Designing for Cloud-Optimized Architecture
I wanted to take the opportunity and talk about the cloud-optimized architecture, the implementation model instead of the popular perceptions around leveraging cloud computing as a deployment model. This is because, while cloud platforms like Windows Azure can run a variety of workloads, including many legacy/existing on-premises software and application migration scenarios that can run on Windows Server; I think Windows Azure’s platform-as-a-service model offers a few additional distinct technical advantages when we design an architecture that is optimized (or targeted) for the cloud platform.
Cloud platforms differ from hosting providers
First off, the major cloud platforms (regardless how we classify them as IaaS or PaaS) at the time of this writing, impose certain limitations or constraints in the environment, which makes them different from existing on-premises server environments (saving the public/private cloud debate to another time), and different from outsourced hosting managed service providers. Just to cite a few (according to my own understanding, at the time of this writing):
- Amazon Web Services
- EC2 instances are inherently stateless; that is, their local storage is non-persistent and non-durable
- Little or no control over infrastructure that are used beneath the EC2 instances (of course, the benefit is we don’t have to be concerned with them)
- Requires systems administrators to configure and maintain OS environments for applications
- Google App Engine
- Non-VM/OS instance-aware platform abstraction which further simplifies code deployment and scale, though some technical constraints (or requirements) as well. For example,
- Stateless application model
- Requires data de-normalization (although Hosted SQL will mitigate some concerns in this area)
- If the application can't load into memory within 1 second, it might not load and return 500 error codes (from Carlos Ble)
- No request can take more than 30 seconds to run, otherwise it is stopped
- Read-only file system access
- Windows Azure Platform
- Windows Azure instances are also inherently stateless – round-robin load balancer and non-persistent local storage
- Also due to the need to abstract infrastructure complexities, little or no control for the underlying infrastructure is offered to applications
- SQL Azure has individual DB sizing constraints due to its 3-replica synchronization architecture
Again, just based on my understanding, and really not trying to paint a “who’s better or worse” comparative perspective. The point is, these so-called “differences” exist because of many architectural and technical decisions and trade-offs to provide the abstractions from the underlying infrastructure. For example, the list above is representative of most common infrastructure approaches of using homogeneous, commodity hardware, and achieve performance through scale-out of the cloud environment (there’s another camp of vendors that are advocating big-machine and scale-up architectures that are more similar to existing on-premises workloads). Also, the list above may seem unfair to Google App Engine, but on the flip side of those constraints, App Engine is an environment that forces us to adopt distributed computing best practices, develop more efficient applications, have them operate in a highly abstracted cloud and can benefit from automatic scalability, without having to be concerned at all with the underlying infrastructure. Most importantly, the intention is to highlight that there are a few common themes across the list above – stateless application model, abstraction from infrastructure, etc.
Furthermore, if we take a cloud computing perspective, instead of trying to apply the traditional on-premises architecture principles, then these are not really “limitations”, but more like “requirements” for the new cloud computing development paradigm. That is, if we approach cloud computing not from a how to run or deploy a 3rd party/open-source/packaged or custom-written software perspective, but from a how to develop against the cloud platform perspective, then we may find more feasible and effective uses of cloud platforms than traditional software migration scenarios.
Windows Azure as an “application platform”
Fundamentally, this is about looking at Windows Azure as a cloud platform in its entirety; not just a hosting environment for Windows Server workloads (which works too, but the focus of this article is on cloud-optimized architecture side of things). In fact, Windows Azure got its name because it is something a little different than Windows Server (at the time of this writing). And that technically, even though the Windows Azure guest VM OS is still Windows Server 2008 R2 Enterprise today, the application environment isn’t exactly the same as having your own Windows Server instances (even with the new VM Role option). And it is more about leveraging the entire Windows Azure platform, as opposed to building solely on top of the Windows Server platform.
For example, below is my own interpretation of the platform capabilities baked into Windows Azure platform, which includes SQL Azure and Windows Azure AppFabric also as first-class citizens of the Windows Azure platform; not just Windows Azure.
![image_thumb[13]](https://msdntnarchive.blob.core.windows.net/media/MSDNBlogsFS/prod.evol.blogs.msdn.com/CommunityServer.Blogs.Components.WeblogFiles/00/00/00/84/18/metablogapi/2555.image_thumb13_09F3FDF1.png "image_thumb[13]")
I prefer using this view because I think there is value to looking at Windows Azure platform holistically. And instead of thinking first about its compute (or hosting) capabilities in Windows Azure (where most people tend to focus on), it’s actually more effective/feasible to think first from a data and storage perspective. As ultimately, code and applications mostly follow data and storage.
