Working with Names and Name Based Attributes
I’d like to take a minute to discuss something that can be a real pain when deploying an identity management solution: names. As anyone who has deployed or managed a large scale IdM solution can attest to, names can be a real hassle. Proper casing, uniqueness, length limits and titles/preferred names all make for a real challenge sometimes. So, if we have decided to deploy an IdM solution (such as FIM) to programmatically handle our user management, can we, from a fully autonomous approach, overcome these hurdles without drawing the ire of our user base? The answer is, yes, we can…for the most part. It’s important to remember that this really is a “numbers game”. It’s easy to write logic to make everyone happy in an organization of 500 users. This may not, however, be the case in an organization with 500,000 users. As the number of our user base increases, so does the potential complexity of name/accountname logic. My personal feeling (and what I often convey to customers), is that, if out of an organization of 500,000 users, I still have to manually administer 100 users, that means I will never have to touch the other 499,900 ever again. To me, that is a win. The other thing I would urge you to ask yourself is, “is it worth it?”. By that I mean, if I can implement logic that handles 99.99% of all users, does it really make sense to spend hours (if not days) figuring out the logic to automate the management of a handful of people (.01%)?
With that in mind, let’s start by talking about names. More specifically, let’s talk first, middle and last names. I’m a big fan of using these to build out other attributes (such as accountName, mailNickName, etc.). So before we even begin to look at those other attributes, let’s first get first, middle and last looking good. We are assuming this data is being fed from somewhere (such as an HR data feed). If this user data is coming from a database, it is very likely it might come in as all uppercase. When it comes to proper casing names, we have a few options on how to handle that. Option one is to use a set/workflow/MPR within the FIM portal. For example, you could create a “New User Attribute Builder” workflow that proper cases names, builds accountName, etc.. In this case, you might have a couple of activities that look something like:
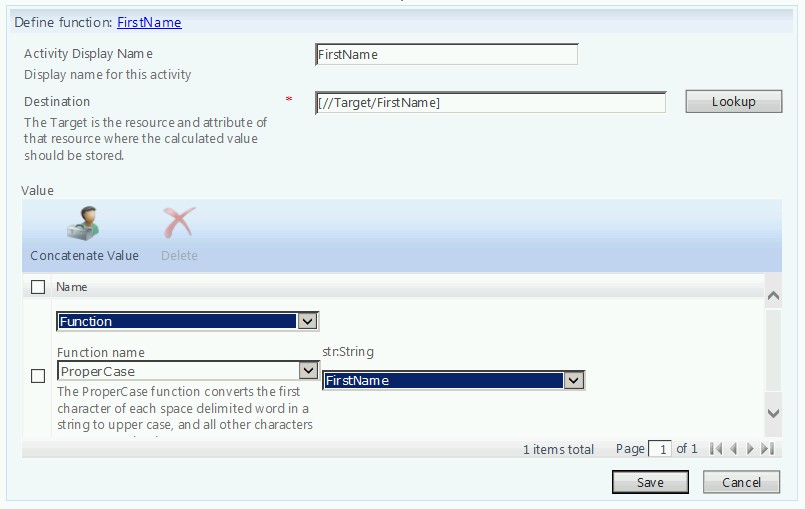
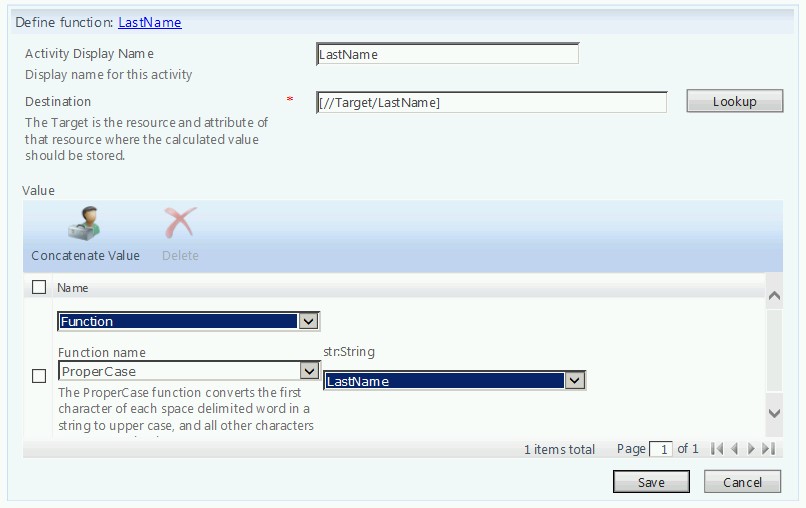
In many cases, this might be fine. However, there is an issue that exists here. What happens if I have a defined precedence that goes something like this: HR -> FIM -> AD? Under this scenario, if the data coming from HR is always authoritative over the data in FIM, my (now properly cased) names in FIM will be overwritten the next time a sync job runs. This could cause an issue where a user has their name proper cased, HR sync runs and exports to FIM overwriting names as all upper case, workflow proper cases them and this cycle repeats endlessly. Some admins have overcome this by creating a custom attribute that essentially marks that user object as being “managed by FIM”. By doing so, after these values are set initially, they are not modified by HR (even though it is precedent).
