Serializable vs. Snapshot Isolation Level
Both the serializable and snapshot isolation levels provide a read consistent view of the database to all transactions. In either of these isolation levels, a transaction can only read data that has been committed. Moreover, a transaction can read the same data multiple times without ever observing any concurrent transactions making changes to this data. The unexpected read committed and repeatable read results that I demonstrated in my prior few posts are not possible in serializable or snapshot isolation level.
Notice that I used the phrase "without ever observingany ... changes." This choice of words is deliberate. In serializable isolation level, SQL Server acquires key range locks and holds them until the end of the transaction. A key range lock ensures that, once a transaction reads data, no other transaction can alter that data - not even to insert phantom rows - until the transaction holding the lock completes. In snapshot isolation level, SQL Server does not acquire any locks. Thus, it is possible for a concurrent transaction to modify data that a second transaction has already read. The second transaction simply does not observe the changes and continues to read an old copy of the data.
Serializable isolation level relies on pessimistic concurrency control. It guarantees consistency by assuming that two transactions might try to update the same data and uses locks to ensure that they do not but at a cost of reduced concurrency - one transaction must wait for the other to complete and two transactions can deadlock. Snapshot isolation level relies on optimistic concurrency control. It allows transactions to proceed without locks and with maximum concurrency, but may need to fail and rollback a transaction if two transactions attempt to modify the same data at the same time.
It is clear there are differences in the level of concurrency that can be achieved and in the failures (deadlocks vs. update conflicts) that are possible with the serializable and snapshot isolation levels.
How about transaction isolation? How do serializable and snapshot differ in terms of the transaction isolation that they confer? It is simple to understand serializable. For the outcome of two transactions to be considered serializable, it must be possible to achieve this outcome by running one transaction at a time in some order.
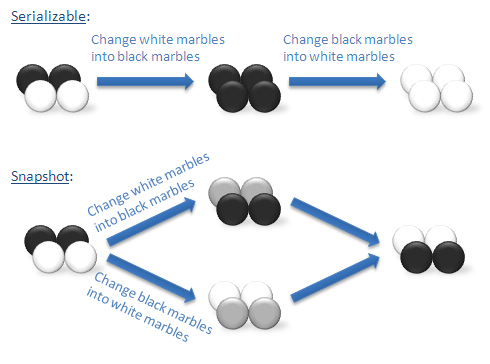
Snapshot does not guarantee this level of isolation. A few years ago, Jim Gray shared with me the following excellent example of the difference. Imagine that we have a bag containing a mixture of white and black marbles. Suppose that we want to run two transactions. One transaction turns each of the white marbles into black marbles. The second transaction turns each of the black marbles into white marbles. If we run these transactions under serializable isolation, we must run them one at a time. The first transaction will leave a bag with marbles of only one color. After that, the second transaction will change all of these marbles to the other color. There are only two possible outcomes: a bag with only white marbles or a bag with only black marbles.
If we run these transactions under snapshot isolation, there is a third outcome that is not possible under serializable isolation. Each transaction can simultaneously take a snapshot of the bag of marbles as it exists before we make any changes. Now one transaction finds the white marbles and turns them into black marbles. At the same time, the other transactions finds the black marbles - but only those marbles that where black when we took the snapshot - not those marbles that the first transaction changed to black - and turns them into white marbles. In the end, we still have a mixed bag of marbles with some white and some black. In fact, we have precisely switched each marble.
The following graphic illustrates the difference:
We can demonstrate this outcome using SQL Server. Note that snapshot isolation is only available in SQL Server 2005 and must be explicitly enabled on your database:
alter database database_name set allow_snapshot_isolation on
Begin by creating a simple table with two rows representing two marbles:
create table marbles (id int primary key, color char(5))
insert marbles values(1, 'Black')
insert marbles values(2, 'White')
Next, in session 1 begin a snaphot transaction:
set transaction isolation level snapshot
begin tran
update marbles set color = 'White' where color = 'Black'
Now, before committing the changes, run the following in session 2:
set transaction isolation level snapshot
begin tran
update marbles set color = 'Black' where color = 'White'
commit tran
Finally, commit the transaction in session 1 and check the data in the table:
commit tran
select * from marbles
Here are the results:
id color
----------- -----
1 White
2 Black
As you can see marble 1 which started out black is now white and marble 2 which started out white is now black. If you try this same experiment with serializable isolation, one transaction will wait for the other to complete and, depending on the order, both marbles will end up either white or black.