For one thing, the data and storage features in Windows Azure platform are also a little different from having our own on-premises SQL Server or file storage systems (whether distributed or local to Windows Server file systems). The Windows Azure Storage services (Table, Blob, Queue, Drive, CDN, etc.) are highly distributed applications themselves that provide a near-infinitely-scalable storage that works transparently across an entire data center. Applications just use the storage services, without needing to worry about their technical implementation and up-keeping. For example, for traditional outsourced hosting providers that don’t yet have their own distributed application storage systems, we’d still have to figure out how to implement and deploy a highly scalable and reliable storage system when deploying our software. But of course, the Windows Azure Storage services require us to use new programming interfaces and models (REST-based API’s primarily), and thus the difference with existing on-premises Windows Server environments.
SQL Azure, similarly, is not just a plethora of hosted SQL Server instances dedicated to customers/applications. SQL Azure is actually a multi-tenant environment where each SQL Server instance can be shared among multiple databases/clients, and for reliability and data integrity purposes, each database has 3 replicas on different nodes and has an intricate data replication strategy implemented. The Inside SQL Azure article is a very interesting read for anyone who wants to dig into more details in this area.
Besides, in most cases, a piece of software that runs in the cloud needs to interact with data (SQL or no-SQL) and/or storage in some manner. And because data and storage options in Windows Azure platform are a little different than their seeming counterparts in on-premises architectures, applications often require some changes as well (in addition to the differences in Windows Azure alone). However, if we look at these differences simply as requirements (what we have) in the cloud environment, instead of constraints/limits (what we don’t have) compared to on-premises environments, then it will take us down the path to build cloud-optimized applications, even though it might rule out a few application scenarios as well. And the benefit is that, by leveraging the platform components as they are, we don’t have to invest in the engineering efforts to architect and build and deploy highly reliable and scalable data management and storage systems (e.g., build and maintain your own implementations of Cassandra, MongoDB, CouchDB, MySQL, memcarche, etc.) to support applications; we can just use them as native services in the platform.
The platform approach allows us to focus our efforts on designing and developing the application to meet business requirements and improve user experience, by abstracting away the technical infrastructure for data and storage services (and many other interesting ones in AppFabric such as Service Bus and Access Control), and system-level administration and management requirements. Plus, this approach aligns better with the primary benefits of cloud computing – agility and simplified development (less cost as a result).
Smaller pieces, loosely coupled
Building for the cloud platform means designing for cloud-optimized architectures. And because the cloud platforms are a little different from traditional on-premises server platforms, this results in a new developmental paradigm. I previously touched on this topic with my presentation at JavaOne 2010, then later on at Cloud Computing Expo 2010 Santa Clara; just adding some more thoughts here. To clarify, this approach is more relevant to the current class of “public cloud” platform providers such as ones identified earlier in this article, as they all employ the use of heterogeneous and commodity servers, and with one of the goals being to greatly simplify and automate deployment, scaling, and management tasks.
Fundamentally, cloud-optimized architecture is one that favors smaller and loosely coupled components in a highly distributed systems environment, more than the traditional monolithic, accomplish-more-within-the-same-memory-or-process-or-transaction-space application approach. This is not just because, from a cost perspective, running 1000 hours worth of processing in one VM is relatively the same as running one hour each in 1000 VM’s in cloud platforms (although the cost differential is far greater between 1 server and 1000 servers in an on-premises environment). But also, with a similar cost, that one unit of work can be accomplished in approximately one hour (in parallel), as opposed to ~1000 hours (sequentially). In addition, the resulting “smaller pieces, loosely coupled” architecture can scale more effectively and seamlessly than a traditional scale-up architecture (and usually costs less too). Thus, there are some distinct benefits we can gain, by architecting a solution for the cloud (lots of small units of work running on thousands of servers), as opposed to trying to do the same thing we do in on-premises environments (fewer larger transactions running on a few large servers in HA configurations).
I like using the LEGO analogy below. From this perspective, the “small pieces, loosely coupled” fundamental design principle is sort of like building LEGO sets. To build bigger sets (from a scaling perspective), with LEGO we’d simply use more of the same pieces, as opposed to trying to use bigger pieces. And of course, the same pieces can allow us to scale down the solution as well (and not having to glue LEGO pieces together means they’re loosely coupled). 

But this architecture also has some distinct impacts to the way we develop applications. For example, a set of distributed computing best practices emerge:
- asynchronous processes (event-driven design)
- parallelization
- idempotent operations (handle duplicity)
- de-normalized, partitioned data (sharding)
- shared nothing architecture
- fault-tolerance by redundancy and replication
- etc.
