OpenXML & VSTO & VBA - Finding a reliable mechanism for reading the correct value of CharactersWithSpaces 'extended-properties' in Word documents [part 1/2].
This article is split across two blog posts and this is part #1 .. use this link to go to part #2. There are many scenarios when we have to know exactly how many words, pages, paragraphs or characters are found in a certain document: > we might be developing a tool which searches through files; If we want to add OpenXML files to its list of known formats, then it would be nice it we could offer a progress estimation when users search inside a document (example: display [x% completed out of yyyy word count); > or you may need to count the number of words for a company that translates documents, to know how much they need to charge customers; > in case some public institution builds a web-page where documents can be uploaded; If there is a requirement / limitation that forces any uploaded document to contain up to xxxx words, then we need a code that reliably reads this information; .. and there are many other scenarios where counting words comes in handy. Let's assume that we have to count the number of words in an OpenXML Word document on a server. If the 'word counter' tool runs on the server side, then you can't use COM automation, as this action would place you in an unsupported scenario.
So what alternative do we have? Answer: use OpenXML API. A quick search on the internet reveals this code snippet:
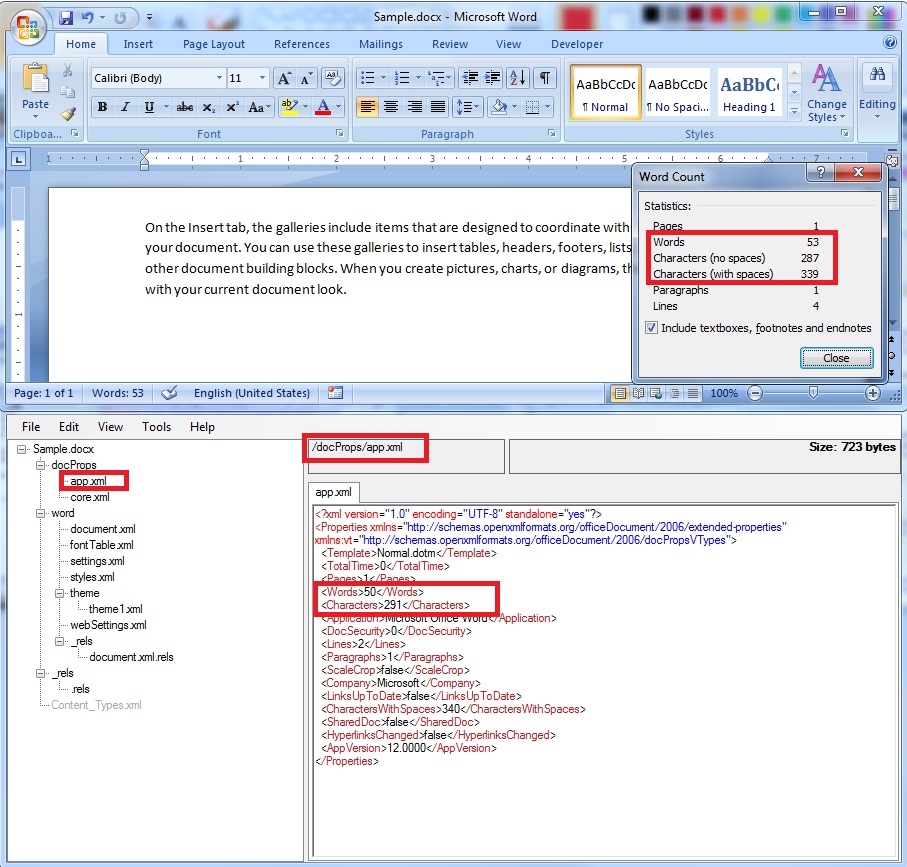
But will it work as expected? Does it report the same number of words as displayed inside MS Word editor? Answer: Yes, it works but it's not reliable. Sometimes it gives the expected results, sometimes it returns slightly different numbers .... Triggering the Word statistics mismatch problem 1. Just create a new Word document, type " =rand(1) " (without the quotes), then press Enter key;2. Save it file using .docx type, then close it;3. Open the file using an OpenXML editor, or rename the document from .docx to .zip, open the docProps folder and then edit the app.xml file; Note the values of these XML items: > Pages; > Words; > Characters; > Lines; > Paragraphs; > CharactersWithSpaces;4. Close the editor, or if you renamed the file to .zip, restore its original extension; Open it again in Word;5. On the Review tab, in the Proofing group, click Word Count;6. Compare the statistics in the Word Count dialog with those noted from the app.xml file;
Result: we easily notice that the numbers are different ...7. Close the document again, you should be prompted to Save it. Go ahead and click OK to store the updated document information;8. Open its internal OpenXML structure and this time you should see that the numbers match; The Word Count difference is by-design > MS Word has a set of tasks that are scheduled to run when the application is in idle mode; > the Compute Document Statistics task has a low priority; > when the user changes content inside a document, Word just estimates the number of characters, paragraphs ... etc. The data is stored in a special field inside a documents and is marked as 'estimated'; > when we save a file and the document statistics task has not yet been executed, we just get an estimated value inside the xmlProperties.GetElementsByTagName("CharactersWithSpaces") OpenXML field; Our Product Group's developers were notified about the inconsistency between OpenXML and COM ObjectModel results and they replied that it was their decision to store approximate values in OpenXML. The main reason why things are happening in this way is performance. For a small file, the time needed to compute Word Count statistics is not a problem, but for a document with thousands of pages, it may take several seconds or even minutes. If Word application was set to compute all the statistics in real-time, before a save (or more often), the end-users would surely complain about application hangs during saves. So the Product Group decided to compromise between speed and accuracy. As you have noticed, the difference between the estimated values and the real values are not bigger than 1 ~ 2% which is more than enough for regular users.
