Repeatable Read Isolation Level
In my last two posts, I showed how queries running at read committed isolation level may generate unexpected results in the presence of concurrent updates. Many but not all of these results can be avoided by running at repeatable read isolation level. In this post, I'll explore how concurrent updates may affect queries running at repeatable read.
Unlike a read committed scan, a repeatable read scan retains locks on every row it touches until the end of the transaction. Even rows that do not qualify for the query result remain locked. These locks ensure that the rows touched by the query cannot be updated or deleted by a concurrent session until the current transaction completes (whether it is committed or rolled back). These locks do not protect rows that have not yet been scanned from updates or deletes and do not prevent the insertion of new rows amid the rows that are already locked. The following graphic illustrates this point:
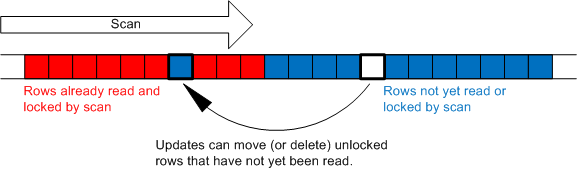
Note that the capability to insert new "phantom" rows between locked rows that have already been scanned is the principle difference between the repeatable read and serializable isolation levels. A serializable scan acquires a key range lock which prevents the insertion of any new rows anywhere within the range (as well as the update or deletion of any existing rows within the range).
In the remainder of this post, I'll give a couple of examples of how we can get unexpected results even while running queries at repeatable read isolation level. These examples are similar to the ones from my previous two posts.
Row Movement
First, let's see how we can move a row and cause a repeatable read scan to miss it. As with all of the other example in this series of posts, we'll need two sessions. Begin by creating this simple table:
create table t (a int primary key, b int)
insert t values (1, 1)
insert t values (2, 2)
insert t values (3, 3)
Next, in session 1 lock the second row:
begin tran
update t set b = 2 where a = 2
Now, in session 2 run a repeatable read scan of the table:
select * from t with (repeatableread)
This scan reads the first row then blocks waiting for session 1 to release the lock it holds on the second row. While the scan is blocked, in session 1 let's move the third row to the beginning of the table before committing the transaction and releasing the exclusive lock blocking session 2:
update t set a = 0 where a = 3
commit tran
As we expect, session 2 completely misses the third row and returns just two rows:
a b c
----------- ----------- -----------
1 1 1
2 2 2
Note that if we change the experiment so that session 1 tries to touch the first row in the table, it will cause a deadlock with session 2 which holds a lock on this row.
Phantom Rows
Let's also take a look at how phantom rows can cause unexpected results. This experiment is similar to the nested loops join experiment from my previous post. Begin by creating two tables:
create table t1 (a1 int primary key, b1 int)
insert t1 values (1, 9)
insert t1 values (2, 9)create table t2 (a2 int primary key, b2 int)
Now, in session 1 lock the second row of table t1:
begin tran
update t1 set a1 = 2 where a1 = 2
Next, in session 2 run the following outer join at repeatable read isolation level:
set transaction isolation level repeatable read
select * from t1 left outer join t2 on b1 = a2
The query plan for this join uses a nested loops join:
|--Nested Loops(Left Outer Join, WHERE:([t1].[b1]=[t2].[a2]))
|--Clustered Index Scan(OBJECT:([t1].[PK__t1]))
|--Clustered Index Scan(OBJECT:([t2].[PK__t2]))
This plan scans the first row from t1, tries to join it with t2, finds there are no matching rows, and outputs a null extended row. It then blocks waiting for session 1 to release the lock on the second row of t1. Finally, in session 1, insert a new row into t2 and release the lock:
insert t2 values (9, 0)
commit tran
Here is the output from the outer join:
a1 b1 a2 b2
----------- ----------- ----------- -----------
1 9 NULL NULL
2 9 9 0
Notice that we have both a null extended and a joined row for the same join key!
Summary
As I pointed out at the conclusion of my previous post, I want to emphasize that the above results are not incorrect but rather are a side effect of running at a reduced isolation level. SQL Server guarantees that the committed data is consistent at all times.
CLARIFICATION 8/26/2008: The above examples work as I originally described if they are executed in tempdb. However, the SELECT statements in session 2 may not block as described if the examples are executed in other databases due to an optimization where SQL Server avoids acquiring read committed locks when it knows that no data has changed on a page. If you encounter this problem, either run these examples in tempdb or change the UPDATE statements in session 1 so that they actually change the data in the updated row. For instance, for the first example try "update t set b = 12 where a = 2".