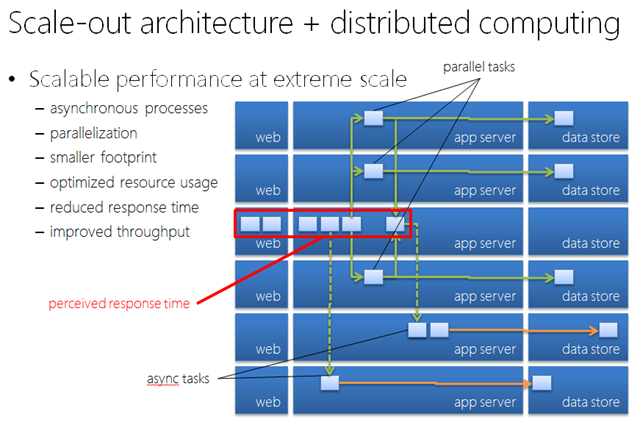
Asynchronous, event-driven design – This approach advocates off-loading as much work from user requests as possible. For example, many applications just simply incur the work to validate/store the incoming data and record it as an occurrence of an event and return immediately. In essence it’s about divvying up the work that makes up one unit of work in a traditional monolithic architecture, as much as possible, so that each component only accomplishes what is minimally and logically required. Rest of the end-to-end business tasks and processes can then be off-loaded to other threads, which in cloud platforms, can be distributed processes that run on other servers. This results in a more even distribution of load and better utilization of system resources (plus improved perceived performance from a user’s perspective), thus enabling simpler scale-out scenarios as additional processing nodes and instances can be simply added to (or removed from) the overall architecture without any complicated management overhead. This is nothing new, of course; many applications that leverage Web-oriented architectures (WOA), such as Facebook, Twitter, etc., have applied this pattern for a long time in practice. Lastly, of course, this also aligns well to the common stateless “requirement” in the current class of cloud platforms.
Parallelization – Once the architecture is running in smaller and loosely coupled pieces, we can leverage parallelization of processes to further improve the performance and throughput of the resulting system architecture. Again, this wasn’t so prevalent in traditional on-premises environments because creating 1000 additional threads on the same physical server doesn’t get us that much more performance boost when it is already bearing a lot of traffic (even on really big machines). But in cloud platforms, this can mean running the processes in 1000 additional servers, and for some processes this would result in very significant differences. Google’s Web search infrastructure is a great example of this pattern; it is publicized that each search query gets parallelized to the degree of ~500 distributed processes, then the individual results get pieced together by the search rank algorithms and presented to the user. But of course, this also aligns to the de-normalized data “requirement” in the current class of cloud platforms, as well as SQL Azure’s implementation that resulted in some sizing constraints and the consequent best practice of partitioning databases, because parallelized processes can map to database shards and try not to significantly increase the concurrency levels on individual databases, which can still degrade overall performance.
Idempotent operations – Now that we can run in a distributed but stateless environment, we need to make sure that same process that gets routed to multiple servers don’t result in multiple logical transactions or business state changes. There are processes that could and prefer duplicate transactions, such as ad clicks; but there are also processes that don’t want multiple requests be handled as duplicates. But the stateless (and round-robin load-balancing in Windows Azure) nature of cloud platforms requires us to put more thoughts into scenarios such as when a user manages to send multiple submits from a shopping cart, as these requests would get routed to different servers (as opposed to stateful architectures where they’d get routed back to the same server with sticky sessions) and each server wouldn’t know about the existence of the process on the other server(s). There is no easy way around this, as the application ultimately needs to know how to handle conflicts due to concurrency. Most common approach is to implement some sort of transaction ID that uniquely identifies the unit of work (as opposed to simply relying on user context), then choose between last-writer or first-writer wins, or optimistic locking (though any form of locking would start to reduce the effectiveness of the overall architecture).
De-normalized, partitioned data (sharding) – Many people perceive the sizing constraints in SQL Azure (currently at 50GB – also note it’s the DB size and not the actual file size which may contain other related content) as a major limitation in Windows Azure platform. However, if a project’s data can be de-normalized to a certain degree, and partitioned/sharded out, then it may fit well into SQL Azure and benefit from the simplicity, scalability, and reliability of the service. The resulting “smaller” databases actually can promote the use of parallelized processes, perform better (load more distributed than centralized), and improve overall reliability of the architecture (one DB failing is only a part of the overall architecture, for example).
Shared nothing architecture – This means a distributed computing architecture in which each node is independent and self-sufficient, and there is no single point of contention across the system. With data sharding and maintained in many distributed nodes, the application itself can and should be developed using shared-nothing principles. But of course, many applications need access to shared resources. It is then a matter of deciding whether a particular resource needs to be shared for read or write access, and different strategies can be implemented on top of a shared nothing architecture to facilitate them, but mostly as exceptions to the overall architecture.
Fault-tolerance by redundancy and replication – This is also “design for failures” as referred to many cloud computing experts. Because of the use of commodity servers in these cloud platform environments, system failures are a common thing (hardware failures occur almost constantly in massive data centers) and we need to make sure we design the application to withstand system failures. Similar to thoughts around idempotency above, designing for failures basically means allowing requests to be processed again; “try-again” essentially.
Lastly, each of the topic areas above is worthy of an individual article and detailed analysis; and lots of content are available on the Web that provide a lot more insight. The point here is, each of the principles above actually has some relationship with, and dependency on, the others. It is the combination of these principles that contribute to an effective distributed computing, and cloud-optimized architecture.