VSTO & VBA - How to troubleshoot Excel memory and performance problems caused by inefficient code loops
When working with Excel, a developer sometimes has to search, read or write some cell values and these operations are usually done inside repetitive loop structures.
Everything seems to work fast enough for small input files, but once we scale up the design, things can complicate and the end-user experience is severely affected. On the other hand, the developer takes precautions not to trigger unnecessary events and actions inside the Excel application by adhering to the best practices listed here:
Excel VBA Performance Coding Best Practiceshttps://blogs.office.com/b/microsoft-excel/archive/2009/03/12/excel-vba-performance-coding-best-practices.aspx ================================================================================ ...... Turn Off Everything But the Essentials While Your Code is RunningThis optimization explicitly turns off Excel functionality you don't need to happen (over and over and over) while your coderuns. Note that in the code sample below we grab the current state of these properties, turn them off, and then restore themat the end of code execution.One reason this helps is that if you're updating (via VBA) several different ranges with newvalues, or copy / pasting from several ranges to create a consolidated table of data, you likely do not want to have Excel takingtime and resources to recalculate formulas, display paste progress, or even redraw the grid, especially after every singleoperation (even more so if your code uses loops). Just one recalculation and one redraw at the end of your code execution isenough to get the workbook current with all your changes.Here's some sample code that shows how and what to shut offwhile your code runs. Doing this should help improve the performance of your code: 'Get current state of various Excel settings; put this at the beginning of your codescreenUpdateState = Application.ScreenUpdatingstatusBarState = Application.DisplayStatusBarcalcState = Application.CalculationeventsState = Application.EnableEventsdisplayPageBreakState = ActiveSheet.DisplayPageBreaks 'note this is a sheet-level setting'turn off some Excel functionality so your code runs fasterApplication.ScreenUpdating = FalseApplication.DisplayStatusBar = FalseApplication.Calculation = xlCalculationManualApplication.EnableEvents = FalseActiveSheet.DisplayPageBreaks = False 'note this is a sheet-level setting'>>your code goes here<<'after your code runs, restore state; put this at the end of your codeApplication.ScreenUpdating = screenUpdateStateApplication.DisplayStatusBar = statusBarStateApplication.Calculation = calcStateApplication.EnableEvents = eventsStateActiveSheet.DisplayPageBreaks = displayPageBreaksState 'note this is a sheet-level settingHere's a quick description for each of these settings:Application.ScreenUpdating: This setting tells Excel to not redraw the screen while False. The benefit here is that youprobably don't need Excel using up resources trying to draw the screen since it's changing faster than the user can perceive.Since it requires lots of resources to draw the screen so frequently, just turn off drawing the screen until the end of your codeexecution. Be sure to turn it back on right before your code ends.Application.DisplayStatusBar: This setting tells Excel to stop showing status while False. For example, if you use VBA tocopy/paste a range, while the paste is completing Excel will show the progress of that operation on the status bar. Turning offscreen updating is separate from turning off the status bar display so that you can disable screen updating but still providefeedback to the user, if desired. Again, turn it back on right before your code ends execution.Application.Calculation: This setting allows you to programmatically set Excel's calculation mode."Manual" (xlCalculationManual) mode means Excel waits for the user (or your code) to explicitly initiate calculation."Automatic" is the default and means that Excel decides when to recalculate the workbook (e.g. when you enter a newformula on the sheet). Since recalculating your workbook can be time and resource intensive, you might not want Exceltriggering a recalc every time you change a cell value. Turn off calculation while your code executes, then set the mode back.Note: setting the mode back to “Automatic” (xlCalculationAutomatic) will trigger a recalc.Application.EnableEvents: This setting tells Excel to not fire events while False. While looking into Excel VBA performanceissues I learned that some desktop search tools implement event listeners (probably to better track document contents as itchanges). You might not want Excel firing an event for every cell you're changing via code, and turning off events will speed upyour VBA code performance if there is a COM Add-In listening in on Excel events. (Thanks to Doug Jenkins for pointing thisout in my earlier post).ActiveSheet.DisplayPageBreaks: A good description of this setting already exists: https://support.microsoft.com/kb/199505 (Thanks to David McRitchie for pointing this out).Read/Write Large Blocks of Cells in a Single OperationThis optimization explicitly reduces the number of times data is transferred between Excel and your code. Instead of loopingthrough cells one at a time and getting or setting a value, do the same operation over the whole range in one line, using anarray variable to store values as needed.For each of the code examples below, I had put random values (not formulas) intocells A1:C10000.Here's a slow, looping method: Here's the fast version of that code: Note: I first learned of this concept by reading a web page by John Walkenbach found here: https://www.dailydoseofexcel.com/archives/2006/12/04/writing-to-a-range-using-vba/A previous Excel blog entry by Dany Hoter also compares these two methods, along with a selection / offset method as well:https://blogs.msdn.com/excel/archive/2008/10/03/what-is-the-fastest-way-to-scan-a-large-range-in-excel.aspx...which leads me to my next point.Avoid Selecting / Activating ObjectsNotice that in the above-referenced blog post, the selection method of updating a rangewas the slowest. This next optimization minimizes how frequently Excel has to respond to the selection changing in the workbook by minimizing the selection changing as much as possible. ... ... |
These best practices help improve the execution speed in VBA, but when we develop code using VSTO solutions (stand-alone COM automation solutions, VSTO add-ins ..) things will get even worse.
COM Interop https://en.wikipedia.org/wiki/COM_Interop ================================================================================================= COM Interop is a technology included in the .NET CLR that enables COM objects to interact with .NET objects, and vice versa. COM Interop aims to provide access to the existing COM components without requiring that the original component be modified. It tries to make the .NET types equivalent to the COM types. In addition, COM Interop allows COM developers to access managed objects as easily as they access other COM objects. The .NET Framework creates a type library and special registry entries when a component is registered. It provides a specialized utility ( |
Because of the overhead introduced by the Interop layer (https://msdn.microsoft.com/en-us/library/kew41ycz(v=vs.71).aspx "Interoperability marshaling is the process of packaging parameters and return values into equivalent data types as they move to and from COM objects"), an application which uses faulty designed code may crash with out of memory errors or may encounter random errors in parts of the code which run perfectly fine on other machines.
