Event Hubs / Stream Analytics / AzureML / PowerBI End-to-End demo – Part II (Real-time Prediction)
By Alexander Turetsky, Solution Architect
In the previous post about a real-time prediction demo I've talked about data ingestion and preparation process, technologies used and implementation tips. Now I'm going to describe the "heart" of the demo – the prediction process.
I have used the Predictive Maintenance template published by AzureML team. The template describes three different modeling solutions that could be used in predictive maintenance scenarios – they answer slightly different questions. For the demo I've chosen the regression model – to predict the remaining useful life of an engine. For very detailed explanation of the modeling process, feature selection and engineering, model training and model deployment please refer to the machine learning blog on TechNet. I've followed the process step-by-step making small adjustments (to exclude functionality related to the other two modeling solutions presented in the original template and to leave feature engineering to the calling client). As the result I got a Web Service published that takes as an input all three current settings and twenty-one sensor readings of an engine along with their running average and standard deviation; the output of the web service includes the predicted remaining useful life of the engine. Now I need to start using this web service in real time as engine records flow through the system.
This is how the ML web service invocation fits into the architecture: 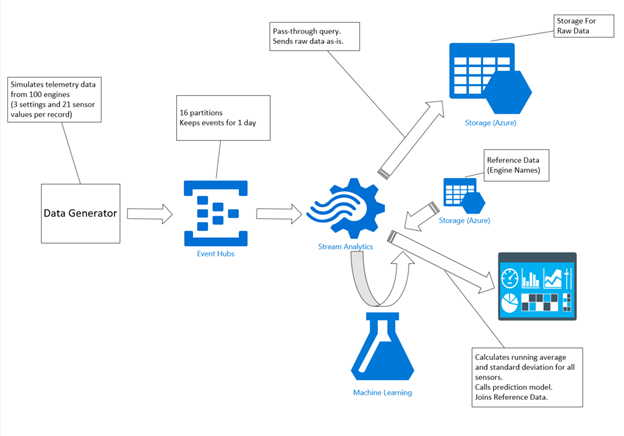
The StreamAnalytics job (described in the previous post) processes a record from EventHubs, does all of the required feature engineering (calculates running average and standard deviation for all settings and sensor values), invokes the ML web service and sends results to the PowerBI visualization dashboard.
It looks very logical and straight-forward in theory; unfortunately, in practice it is not very easy to implement. Stream Analytics service has a new functionality to enable calling ML model right from a query; this functionality is in private preview right now (a detailed blog post from Stream Analytics Program Manager about this upcoming feature can be found here - https://blogs.msdn.com/b/streamanalytics/archive/2015/05/24/real-time-scoring-of-streaming-data-using-machine-learning-models.aspx). So until this feature is publicly available I had to find and implement a workaround. So the actual architecture diagram looks like this:
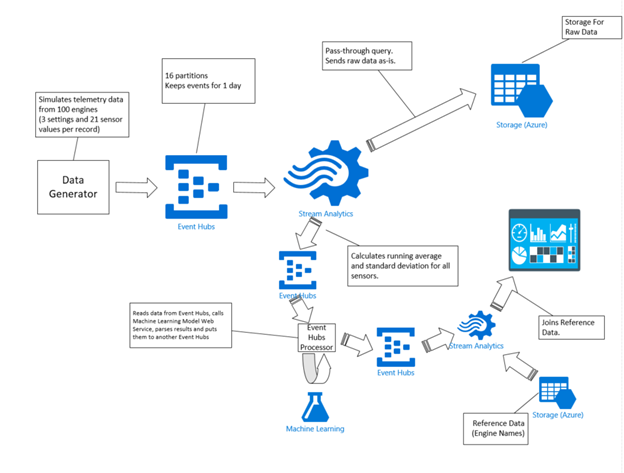
StreamAnalytics job sends raw and calculated data to another EventHubs and there is a .NET console application that reads the data from the event hub, makes a call to the Web Service and sends the results to yet another instance of EventHubs. This application can run either on your laptop or on a Virtual Machine you launch in Azure (IaaS) or as a Worker Role or a WebJob (PaaS). And the second instance of Stream Analytics job consumes the data from there, joins it with static reference data and sends the final results to PowerBI dashboard. Of course, the custom .NET application could also do the reference data lookups and send the results directly to PowerBI (using PowerBI REST APIs) but the idea was to minimize custom code and demonstrate out of the box functionality of the Cortana Analytics suite.
The .NET console application has three main functionalities:
- Read data from an event hub
- Call ML model via a web service
- Send results to another event hub
Sending to an event hub functionality was already described in the previous post; this application has a similar implementation (the only different is the payload of an event that needs to be sent).
