Scaling your Data Warehouse up for load and down for query
By Charles Feddersen, Solution Architect
Introduction:
Azure SQL Data Warehouse provides a Massive Parallel Processing (MPP) relation platform to support Data Warehouse workloads. The platform enables true PaaS elasticity by design to grow or shrink the amount of compute in a scale-out architecture. Whether in a single or multi-node configuration, the user experience remains the same as a single connection to what is logically a single relational Data Warehouse. This post details how this scalability can be applied to optimizing loading data, which can be a common performance pain point for existing single server data warehouse implementations.
One of the common challenges that I hear when I speak to customers is that their data is simply not available fast enough. There can be a number of factors contributing to this, including slow upstream systems, or time difference issues where the end of "data day" is designated by a time zone that is hours behind where a given analyst is running reports, creating a misalignment between batch window and business requirements. Both of these issues are a little trickier to fix, and I'm not going to try and solve for those with this article.
However, another common issue often the sheer amount of time it takes to load the data into reporting solutions. Systems that were fit for purpose 6 or 12 months ago are unable to scale due to one-off (and often unpredictable) spikes in data, gradual growth in data volumes as a by-product of a growing business, or new scenarios coming online. As a result, administrators and developers need to look for workarounds to accelerate load performance.
Developers may spend hours baselining systems and tuning for the last performance gain when the actual approach fundamentally won't scale. For example, common approach to baselining the performance of a Data Flow in SQL Integration Services ETL packages was to attach a Row Count component to the Data Flow Source so as to understand the read throughput of the source file / database. With this as the benchmark of throughput, developers could start to build out the transformations and validate that the package execution was efficient. Generally speaking, this was often relatively straight forward and it quickly identified that the bottleneck occurred when writing into a single table in SQL Server as the relational Data Source Destination.
This challenge is not isolated to SQL Integration Services or any other ETL tool. The same limiting factors also extend to other data import approaches such as BULK INSERT or BCP where the throughput into a single database table is constrained regardless of the size of server.
I think I've seen pretty much every workaround in the book. Custom applications to split source files into multiple chunks to enable concurrent parallel load processes. Conditional Split or Balanced Data Distributor components in SSIS to route the data flow to different tables, sometimes with a subsequent PARTITION SWITCH if the data was split along a partitioning boundary.
The Solution:
Tuning has its limits, and to really take the next step we need to consider a new underlying architecture that support scale out principals. To reduce the manual development effort and workarounds required to consume files into the Data Warehouse, we need an approach that inherently supports scale-out parallelism at all levels from the source to the relational store. Ideally, this approach will also provide elasticity to grow over time as required. We can solve for this with Azure SQL Data Warehouse + PolyBase, and in doing so, also pick up some added benefits scale-down elasticity and Data Warehouse pause. PolyBase provides a parallel data transfer mechanism to read the underlying Azure Storage distributed file system, and therefor enables high data I/O throughput into the database.
When deploying an Azure SQL Data Warehouse instance and database, the underlying platform actually creates 60 physical SQL databases. Subsequently, when a developer creates a table (either distributed by a hash on a column, or round robin) the underlying engine will create one physical table in each of these databases, which ultimately provides 60 physical tables to load data into.
More information on table creation can be found here: https://msdn.microsoft.com/en-US/library/mt203953.aspx/
This underlying database / table implementation is a critical design aspect of the scale-out Data Warehouse that solves for the scale limit of loading a single database table. To both the developer and end user it appears as a single table, however under the covers the distributed optimizer understands how to query across these tables, move data as necessary, and return the correct result. The significance of this is that by issuing a simple reconfiguration command, the platform can scale to accelerate data load + query without any modifications to existing database or ETL application logic!
We actually define the performance of the DW service using Data Warehouse Units (DWU's) which provide a method to scale the instances that underpins the 60x database files. When defining the size of the DW service, we specify the number of DWU's to allocate. The screenshot below illustrates this feature in the Azure portal, however it is also possible to resize the DW using a SQL command or PowerShell. Resize takes about 60 seconds. Yes – 60 seconds.
Additional scaling information is here: https://azure.microsoft.com/en-us/documentation/articles/sql-data-warehouse-performance-scale/
One way to illustrate the compute scale being applied to the DW service is to run the command DBCC PDW_SHOWSPACEUSED against a service with 100 and 200 DWU configurations. The CREATE TABLE statement below simple creates an empty table that is round robin distributed. The outcome of this statement, as described above, is 60 physical tables under the covers.