I am going to list here a couple of the most common sources for COM automation errors related to repeated calls to Excel's object model.
First of all, we have to understand that unlike VBA where everything happens in synchronization with the parent Office application, in COM automation scenarios there is an additional layer which acts like a wrapper: it sends COM calls to the Office application (unmanaged code) and gives the results back to the calling code (managed .NET programs). In this case the Interop Layer has to allocate and perform garbage collection for different memory objects used for sending data back and forth and sometimes the Office application cannot keep up with the caller and we run into these issues:
I have researched the ‘System.OutOfMemoryException’ and ‘ContextSwitchDeadlock’ issue which keep triggering when you user large data sets. It looks like they have been encountered by other programmers when executing long iteration on Excel objects:
OutOfMemoryException
Visual Studio Developer Center > Visual Studio Forums > Visual Studio Tools for Office > OutOfMemoryExceptionhttps://social.msdn.microsoft.com/Forums/en-US/vsto/thread/d11c67eb-3ad4-4e36-8707-37e671a37279================================================================================================= I've created an excel document level customization. It consists of a set of data sheets that are loaded by an ETL process and few display sheets that present the data and manage the read/write operations to the data sheets. Now you might question the reason for choosing Excel as the front end rather than having a client/server .NET app windows or web, but this is a tactical solution that is meant to leverage the functionality of Excel, most notably formulas which I would not want to re-produce in a custom app. The solution works fine small data sets, however with large data sets I frequently run into OutOfMemoryException being thrown e.g.: System.OutOfMemoryException: Exception of type 'System.OutOfMemoryException' was thrown. at System.RuntimeType.RuntimeTypeCache.MemberInfoCache`1.AddMethod(RuntimeTypeHandle declaringType, RuntimeMethodHandle method, CacheType cacheType) at System.RuntimeType.RuntimeTypeCache.GetMethod(RuntimeTypeHandle declaringType, RuntimeMethodHandle method) at System.RuntimeType.GetMethodBase(RuntimeTypeHandle reflectedTypeHandle, RuntimeMethodHandle methodHandle) at System.Runtime.Remoting.Messaging.Message.GetMethodBase() at System.Runtime.Remoting.Messaging.Message.get_MethodBase() at Microsoft.VisualStudio.Tools.Applications.RealProxyImpl.Invoke(IMessage msg) at System.Runtime.Remoting.Proxies.RealProxy.PrivateInvoke(MessageData& msgData, Int32 type) at Microsoft.Office.Interop.Excel.Range.get_Value2() I've tried to optimize the code to the best of my knowledge e.g. using object[,] instead of Range to read/write data to the Value2 property, but there are certain operations for which I can’t avoid using Excel object e.g. formatting, moving columns. Even Range.Value2 = object[,] throws an OutOfMemoryException for large arrays e.g. 50,000 rows * 200 columns (in the extreme case). Is there a way for me to alleviate the memory pressure that Excel is imposing? Is there a better way for me to code this or destroy the references tot he Excel objects so they are not retained in memory? Would invoking the GC help in any way (I don't see why it would but just in case)? ... It sounds like you have done something in your code that is interfering with the message processing of an STA thread (probably Excel's main UI thread). Typically, people hit this MDA when their code is in a long running loop. If this is what you are doing, see: https://social.msdn.microsoft.com/Forums/en-US/vsto/thread/bf71a6a8-2a6a-4c0a-ab7b-effb09451a89 for an example of how use CoWaitForMultipleHandles within your loop to pump the minimal amount of messages to avoid this MDA. Otherwise, you are doing something else to block the thread without pumping. ... Yes, managing Runtime Callable Wrappers (RCWs) can be tricky. However, depending on what you are doing, you may not need to manage them at all. As you know RCW's will hold a reference to their underlying COM object. When the RCW's finalizer is run, they will release their reference. So when do RCW's get finalized? At a minimum, they get finalized when the AppDomain is torn down. During teardown, all objects are collected regardless of whether they are rooted. Before AppDomain teardown, there are two other ways that RCWs could be finalized. The first would be when the objects are no longer rooted and therefore become eligible for collection. If the GC0 heap fills up, a garbage collection will occur, and those RCWs that are eligible will be finalized. The second way finalization can happen is if you explicitly force a garbage collection by calling GC.Collect. If you do that, any RCWs eligible for collection will be finalized. By calling WaitForPendingFinalizers, you ensure that the finalizer thread has finalized all of the objects in the queue before your thread continues. In addition, as you are aware, you can deterministically force the RCWs to release their reference by calling either Marshal.ReleaseComObject or Marshal.FinalReleaseComObject. The difference between the two calls is this. RCW's have a reference count of their own which gets bumped when the IUnknown is marshalled across AppDomain boundaries. Calling Marshal.ReleaseComObject will only actually release when the RCW reference count goes to zero--otherwise it has the effect of decrementing this internal count. Marshal.FinalReleaseComObject, however, will call the release regardless of what the RCW reference count is. So the real question is when do you need to be explicit about enforcing RCW finalization or calling Marshal.Final/ReleaseComObject? The answer is whenever you can't afford to wait for GC to happen (knowing that it might not occur until shutdown). The two most likely reasons would be if the object is holding onto a resource (such as a file handle) or if memory pressure caused by keeping the object(s) alive was hurting performance. If you know you are going to need to deterministically control the RCW cleanup, the best thing to do is to keep them isolated (and not pass them around) so that you can just call Marshal.FinalReleaseComObject when you are done with them. As long as you can guarantee that you won't try to call into the RCW again after you make that call, then this is a safe approach. This is better than trying to force a GC yourself since doing that will promote any existing objects in the heap to later generations which will mean they will potentially hang around in memory longer than they would have otherwise. That said, the ideal is to do nothing and just let the system take care of everything. Managing this stuff on your own is harder, so be sure you understand your reasons for doing so before you take that on. ... |
We learn from this article that we have to try to clean the allocated memory ourselves if notice memory shortage issues due to do repeated calls to COM objects.