Can we obtain 100% reliable statistics? Method #1: The OpenXML data can be forced to update: when Word receives a query about the statistics (through the Ribbon graphical interface or the VBA ObjectModel), it computes those results and always reports the correct numbers. The only difficult part is finding a way to trigger the update every time, so that we are sure that the information stored in the file is up to data. Advantages: > easy to implement; > OpenXML code is very simple; > works for all kinds of input files ... even very complex ones (containing embedded charts, shapes, nested tables ..etc); Disadvantages: > we can only force the Word Count update if we rely on a VBA / VSTO add-in installed on the client-side; > somehow, the automated Statistics Update Add-in has to be deployed to all end-users; Method #2: Write our own OpenXML code and count the words ourselves. Advantages: > no need for 'helper' tools; Disadvantages: > because the OpenXML format is VERY complex, the code will run reliably only for basic input files; If you want to extend the program to be able to handle all kinds of input documents you will find that the complexity of the code increases up to the point where it is not fasible to continue with the project (you will very likely be forced to write individual code rules for targeting all kinds of exceptions and special conditions for XML text tags, that may appear in different combinations); Hmmm ... something tells me that when you read the lines about the disadvantages of using Method #2, some wheels already started turning in your head. You must be thinking: "there must be some trick to get all the words ... ".OK, let me show you how you get started on this path ... if you decide that this approach is right for you, then you can further develop my sample code:
Code sample from below can be downloaded from this link.
How the code works? > first of all, we have to start with a very basic sample file and we must try to get the code to run for that input;> for my tests, I used a plain text document, containing 2 paragraphs (produced using the =rand(1) command); The 2nd paragraph was truncated .. it contains a special Unicode character: » which is needed to demonstrate an issue that is very likely to be encountered, when building a reliable program that counts characters or words;
> we need analyze the internal structure of an OpenXML file; There are several OpenXML viewers available, but I used the one that comes with the SDK: OpenXML Productivity Tool;
> a WordprocessingML document contains a body element (named w:body) that contains all paragraph (w:p)structures. Each paragraph contains one or more text runs (named w:r). Each text run contains one or more text nodes (named w:t).
> I am not going to explain the first part of the sample code which handles the selection of each XML node of text, because the article Manipulating Word 2007 Files with the Open XML Format API (Part 1 of 3) does a much better job; > once we found a way to loop over each <w:t>structure ( foreach (XmlNode textnode in textnodes) ), we can quickly compute the number of characters; If we do a good job, we will get exactly the same value as the one stored in ExtendedFilePropertiesPart.CharactersWithSpaces XML package structure, when the document is forced to update its Statistics numbers; > there are many things which can make our count result in a different number of characters; A complex document contains many hidden formatting characters ... shapes, tables, fields and formatting (bullets, TOC, citations) ... even simple HYPERLINK fields will make the issue noticeable; If we don't ensure that all those characters are detected and summed or discarded, our count will be inaccurate; > my sample code is built to detect the easiest problem we might encounter while counting: the character encoding; > this problem is not noticeable with simple input files; But when the code tries to parse paragraph #2, it will encounter a character which is not part of the ASCII character set; > when counting characters, I tried to convert them into their byte code equivalent, then I used a variable which increases in value whenever a non-empty byte code (0) is encountered; > but, I soon realized that for some characters, my count was producing bad results; I traced the error back to the function which was translating characters to bytes: Encoding.ASCII.GetBytes; > when I switched to using String.ToCharArray() , I got the expected results;
> you can also see this issue, if you put a breakpoint on the foreach (string strWd in strWords) instruction and step through the code until you have to process the 2nd paragraph; Whenever the code encounters a character which is not part of the ASCII code, it encodes it as a "?"; > after switching to String.ToCharArray() , we get the Unicode character byte code, so we no longer have unknown character codes; But once we decide to use Unicode, we have to keep into account that all the characters occupy 2 bytes; So we must substract the 2nd byte from our count, if it is 0; > at the end, after counting all characters (including spaces), we can also find the number of words; > searching through the byte array, trying to detect words separated by one or more spaces can be tricky; So I used a faster method (which could be unreliable): I am dividing my total number of characters by a ratio found by experimenting (in my example, I am dividing by 6);
> please note that not all spaces have the same Unicode value; The regular space character has the Unicode value of [00 32], but we also encounter other types: [00 160] = non-breaking space (see GetBytesCount_Unicode(string str) function, where if you wish to count only non-blank characters, you have to enable this line: if (bytes[i] != 0 && bytes[i] != 32 && bytes[i] != 160) );The second part of this article demonstrates how you can move the word count operation on the client side, just by writing a few lines of VBA code. In this way, the end-user will update his document just before he's done working with it, so that your software does nothing else than read the CharactersWithSpaces extended property.
Thank you for reading my article! Bye :-)
|