Another method of addressing this is to do the conversion directly in the inbound user synchronization rule. This can be easily done by use of a function on the “source” tab of the inbound attribute flow, as shown:

This method, however, is not without fault. The downside here is that this evaluation will occur every time the sync rule runs. This could theoretically slow down imports and syncs. At the end of the day, the decision here must be made by you based on your own environment.
However we do it, once we have arrived at the point where our first, middle and last names have been proper cased, we can then move on to building account names. The real trick here is to do so in a way that guarantees uniqueness across the organization. To use the example above, this may be relatively easy in an environment of 500 users, but what about 500,000? Please note that for the following scenarios, we are using a custom activity workflow to generate unique values. For smaller environments, an activity such as this may be sufficient:
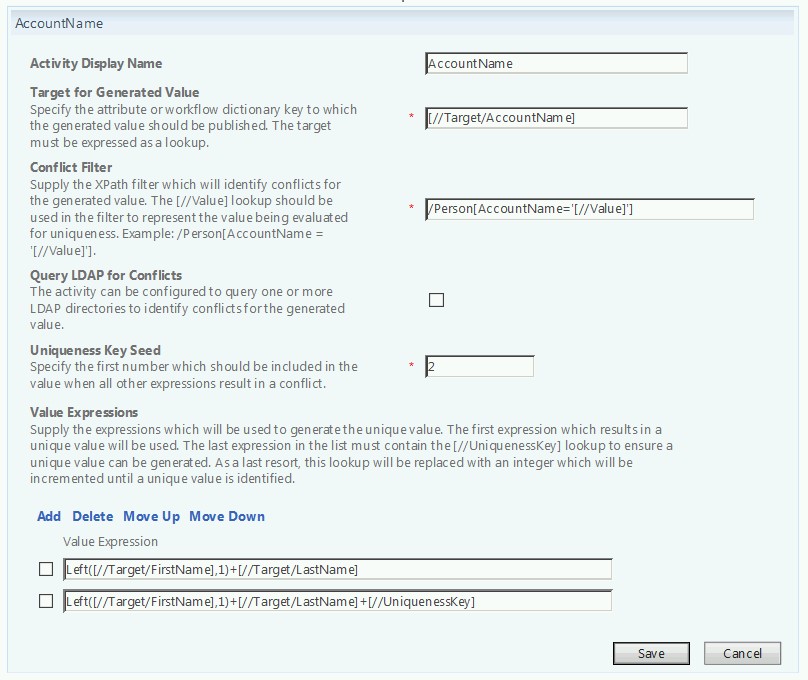
Here, we are doing a simple first initial + last name. For user John Doe, the resulting AccountName would be
jdoe
With the addition of a “uniqueness key seed”, if jdoe is taken and another user (Jim Doe, for example) comes in, their AccountName would subsequently be jdoe2. For smaller environments, this may be a perfectly acceptable approach. For larger environments, however, this might possibly result in users with AccountName values of jdoe47. Likewise, this also fails to address uniqueness in Active Directory. Fortunately, however, we do have the ability to do LDAP queries directly, as illustrated here:
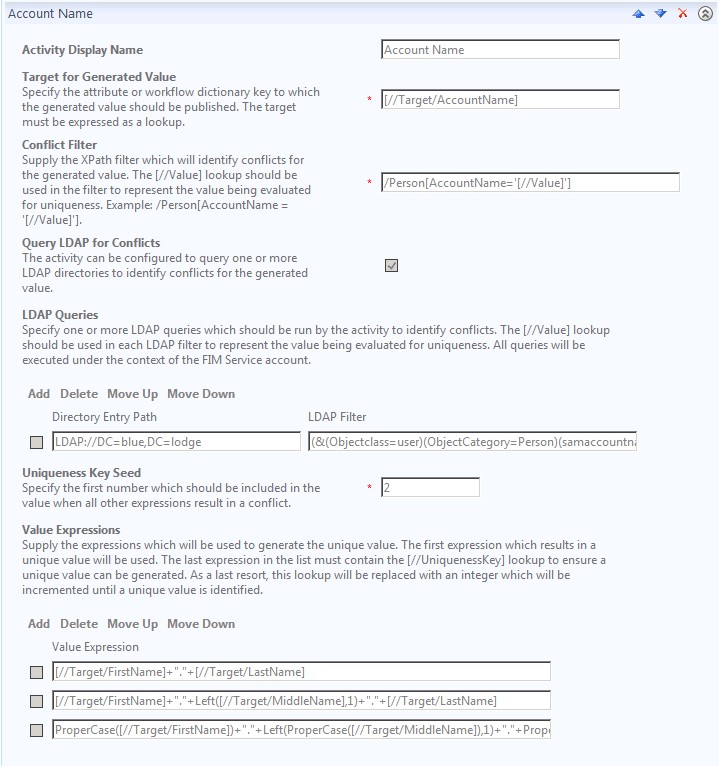
In this case, we are querying LDAP to determine uniqueness (and not just within FIM). Also, you may notice not only the inclusion of MiddleName, but also the proper casing occurring here (rather than in the sync rule). For user JOHN ADAM DOE, the above three value expressions would result in the following three account names:
JOHN.DOE
JOHN.A.DOE
John.A.Doe
In any of these cases, by also using a uniqueness key seed, Jim Doe no longer becomes an issue. The seed would only be used in cases such as:
JOHN.DOE2
JOHN.A.DOE2
John.A.Doe2
Specifically, in the third example, a user with the same first name and middle initial (John Allen Doe and John Adam Doe, for example) would have to exist within the organization.