On the other hand, since we are working in a managed environment, if there is not too much memory pressure in the system, then the Garbage Collector may not run for a long time, or it may not run at all. Despite marking a specific object used inside a long loop (such as an Excel Range object which gets the informations stored in cells, one by one; or a Word object used to iterate over the Application.ActiveDocument.Words collection items) as safe for cleanup with Marshal.ReleaseComObject or Marshal.FinalReleaseComObject, this does not guarantee that the memory will actually be freed:
|
The FinalReleaseComObject method releases the managed reference to a COM object. Calling this method is equivalent to calling the ReleaseComObject method in a loop until it returns 0 (zero). When the reference count on the COM object becomes 0, the COM object is usually freed, although this depends on the COM object's implementation and is beyond the control of the runtime. However, the RCW can still exist, waiting to be garbage-collected. |
To make matters worse, these two methods could cause big problems if RCW objects could still be reached by other code from the managed side (the following blog describes issues encountered in VS2010 when working with CCWs, but they relate to the COM Interop's design, so in my oppinion this could apply to Office applications as well):
Marshal.ReleaseComObject Considered Dangerous https://blogs.msdn.com/b/visualstudio/archive/2010/03/01/marshal-releasecomobject-considered-dangerous.aspx ================================================================================================= This post describes a problem we encountered and solved during the development of Visual Studio 2010 when we rewrote some components in managed code. In this post I’ll describe the problem and what we did to solve it. This is a rather lengthy technical discussion and I apologize in advance for its dryness. It’s not essential to understand every detail but the lesson we learned here may be valuable for others working with large “legacy” code bases. What changed?As I mentioned in the Background, we rewrote several components for Visual Studio 2010. Specifically, the window manager, the command bars and the text editor. In previous versions of Visual Studio, these were native components written in C++. In Visual Studio 2010, each was rewritten in managed code using C#. Extensions which plug into Visual Studio communicate with these components through COM interfaces. Moving to managed code doesn’t change how these extensions communicate with platform components. Indeed, that’s the promise of interface based programming – i.e. you don’t need to know implementation details in order to communicate with a component via its interface. In the case of the new editor, it so happens that we introduced a new, managed programming model for new extensions, but even so, we had to keep the existing COM interfaces for older extensions. Managed code and COM are brought together through the magic of COM Interop. Briefly, this allows two things to happen:
Let’s take each of these in turn. (If you already know how COM Interop works, you can skip the following two sections.) Calling COM objects from Managed codeThe Common Language Runtime, CLR or just the “Runtime”, can make a COM object look just like a regular managed object. This is a special kind of object called a “Runtime Callable Wrapper” or RCW. RCWs bridge the managed, garbage-collected world with the native, ref-counted world. An RCW is created when “an IUnknown enters the runtime” (IUnknown is the minimum interface that all COM objects must implement). When does that happen? Usually, as the result of an interop call to a native method which hands back a COM interface. In fact, typically, it’s the result of method call on an existing COM object. Since that sounds a little bit like a “chicken and egg problem”, let me give a concrete example. At the heart of the Visual Studio platform lies the Global Service Provider. This service provider keeps track of services offered up (“proffered”) by components in the system. Other components can request a service by calling the IServiceProvider.QueryService method on the Global Service Provider object. If successful, the service returned to the caller will be another COM object, identified by a pointer to its IUnknown interface. If the component making the QueryService call is managed then, at the point where that pointer enters the Runtime, an RCW is created for the service. Of course, this still begs the question: “How did the managed component get hold of the Global Service Provider?”. The answer is that the Global Service Provider was passed to the managed component by the platform when that component was first initialized. Implementing COM interfaces on managed objectsThe tools and the Runtime make this very easy. To implement a COM interface on a managed object, you first need to locate or create an interop assembly containing the managed equivalent of that COM interface. By referencing that interop assembly from managed code and writing classes which implement those interfaces, you create COM compatible managed classes. There are a few other requirements (e.g. your classes must also be marked as COM visible either at the assembly level or on a per class basis), but otherwise it’s straightforward. When an instance of once of these classes is passed through the interop layer to native code, the CLR creates a COM Callable Wrapper or CCW. The CCW, among other things, preserves all the COM rules about identity and the lifetime of the wrapped object. For example, for as long as at least one native component holds a reference on the CCW, then the underlying managed object cannot be claimed by the Garbage Collector, even if there are no other managed roots. As far as the native code is concerned, it deals with an IUnknown, unaware that the object is really a managed object. Marshal.ReleaseComObject – a problem disguised as a solutionWith that rather lengthy (my apologies) recap of COM Interop out of the way, let me describe the problem. Imagine, for the sake of a simplified example, that you have a component called the “Text Manager”. The Text Manager, as you might guess, handles requests about textual things in an editor. Other components communicate to the text manager via the ITextManager interface with methods such as “GetLines”, or “HighlightWord”. ITextManager is a COM interface. Now imagine that there’s a second component that implements a “Search” facility for finding words in a document. The Search component is written in managed code. Obviously, this Search component will need access to the Text Manager to get its job done, and I’m going to lead you through the scenario of performing a “Find” – once when the Text Manager is implemented in native code, and a second time when the Text Manager is managed. The ‘find’ operation begins with the Search component asking for the Text Manager service via the Global Service Provider. This succeeds and the Search Manager gets back a valid instance of ITextManager. Since, in this first walkthrough, the Text Manager is a native COM object, the IUnknown returned is wrapped by the runtime in an RCW. As far as the Search Manager is concerned, though, it sees ITextManager. It