POC - Part 3: Crawling an External Web Site with the SharePoint 2010 Web Crawler
In the interest of brevity (and lack of time) I am just going to cover what we need to do to crawl a web site for inclusion in the search engine. The configuration we will use will cause the crawler to only read the content found on the explicitly selected site. That means if you tell the crawler to crawl https://www.some-domain.com and the home page to that site has a link to another site the links to the other site will be ignored by the SharePoint 2010 web crawler.
Crawl before you walk. Walk before you run. Run so you don't get eaten by a lion.
Let's get to it.
What we are doing this time
- Create a new content source: a crawl of an arbitrary external web site
- Run the crawl
- Check the results
The Short Version
- Create a new content source: a crawl of an arbitrary external web site
- Start --> SharePoint 2010 Central Administration --> Manage Service Applications --> FASTContent --> Crawling --> Content Sources --> New Content Source
- Name: Web site crawl
- Content Source Type: Web sites
- Start Addresses: [your favorite web site. Just one for now. Preferably not a commercial site. How about your favorite blogger? Preferably something small]
- Crawl Settings: Only crawl within the server of each start address
- Crawl Schedule: None
- Start Full Crawl: [check] Start full crawl of this content source
- Start --> SharePoint 2010 Central Administration --> Manage Service Applications --> FASTContent --> Crawling --> Content Sources --> New Content Source
- Run the crawl
- Click OK
- Wait
- Refresh
- Repeat b and c until the status of the crawl is Idle
- Check the results
- Go to https://intranet.contoso.com/fast-search
- Search for #
- Take a look at the Site refiner. You should see one additional site: the site you crawled.
The Long Version
There really isn't a Long Version. The basic configuration of the web crawler is straightforward and pretty much covers it. If you need different behavior then please add complexity incrementally so that you can confirm the behavior you are looking for. Perhaps we will cover crawl rules in a future post.
In my case I crawled a WordPress site that added an alleged 948 pages to the index. That, of course, is a lie. There are a lot of duplicate documents as the crawler crawls the originating page and well as any links on that page; that means tag links, RSS feed information and as well as links associated with pages. A link is a link is a link even if the content it points to had been crawled before.
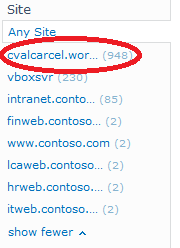
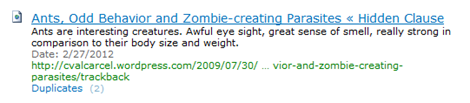
Notice that many of the documents have duplicates.
Also take a look at the Company refiner.
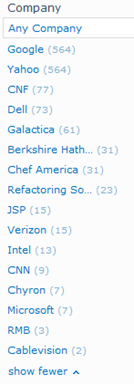
Those companies were not there before. The Company entity extractor works automatically and has done its job in this case (sometimes too well as names like Galactica and JSP are listed as companies when they are not).
Are there wrinkles to this? Absolutely! But remember: the point of this series is to get you up and running as quickly as possible. Once something simple works add complexity slowly (and that's two adverbs worth of advice).
How do we do this with PowerShell? Read Part 3a.
Next: Crawling SharePoint 2010 using the SharePoint 2010 Connector
References
Add, edit or delete a content source (FAST Search Server 2010 for SharePoint)