CREATE TABLE ScaleTest (
Col1 int not null)
WITH (DISTRIBUTION = ROUND_ROBIN)
100 DWU – Single Node ID assigned to all distributions of my table
DBCC PDW_SHOWSPACEUSED(ScaleTest)
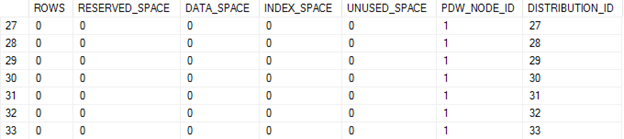
200 DWU – Distribution 31 (and the remainder up to 60) is now assigned to a secondary node
DBCC PDW_SHOWSPACEUSED(ScaleTest)

As you can see above, when I grew the service to 200 DWU, a new node was bought online, and some of my "distributions" (in reality, databases) were bound to that node. Basically, I went from one SQL instance to two without moving any data.
So, given that we can scale the amount of compute bound to storage, let's take a look at the performance characteristics of ingesting data from a Blob using PolyBase in Azure SQL DW. This is similar in concept to using BULK INSERT in SQL Server in that we invoke the load from the file system by using T-SQL commands. The difference with PolyBase is that we are first required to define our External Data Source, External File Format, and External Table to the apply a CREATE TABLE statement to. In BULK INSERT a lot of these file parameters are defined within the BULK INSERT statement itself.
More information regarding the creation of External Tables and the supporting objects can be found here: https://azure.microsoft.com/en-us/documentation/articles/sql-data-warehouse-load-with-polybase/
I used the following statement to load data from the Blob (represented here as the External Table "LineItemExternal") into a new table called LineItemDW. This table is created automatically as part of this statement execution. It must not exist prior to running this command.
CREATE TABLE LineItemDW
WITH (DISTRIBUTION = HASH(l_orderkey), CLUSTERED COLUMNSTORE INDEX)
AS
SELECT
l_orderkey
,l_partkey
,l_suppkey
,l_linenumber
,l_quantity
,l_extendedprice
,l_discount
,l_tax
,l_returnflag
,l_linestatus
,l_shipdate
,l_commitdate
,l_receiptdate
,l_shipinstruct
,l_shipmode
FROM
LineItemExternal -- <= EXTERNAL TABLE, DEFINITION POINTS TO BLOB
For the purpose of illustration, I'm simply going to use TPC-H lineitem data and evaluate the load time across different DWU configurations. I omitted the l_comment field from the load. The graph below illustrates the improving load performance as the DW services is scaled.
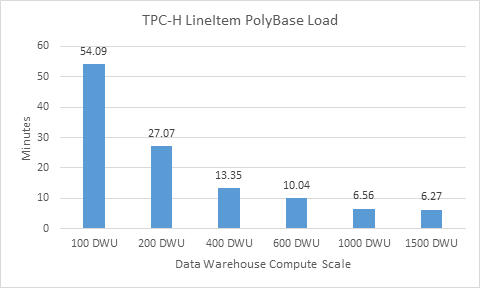
In this scenario I am loading a 72 GB file from Blob Storage into the Data Warehouse. Technically – I'm actually loading it almost twice in. An initial step will read all columns into a temp table, and then a second step with perform an INSERT INTO … SELECT under the cover of just the columns I selected. We currently don't have a mechanism to filter columns from the source, so the file consumption to temp table is an all or nothing proposition. As described above, each DWU performance metric represents a resize of the DW service only using the portal slider – no DDL modification of any sort.
So – if you ever needed to load a 72 GB flat file into a SQL relational DW in under 7 minutes with a ColumnStore index applied, ready to query – this is a suitable approach…
You can see that for the initial size growth the performance is pretty much linear, and then as the service is scaled into larger configurations, the improvement becomes almost negligible. This is most likely being caused by throughput limitations from the Blob Storage account. All up though, this has successfully showcased that we can scale our load a lot more easily using the native scale out platforms as Blob Storage and Azure SQL Data Warehouse. When combining with PolyBase, we facilitate parallel data transfer rates to support performance DW loading. No need to break files apart, spin up multiple processes manually, design complex database file configurations, or distribute data flows into separate physical tables to switch them back together later. The underpinning platforms take care of that, so developers just develop.
In an actual implementation scenario, it's possible that the query workload will not require such high levels of CPU utilization, so there may be a cost optimization available to reduce the service scale post-load window that still meets the performance requirements of end users. This scale up / scale down scenario is very powerful for optimizing the cost / performance profile of your DW service, and enabling developers to maintain a level of service as data volumes continue to grow.