doesn’t know or care (yet) whether the actual implementation is native or managed. The find operation continues with the Search component making various calls through ITextManager to complete its task. When the task is done, the ‘find’ operation exits and life is good. Well… almost. The ITextManager is an RCW and, as such it has the same kind of lifetime semantics as any other managed object – i.e. it will be cleaned up as and when the Garbage Collector runs. If there’s not much memory pressure in the system, then the Garbage Collector may not run for a long time – if at all – and here is where the native and managed memory models clash to create a problem. You see, as far as the Search component is concerned it’s finished with the Text Manager – at least until the next ‘find’ operation is requested. If there were no other components needing the Text Manager, now would be a great time for the Text Manager to be cleaned up. Indeed, if the Search component were written in native code, at the point of exiting the ‘find’ routine, it would call “Release” on the ITextManager to indicate that it no longer needs the reference. Without that final “Release”, it looks like a reference counting leak of the Text Manager – at least until the next garbage collection. This is a special, though not unusual case of non-deterministic finalization. This is just an example, but situations just like it really happened many times during Visual Studio 2005 and 2008 development. The bug reports would say that ‘expensive’ components were being reported as leaked objects, usually at shutdown. The "solution”, as a few people discovered, was to insert a call to “Marshal.ReleaseComObject” at the point where the expensive component (the Text Manager in our example) was no longer needed. The RCW is released, causing its internal reference count to drop by one and, typically releasing the underlying COM object. No more leaked references and problem solved! Well, at least for now, as we’ll see. Regretfully, once this “solution” appeared in the source code of a few components, it spread rapidly as the ‘quick fix’ for leaked components and that’s how we shipped. The trouble started when we began migrating some components from native code to managed code in VS 2010. To explain, I’ll return to the ‘find’ scenario, this time with the Text Manager written in managed code. The Search component, as before, requests the Text Manager service via the Global Service Provider. Again, an ITextManager instance is returned and it’s an RCW. However, this RCW is now a wrapper over a COM object which is implemented in managed code – a CCW. This double wrapping (an RCW around a CCW) is not a problem for the CLR and, indeed, it should be transparent to the Search component. Once the ‘find’ operation is complete, control leaves the Search component and life is good. Except that, on the way out the Search component still calls “Marshal.ReleaseComObject” on the ITextManager’s RCW and, “oops!” we get an ArgumentException with the message “The object's type must be __ComObject or derived from __ComObject.”. You see, the CLR is able to see through the double-wrapping to the underlying component and figure out that the it is really a managed object. There’s really no workaround for this except to find all the places where “ReleaseComObject” was called and remove them. Some have suggested that, before calling ReleaseComObject we should check first if it’s going to succeed by calling “Marshal.IsComObject” but, as we’ll see in the next section there is another, more insidious problem still lurking. Marshal.ReleaseComObject - the silent assassinFor this second problem, we’ll return to our original example, with the Text Manager implemented in native code. Even with the ‘safeguard’ of Marshal.IsComObject, the Search component calls ReleaseComObject and goes on its way. However, the RCW has now been poisoned. As far as the CLR is concerned, by calling ReleaseComObject, the program has declared that the RCW is no longer needed. However, it’s still a valid object, and that means it may be reachable from other managed code. If it is reachable, then the next time ITextManager is accessed from managed code through that RCW, the CLR will throw an InvalidComObjectException with a message of “COM object that has been separated from its underlying RCW cannot be used”. How can that happen? There are several ways - some common and some subtle. The most common case of attempting to re-use an RCW is when the services are cached on the managed side. When services are cached, instead of returning to the Global Service Provider each time the Text Manager (for example) is requested, the code first checks in its cache of previously requested services, helpfully trying to eliminate a (potentially costly) call across the COM interop boundary. If the service is found in the cache, then the cached object (an RCW) is returned to the caller. If two components request the same service, then they will both get the same RCW. Note that this ‘cache’ doesn’t have to be particularly complicated or obvious – it can be as subtle as storing the service in a field (member variable) for later use. I’ve called this use of Marshal.ReleaseComObject the “silent assassin” because, while the problem occurs at the point of the call to ReleaseComObject, it is not detected until later when another component innocently tries to access the poisoned RCW. At first glance, it appears that the second component has a bug, but it does not – the component that called ReleaseComObject is the assassin and ‘he has left the room’. The lesson here is: If you’re tempted to call “Marshal.ReleaseComObject”, can you be 100% certain that no other managed code still has access to the RCW? If the answer is ‘no’, then don’t call it. The safest (and sanest) advice is to avoid Marshal.ReleaseComObject entirely in a system where components can be re-used and versioned over time. While you may be 100% certain of the way the components work today and believe that a ‘poisoned’ RCW could never be accessed, that belief may be shattered in the future when some of those components’ implementations change. |
How to avoid these issues?
There is no universal solution which lets you get away with inefficient loops, it is all about finding the best approach for a specific situation.
For example, a programmer designed an Excel add-in which allowed the end-user to select a couple of cells (the selection was not a single continous block, instead it could span across several separate groups of cells >> areas). These items would get assigned to custom defined objects and then sent to a web-service to be stored in a DataBase.
Everything worked fine for 3000 ~ 4000 ~ 5000 cells, but for more than 10000 items, the code kept failing with the OutOfMemory exception. I tried to use a different approach: get the range (or range subsets called Areas if the user performs a multiple selection) and store it inside an Array structure in the .NET program. Then perform all the sequential operations on that Array object.
In this way, we will create only a couple RCW objects (Excel ranges) corresponding to the areas selected by the end-user, and the search / value read operations would execute much faster than going through the Interop layer for every single cell.