Event Hubs has two primary models for event consumption: direct receivers and high-level abstractions such as EventProcessorHost. I found it much easier and more convenient to use EventProcessorHost; when you decide to implement direct receivers you have to do your own coordination of access to partitions, do special handling for load distribution, worry about thread safety and so on, while all of these comes with EventProcessorHost. There is an excellent post about how to better use this class available here and here.
You first need to implement IEventProcessor interface that has three pretty self-explaining methods: OpenAsync, CloseAsync and ProcessEventsAsync.
class StreamEventProcessor : IEventProcessor
{
public Task OpenAsync(PartitionContext context) {}
public async Task CloseAsync(PartitionContext context, CloseReason reason) {}
public async Task ProcessEventsAsync(PartitionContext context, IEnumerable<EventData> messages) {}
}
An instance of this class would be created by EventProcessorHost for each partition of the Event Hubs and only this instance would be used to process all events from that specific partition. When events arrive for the partition ProcessEventsAsync method of the registered instance of IEventProcessor will be called and all further calls to this method of the instance would be blocked – even the message retrieval from the partition still happens in background, all the messages will queue up until the ongoing call to ProcessEventsAsync finishes.
Every call to ProcessEventsAsync can potentially process a collection of events – the input parameter of the method is IEnumerable<EventData> . It is recommended not to make this method very heavy, it is better that the method finishes relatively fast. If the functionality you want to implement can be parallelized you should use the concept of consumer groups (you can use a consumer group and a lightweight implementation of IEventProcessor to perform each part of the functionality; the Standard tier of Event Hub allow you to have up to 20 consumer groups).
EventProcessorHost would also manage events offset in the Event Hubs for every partition, an instance of the IEventProcessor just needs to instruct the EventProcessorHost to periodically update it. This is very important if for some reason you need to restart reading – you do not want to start all other from the beginning of the stream of events. You can make a checkpoint after every processed event, or you can choose to do it less frequently (say every so often) – this would improve performance, but you need to be aware that some of the events could be processed by your code more than once.
In order to register an IEventProcessor you need to use RegisterEventProcessorAsync<T>() method of EventProcessorHost – in this case the DefaultEventProcessorFactory<T> factory would be used to instantiate the interface implementation. In the demo I needed to pass initialization parameters to my implementation and it was not possible with the default factory – so I had to implement my own EventProcessorFactory and use RegisterEventProcessorFactoryAsync method.
class StreamEventProcessorFactory : IEventProcessorFactory
{
private readonly string paramerterToPass;
public StreamEventProcessorFactory(string param)
{
parameterToPass = param;
}
public IEventProcessor CreateEventProcessor(PartitionContext context)
{
return new StreamEventProcessor(parameterToPass);
}
}
… … …
eventProcessorHost. RegisterEventProcessorFactoryAsync(
new StreamEventProcessorFactory("myParameterToPass"));
The implementation of ProcessEventsAsync method is very straight-forward. As described in the previous post the payload of every event sent to Event Hubs is a JSON representation of a plain data object – so it could be easily parsed into a Dictionary:
string data = Encoding.UTF8.GetString(eventData.GetBytes());
Dictionary<string, string>[] dataDictionaries =
JsonConvert.DeserializeObject<Dictionary<string, string>[]>(data);
When you deploy the trained Predictive Maintenance model as a web service, the ML studio would give you a lot of useful information how to use the web service and even would provide some examples. Among other things you would see what kind of an input the service expects and what format of an output it produces. You can construct the required input format from the parsed event data dictionary using C# closures:
class StringTable
{
public string[] ColumnNames { get; set; }
public string[][] Values { get; set; }
}
static readonly string[] RequestColumnNames = new string[] { << names of all properties >> };
public static object FormRequest(Dictionary<string, string> request)
{
return new
{
Inputs = new Dictionary<string, StringTable>()
{{
"input1",
new StringTable()
{
ColumnNames = RequestColumnNames,
Values = new string[][] {
RequestColumnNames.Select(
col => request.ContainsKey(col) ? request[col] : ""
).ToArray()
}
}
}},
GlobalParameters = new Dictionary<string, string>() { }
};
}
The HTTP client to interact with the web service could be constructed like this:
var client = new HttpClient();
const string apiKey = <<the API key for the web service from ML studio>>;
client.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", apiKey);
client.BaseAddress = new Uri(<<web service Request URI from ML studio>>);
And finally, the call to the deployed web service could look like this:
HttpResponseMessage response =
await client.PostAsJsonAsync("", FormRequest(dataDictionary));
A successful call to the web service would return status code 200 (OK). In this case you can parse the response, get the predicted value and send it further to the next Event Hubs.
There are also a number of status codes indicating different types of problems. Usually it is a good idea to have a special handling for error code 503 (service unavailable) – this usually indicates that the request to the web service was throttled and you should repeat the same request in some time.