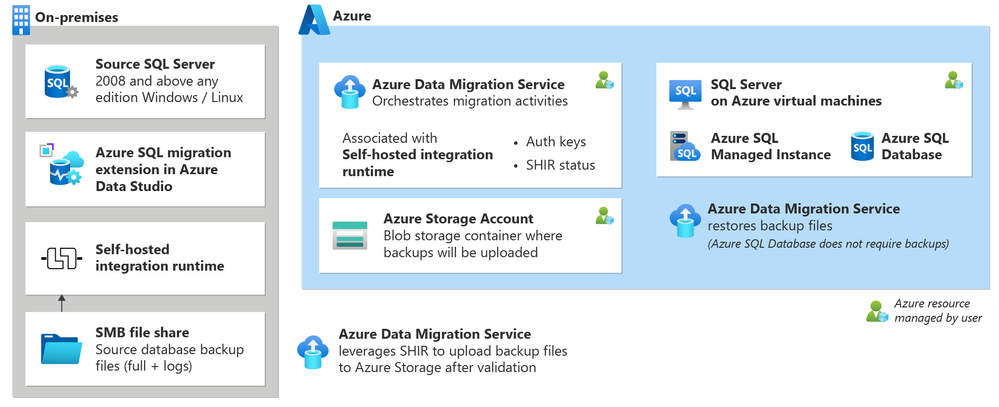
5,485

6,244

15.7K

13.7K

5,914

22.7K
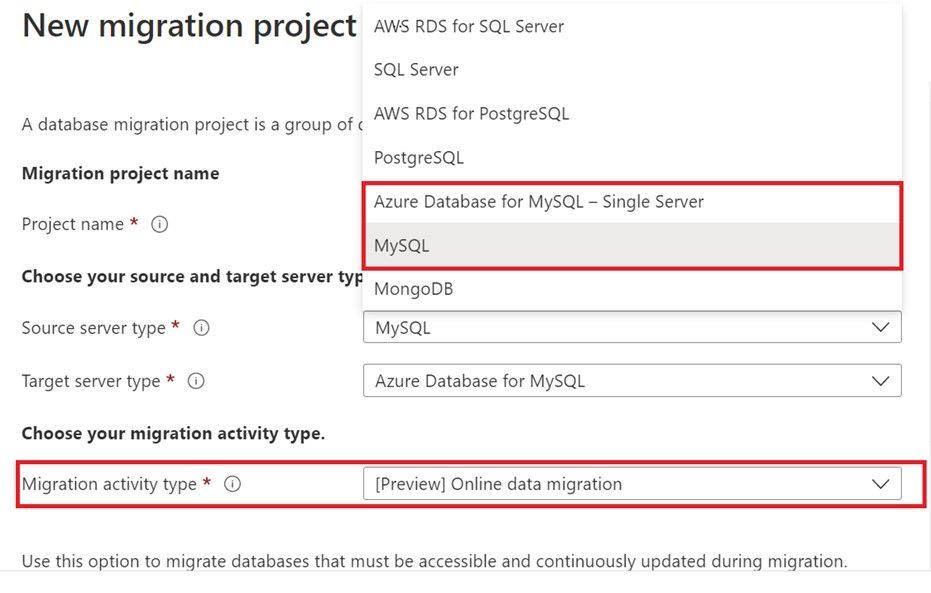
6,154
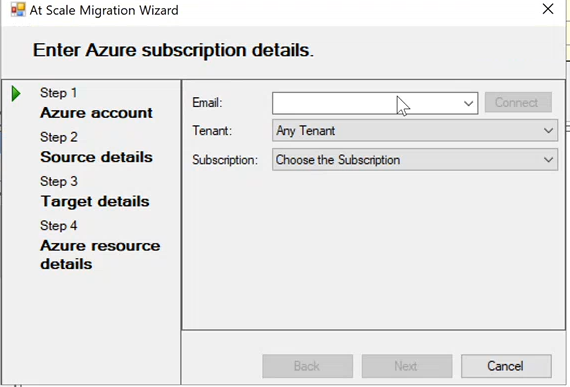
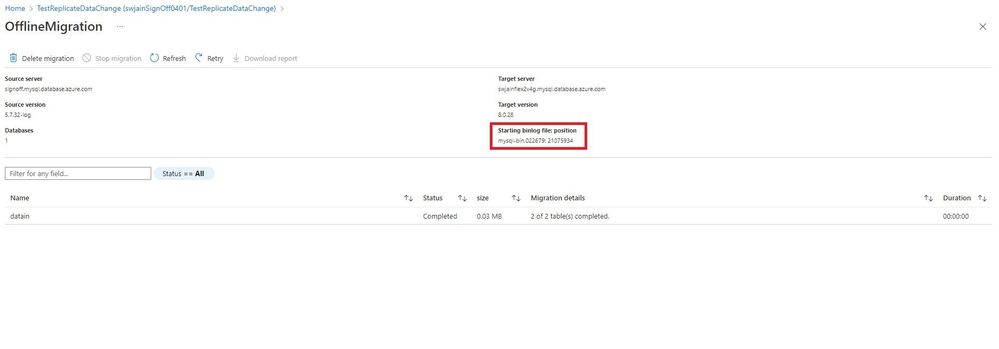