I wrote this algorithm for computing the exact coordinates (start row index, end row index) of an user's selection:
VBA sample – determine the range limits for selection areas
Sub test() Dim rngArea As Range Debug.Print "Selection.Areas " & Application.Selection.Areas.Count Dim i As Integeri = 1For Each rngArea In Application.Selection.Areas Debug.Print "Area #" & i Debug.Print "Start row" & rngArea.Row Debug.Print "Cell count " & rngArea.Cells.Count Debug.Print "Max row " & rngArea.EntireRow.Row + _ rngArea.EntireRow.Rows.Count - 1 & _ vbNewLine i = i + 1Next End Sub |
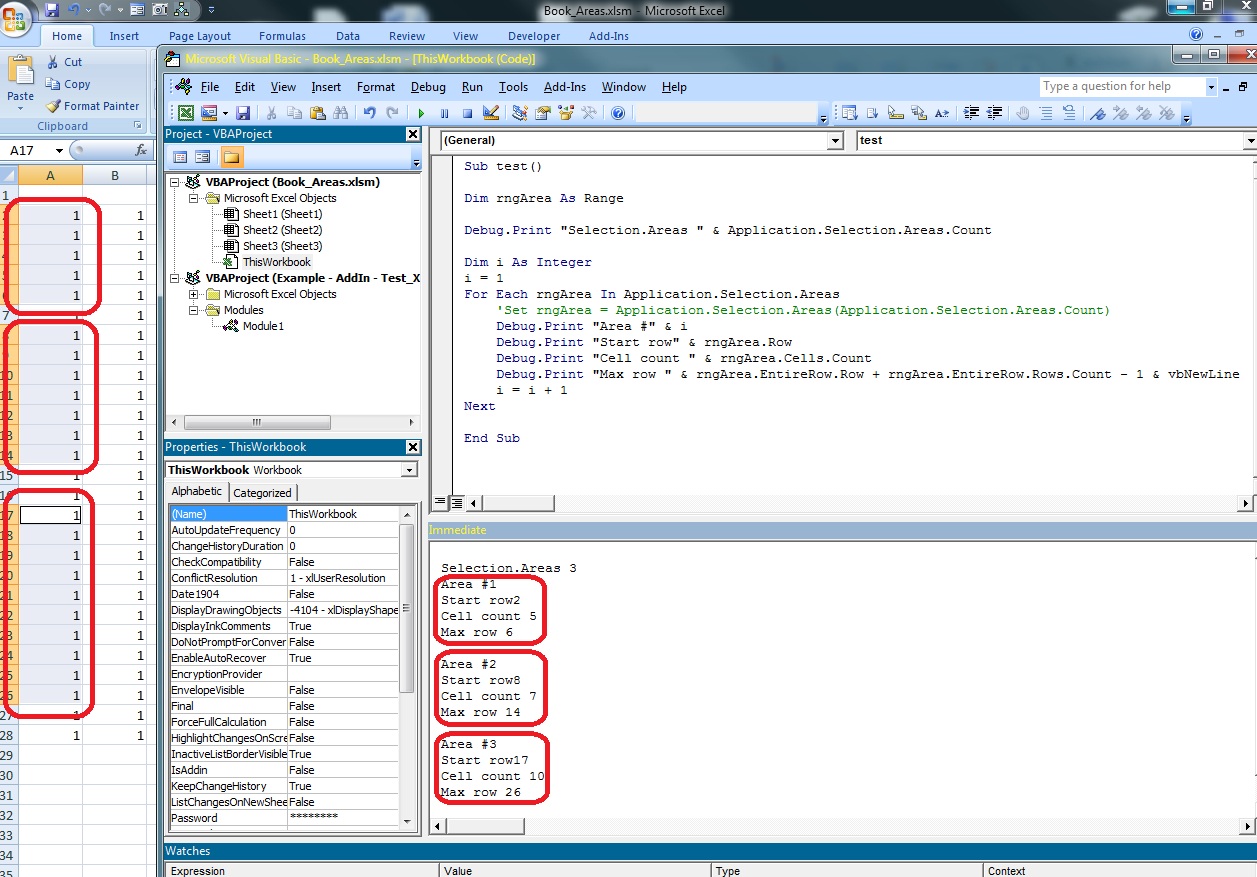
With this information the old and new designs were merged and this is the resulted code:
Function CellsInSelection_ReplaceArray(ByRef TxFound As Collection) As Integer Dim NumAreas As Integer Dim NumCells As Integer Dim Area As Microsoft.Office.Interop.Excel.Range Dim cell As Microsoft.Office.Interop.Excel.Range Dim oSel As Microsoft.Office.Interop.Excel.Range Dim rowInit As Integer Dim rowEnd As Integer Dim KeyTx As String = Nothing Dim Row As Integer Dim rowSel As New List(Of Integer) ' ArrayList Try rowInit = 1 rowEnd = 10000 ' THIS IS PART OF THE BAD DESIGN!! ' oSel = oSht.Application.Selection ' Get the number of separate Areas inside the user's selection. ' oSht is a pointer to the ActiveWorksheet NumAreas = oSht.Application.Selection.Areas.Count ' For each area ... While NumAreas > 0 ' Find the index for the last row in the current Area Dim maxRow As Integer = oSht.Application.Selection.Areas(NumAreas ).Row + _ oSht.Application.Selection.Areas(NumAreas ).EntireRow.Rows.Count _ - 1 ' Compute how many rows are captured in current Area, so that we don't allocate (waste) to ' much memory with our Array structures. Dim numRows As Integer = oSht.Application.Selection.Areas(NumAreas ).Cells.Count If numRows = 0 Then GoTo NextArea End If ' Find the index for the first row in the current Area Dim startRow As Integer = oSht.Application.Selection.Areas(NumAreas).Row ' Declare the 3 Array objects and make them hold only the 'numRows' number of elements. ' We are declaring 3 objects because the program only needs the information from 3 columns ' in that sheet >> column #4, #5, #7 Dim arrData (numRows, 1) As Object 'DateTime Dim arrCodNetwork(numRows, 1) As Object 'String Dim arrProg (numRows, 1) As Object 'Integer ' Initialize each Array with the corresponding cells from the current Area arrData = oSht.Range(oSht.Cells(startRow, 7), oSht.Cells(maxRow, 7)).Value arrCodNetwork = oSht.Range(oSht.Cells(startRow, 4), oSht.Cells(maxRow, 4)).Value arrProg = oSht.Range(oSht.Cells(startRow, 5), oSht.Cells(maxRow, 5)).Value NumCells = numRows ' For each cell in each Array While NumCells > 0 ' THIS IS PART OF THE BAD DESIGN!! >> the old code used to create a RCW (Excel.Range) ' and store a reference to the cells on the active row ('NumCells') from the current ' Area ... it repeated this action for EVERY CELL! ' cell = Area.Cells(NumCells) ' Row = cell.Row Row = NumCells ' If the Row index is within the Initial/Final row limits If (Row + startRow >= RowInit And Row + startRow <= RowEnd And _ Not oSht.Rows(Row + startRow).Hidden) Then If (Not RowSel.Contains(Row + startRow)) Then RowSel.Add(Row + startRow) Dim oTx As TrasmissionObj = New TrasmissionObj ' Initialize the oTx structure ' THIS IS PART OF THE BAD DESIGN!! >> oTx.Data = oSht.Cells(Row, 7).value oTx.Data = CType(arrData(NumCells, 1), DateTime) ' oTx.Cod_Network = oSht.Cells(Row, RtxConst + 4).value oTx.Cod_Network = CType(arrProg(NumCells, 1), String) ' oTx.Prog = oSht.Cells(Row, RtxConst.RtxConst + 5).value oTx.Prog = CType(arrCodNetwork(NumCells, 1), Integer) TxFound.Add(oTx) End If End If NumCells = NumCells - 1 ' go to the next cell End While NextArea: ' go to the next Area (we travel in reverse order) NumAreas = NumAreas - 1 End While 'NumAreas > 0 If (TxFound.Count = 0) Then MsgBox("No cell selected") Else CellsInSelection_ReplaceArray = 0 End If Catch ex As Exceptio MsgBox("Error: " & ex.Message.ToString) End TryEnd Function |
Of course, thare are lots of examples where this approach might be difficult to implement (you might need to check a particular cell for certain formulas, styles .. etc) and it is not so easy get access to this data without sequential access, but you still have to try to optimize the code as much as possible.
