Read Committed Isolation Level
SQL Server 2000 supports four different isolation levels: read uncommitted (or nolock), read committed, repeatable read, and serializable. SQL Server 2005 adds two new isolation levels: read committed snapshot and snapshot. These isolation levels determine what locks SQL Server takes when accessing data and, therefore, by extension they determine the level of concurrency and consistency that statements and transactions experience. All of these isolation levels are described in Books Online.
In this post, I'm going to take a closer look at the default isolation level of read committed. When SQL Server executes a statement at the read committed isolation level, it acquires short lived share locks on a row by row basis. The duration of these share locks is just long enough to read and process each row; the server generally releases each lock before proceeding to the next row. Thus, if you run a simple select statement under read committed and check for locks (e.g., with sys.dm_tran_locks), you will typically see at most a single row lock at a time. The sole purpose of these locks is to ensure that the statement only reads and returns committed data. The locks work because updates always acquire an exclusive lock which blocks any readers trying to acquire a share lock.
Now, let's suppose that we scan an entire table at read committed isolation level. Since the scan locks only one row at a time, there is nothing to prevent a concurrent update from moving a row before or after our scan reaches it. The following graphic illustrates this point:
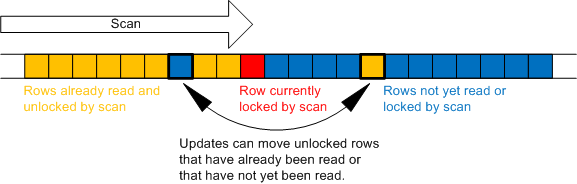
Let's try an experiment to see this effect in action. We'll need two server sessions for this experiment. First, create a simple table with three rows:
create table t (a int primary key, b int)
insert t values (1, 1)
insert t values (2, 2)
insert t values (3, 3)
Next, in session 1 lock the second row:
begin tran
update t set b = 12 where a = 2
Now, in session 2 run a simple scan of the table:
select * from t
This scan will read the first row and then block waiting for session 1 to release the lock it holds on the second row. While the scan is blocked, in session 1 we can swap the first and third rows and then commit the transaction and release the exclusive lock blocking session 2:
update t set a = 4 where a = 1
update t set a = 0 where a = 3
select * from t
commit tran
Here are the new contents of the table following these updates:
a b
----------- -----------
0 3
2 2
4 1
Finally, here is the result of the scan from session 2:
a b
----------- -----------
1 1
2 2
4 1
Notice that in this output the first row was scanned prior to the updates while the third row was scanned following the updates. In fact, these two rows are really the same row from before and after the update. Moreover, the original third row that had the value (3, 3) is not output at all. (We could claim that changing the primary key effectively deleted one row and created a new row, but we could also achieve the same effect on a non-clustered index.)
Finally, try repeating this experiment, but add a unique column to the table:
create table t (a int primary key, b int, c int unique)
insert t values (1, 1, 1)
insert t values (2, 2, 2)
insert t values (3, 3, 3)
You'll get the same result, but you'll see "duplicates" in the unique column.
If the above results are not acceptable, you can either enable read committed snapshot for your database or you can run at a higher isolation level (albeit with somewhat lower concurrency).
CLARIFICATION 8/26/2008: The above example works as I originally described if it is executed in tempdb. However, the SELECT statement in session 2 may not block as described if the example is executed in other databases due to an optimization where SQL Server avoids acquiring read committed locks when it knows that no data has changed on a page. If you encounter this problem, either run this example in tempdb or change the UPDATE statement in session 1 so that it actually changes the value of column b. For example, try "update t set b = 12 where a = 2".
UPDATE 2/17/2011: I changed the example from "update t set b = 2 where a = 2" to "update t set b = 12 where a = 2" to avoid the issue described in the above clarification.