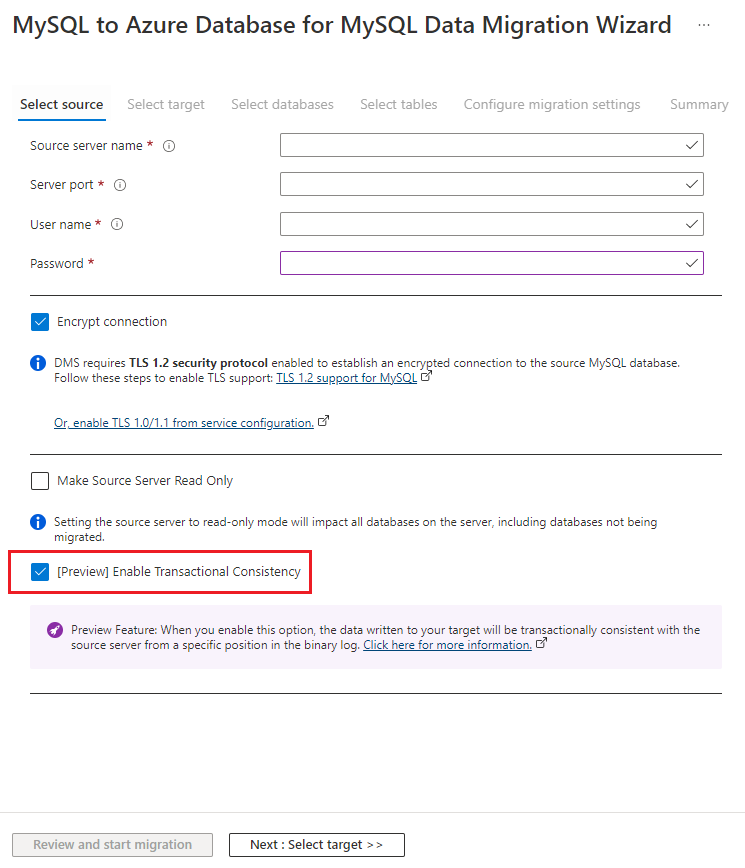

6,361


5,582
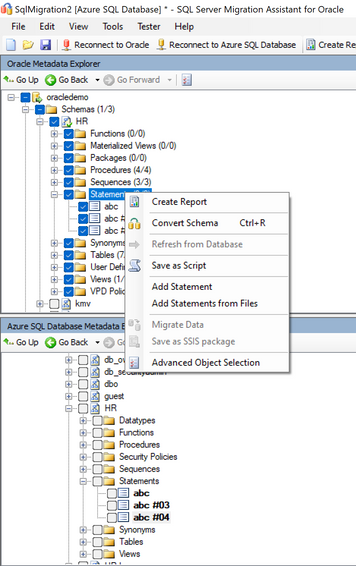

8,993
Latest Comments