As you will find out from my second example, even a few miliseconds will make the difference between a successful run and an error...
Some 3rd party company needed a tool for allowing its end-users to query a data base and retrieve the results inside Excel workbooks. When the VSTO add-in was tested in the developer's lab, everything was running fine. But when it began to be used in the production environment, the application seemed to run instable and caused the following problems:
> it simply failed with an "out of memory" dialog from Excel, even if at least 1 GB of RAM was free;
> or it showed a dialog with an "Invalid cast exception" message;
I noticed that the algorithm relied on some loops which cycled over individual cells grouped in Named Ranges. Because the (random) errors seemed to be connected to the accessing of those Named Ranges objects, I suspected that they were pointing to bad addresses .. or someting similar.
But it was revealed that the code didn't crash because of some corrupt named ranges ... instead the same 'big code loops' issue triggered the behavior. And we also found a temporary solution: we introduced some text file logging throughout the code to identify the places where the random errors occured more often. But the additional delay this code introduced, seemed to make Excel more stable, so we started to experiment with Thread.Sleep(ms) calls:
> if we added a wait time of 10 ms, the code ran until about 280 iterations, then it crashed;
> but if we increased the wait period to 200 ms, then it reaches 400 iterations;
We determined that it takes 500ms to make the code run stable.
For a long-term solution, I advised my client to try to get all the data stored in each sheet into a memory array structure. And then he would only use the information stored in each ‘Named Range’ to identify the (<start row, start column>; <end row, end column>) coordinates. It should be enough to determine the index in the array from where the code needs to read its data.
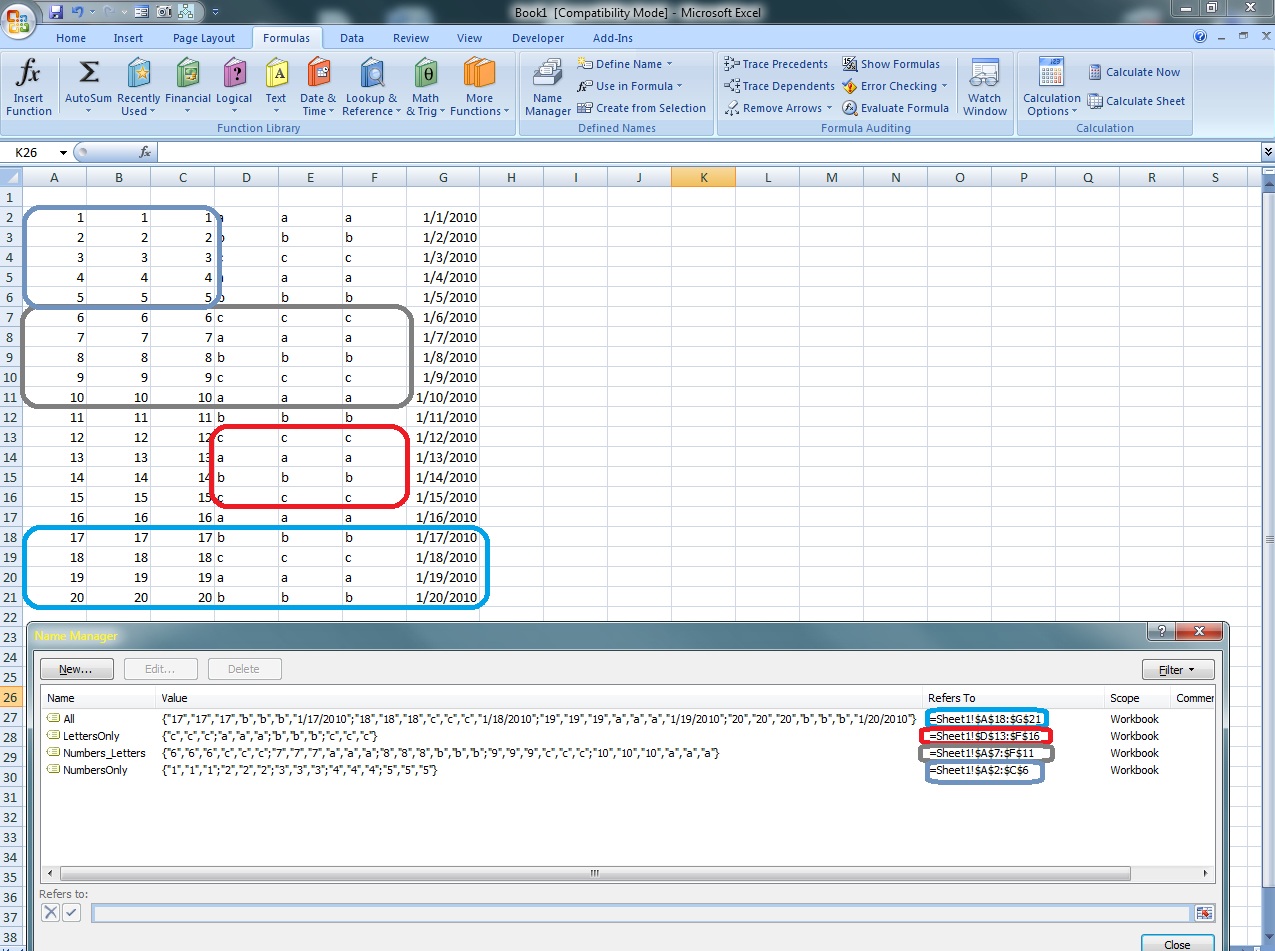
VBA sample – how can we determine the coordinates of the start row and start column and end row and end column for any named range:
Sub Test() Dim nRng As Name For Each nRng In ActiveWorkbook.Names Debug.Print "Name: " & nRng.Name & vbTab & _ "Formula: " & nRng.RefersToR1C1 Debug.Print "Start column " & vbTab & nRng.RefersToRange.Column Debug.Print "Start row " & vbTab & nRng.RefersToRange.Row Debug.Print "Max column " & vbTab & _ nRng.RefersToRange.EntireColumn.Column + _ nRng.RefersToRange.EntireColumn.Columns.Count - 1 Debug.Print "Max row " & nRng.RefersToRange.EntireRow.Row + _ nRng.RefersToRange.EntireRow.Rows.Count - 1 Debug.Print "Cell count " & nRng.RefersToRange.Cells.Count & _ vbNewLine NextEnd Sub |
| Output ===================================================================Name: All Formula: =Sheet1!R18C1:R21C7Start column 1Start row 18Max column 7Max row 21Cell count 28
Name: LettersOnly Formula: =Sheet1!R13C4:R16C6Start column 4Start row 13Max column 6Max row 16Cell count 12 Name: Numbers_Letters Formula: =Sheet1!R7C1:R11C6Start column 1Start row 7Max column 6Max row 11Cell count 30 Name: NumbersOnly Formula: =Sheet1!R2C1:R6C3Start column 1Start row 2Max column 3Max row 6Cell count 15 |
Allright, so we know how to read the properties for a Named Range item. Now we need to store all the data from the current Excel worksheet into a native .NET object to avoid making calls to the Interop layers for every single cell we want to read/write.
The ActiveSheet.UsedRange property https://msdn.microsoft.com/en-us/library/aa218185(v=office.10).aspx is useful for determining what is the minimum range that we have to store in our Array and at the same time, make sure we can access any piece of information found inside our sheet, but avoid alocating space for empty cells.
Here we must also take into account that the coordinate for our (used)range and our memory array are not always overlapping. The named range startRow / startCol and maxRow / maxCol coordinates have their origin in cell A1. If the input worksheet has an empty row of cells near the origin, the memory array will store in item (1,1) a different coordinate, specific to the first non-empty cell in your worksheet.
So we have to take note of this fact and translate the coordinates so that any address from the named range is mapped correctly in the memory array (usedRangeColOffset, usedRangeColOffset).
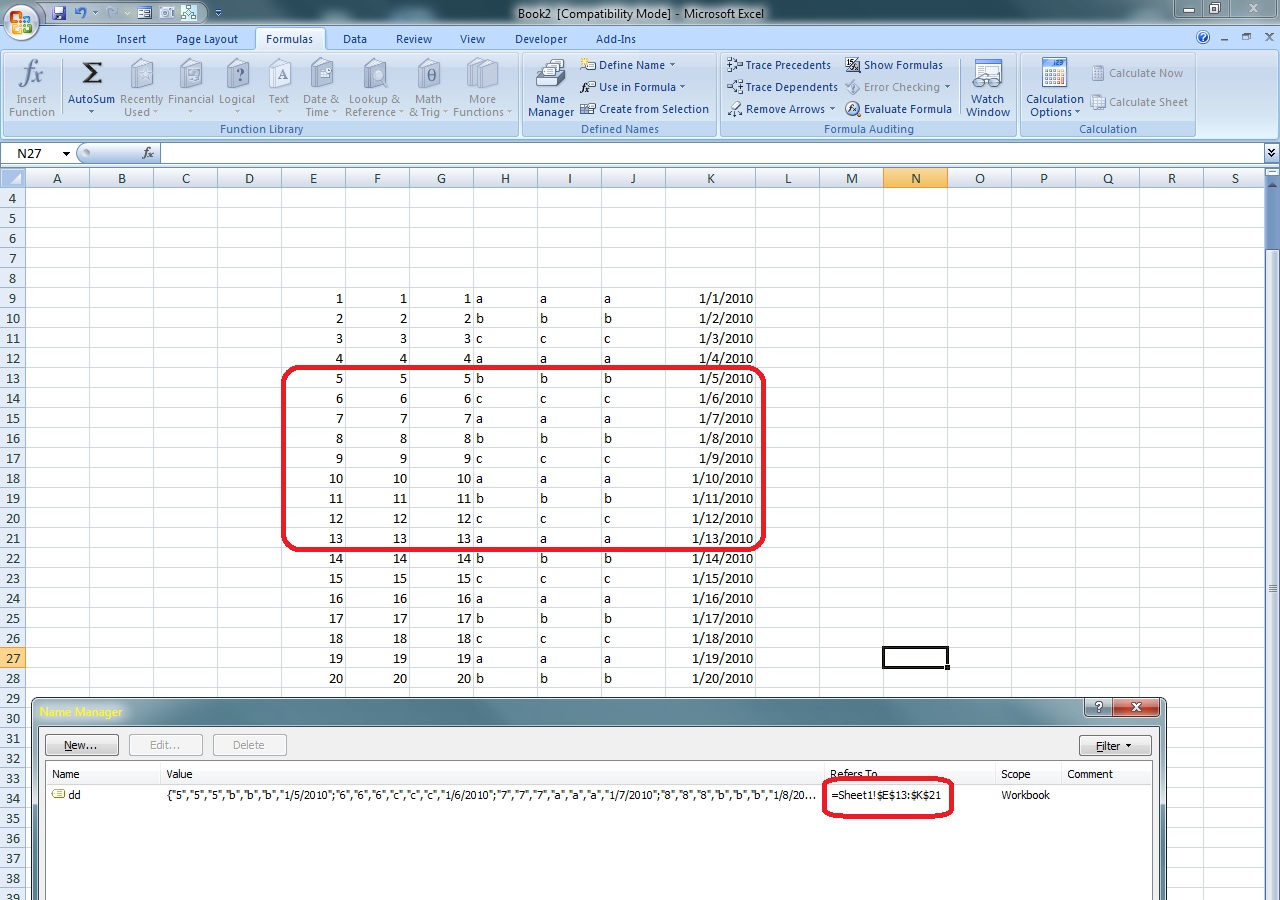
VBA sample – store the UsedRange in a custom Array object and retrieve the data referenced by NamedRanges from this Array
Sub Test2() Dim nRng As NameDim myarray As Variant myarray = ActiveSheet.UsedRange.Value Dim usedRangeRowOffset As DoubleDim usedRangeColOffset As Double usedRangeRowOffset = ActiveSheet.UsedRange.RowusedRangeColOffset = ActiveSheet.UsedRange.Column For Each nRng In ActiveWorkbook.Names Dim startCol As Long Dim startRow As Long Dim maxCol As Long Dim maxRow As Long startCol = nRng.RefersToRange.Column - usedRangeColOffset + 1 startRow = nRng.RefersToRange.Row - usedRangeRowOffset + 1 maxCol = nRng.RefersToRange.EntireColumn.Column + _ nRng.RefersToRange.EntireColumn.Columns.Count - _ usedRangeColOffset maxRow = nRng.RefersToRange.EntireRow.Row + _ nRng.RefersToRange.EntireRow.Rows.Count - _ usedRangeRowOffset Debug.Print "Name: " & nRng.Name & vbTab & "Formula: " & _ nRng.RefersToR1C1 For i = startRow To maxRow Dim strLine As String strLine = "" For j = startCol To maxCol strLine = strLine & vbTab & myarray(i, j) Next j Debug.Print strLine & vbNewLine Next i Next End Sub |
| Output ===================================================================
Name: dd Formula: =Sheet1!R13C5:R21C11 5 5 5 b b b 1/5/2010 6 6 6 c c c 1/6/2010 7 7 7 a a a 1/7/2010 8 8 8 b b b 1/8/2010 9 9 9 c c c 1/9/2010 10 10 10 a a a 1/10/2010 11 11 11 b b b 1/11/2010 12 12 12 c c c 1/12/2010 13 13 13 a a a 1/13/2010 |
ContextSwitchDeadlock
In addition, the long-running loop causes Excel to stop pumping Window messages (like repaint, click, minimize …more details can be found here: https://msdn.microsoft.com/en-us/library/windows/desktop/ms644927(v=vs.85).aspx About Messages and Message Queues) and this will lead to timeout issues. Here is a hint about how to call the cleanup code:
Visual Studio Developer Center > Visual Studio Forums > Visual Studio Tools for Office > Non pumping wait or processing a very long running operation without pumping Windows messages. https://social.msdn.microsoft.com/Forums/en-US/vsto/thread/bf71a6a8-2a6a-4c0a-ab7b-effb09451a89=================================================================================================I am developing an Excel addin in VSTO 2008 in vb. Part of my addin involves writing to tens or hundreds of thousands of cells in Excel. If this process takes more than a minute I get the following error message. "The CLR has been unable to transition from COM context 0x173250 to COM context 0x172eb8 for 60 seconds. The thread that owns the destination context/apartment is most likely either doing a non pumping wait or processing a very long running operation without pumping Windows messages. This situation generally has a negative performance impact and may even lead to the application becoming non responsive or memory usage accumulating continually over time. To avoid this problem, all single threaded apartment (STA) threads should use pumping wait primitives (such as CoWaitForMultipleHandles) and routinely pump messages during long running operations." The problem is that I do not know how to solve this issue. Can anyone offer some suggestions? ... This is a Managed Debugging Assistant (MDA) warning. It is firing because you are conducting a long operation without allowing messages to pump. You can resolve this problem by pumping messages at the end of each pass through the loop. Typically you would do this by PInvoking the Win32 PeekMessage followed by the Win32 TranslateMessage and DispatchMessage function in a loop as follows... while (PeekMessage(...)) { TranslateMessage(...); DispatchMessage(...);} This will have the effect of dispatching any pending messages that arrive while your loop is running. For more fine-grained control, you could examine the messages and only dispatch certain messages or ranges. You might do this if you wanted to prevent input from being processed during your loop for example. Really it boils down to how much reentrancy you can tolerate. On one hand, users get antsy when applications block for a long time (they tend to think they are hung). On the other hand, processing messages during long operations can result in strange side-effects due to rentrancy. You'll have to weigh the trade-offs and make the right decision. If you want to completely disallow any rentrancy, you could also PInvoke CoWaitForMultipleHandles to wait with a timeout value (since you'll never signal the handle you will wait on). I think you can even use 0 for the timeout value--otherwise just wait for a milisecond. Either way, by calling CoWaitForMultipleHandles you will get the minimum level of message pumping to support a COM server. If you want to completely disallow re-entrancy yet still allow for incoming COM calls, this would be the approach to take. If you decide to ignore the MDA, you can disable it by going into Debug "Exceptions" and unchecking "Context Switch Deadlock" under the "Managed Debugging Assistants" tree. ... I am a bit of a VSTO novice and could use a bit more assistance if possible. The following is an example of the VB code that is relevant to my query. Dim wbActive As Excel.Workbook = Globals.ThisAddIn.Application.ActiveWorkbook Dim r As New Random wbActive.Application.ScreenUpdating = False For i = 1 To 100000 wbActive.ActiveSheet.Cells(i, 1) = r.NextDouble Next wbActive.Application.ScreenUpdating = True Could you show me how I would implement your suggestions in the above code? ... Imports System.Runtime.InteropServices Imports System.Threading Public Class Sheet1 <DllImport("ole32.dll")> _ Public Shared Function CoWaitForMultipleHandles(ByVal dwFlags As Int32, _ ByVal dwTimeout As Int32, ByVal cHandles As Int32, ByVal pHandles() As IntPtr, _ ByRef lpdwindex As Int32) As Int32 End Function Private Sub Sheet1_Startup(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Startup Dim wbActive As Excel.Workbook = Me.Parent Dim r As New Random wbActive.Application.ScreenUpdating = False 'Create an array with one unsignaled handle to wait on Dim evt As ManualResetEvent = New ManualResetEvent(False) Dim waitHandles(0) As IntPtr waitHandles(0) = evt.SafeWaitHandle.DangerousGetHandle For i = 1 To 100000 wbActive.ActiveSheet.Cells(i, 1) = r.NextDouble Dim index As Int32 Dim ret As Int32 ' Wait timeout is zero. All we want to do is pump COM messages. ret = CoWaitForMultipleHandles(0, 0, waitHandles.Length, waitHandles, index) Next wbActive.Application.ScreenUpdating = True End Sub |
The above solution is worth trying, but even if you manage to solve this particular issue, since Excel is not meant to be used in extensive automation scenarios (because it was designed as an user interactive application … and human users don’t process thousands of lines / second :-p ) you may end up facing even bigger problems. It would be much safer if you used OpenXML API to get the data from workbooks.
Thank you for reading my article! Bye :-)