Even with this approach, there is still, however, a potential issue. In examples 2 & 3 above, what happens if the middleName attribute is not present? The resulting AccountName would be:
John..Doe
This can be overcome with the addition of an “IsPresent” check. For example:
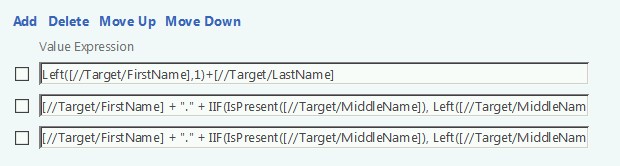
Since the entire Value Expression is not visible I the above image, here they are in full:
[//Target/FirstName] + "." + IIF(IsPresent([//Target/MiddleName]), Left([//Target/MiddleName],1), "") + IIF(IsPresent([//Target/MiddleName]), ".", "") + [//Target/LastName]
[//Target/FirstName] + "." + IIF(IsPresent([//Target/MiddleName]), Left([//Target/MiddleName],1), "") + IIF(IsPresent([//Target/MiddleName]), ".", "") + [//Target/LastName]+[//UniquenessKey]
By doing so, user John A. Doe would receive an Account Name of John.A.Doe, while user John Doe would simply be John.Doe (and not John..Doe). You may also notice the use of “Left” in the above examples. “Left” is a function we can make use of to count over a certain numbers of characters. In the example of:
Left([//Target/FirstName],1)
We would start at the beginning and count over 1 character (producing the first initial). Technically, there is no limit on the number of spaces we can count (up to the full length of the value). For example:
Left[//Target/FirstName/Bartholomew],4)
Would return: Bart
There are also functions for “Right” (which counts backwards from the end) and “Mid” (which starts in the middle).
It is also worth noting at this point that this same logic can be used when building values such as DisplayName. In terms of Active Directory, DisplayName must be unique per container, but not forest wide. Also, depending on how your organization handles email addresses, it may be useful to recycle the bits above (since we’ve already determined AccountName to be unique. The activity here may be as simple as:
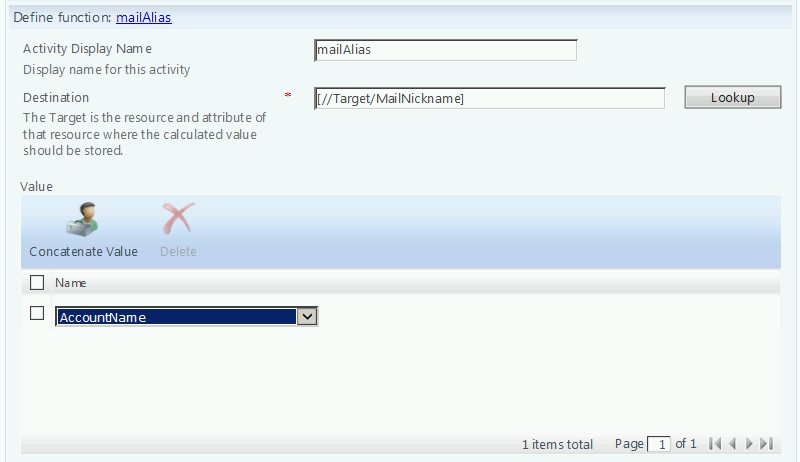
Finally, there are a few other considerations when it comes to handling names with FIM. The attribute sAMAcountName in Active Directory, for example, has a maximum length of 20 characters. For compliance, we can easily use the function “Trim” (or even “Left”) to grab the first 20, but this may be confusing for users whose name is far longer than 20 characters. Likewise, it may also be worth considering titles (such as “Dr.”) when handling names. Let’s say we’d like our DisplayName to be in the following format:
“LastName, FirstName Middle Initial” (i.e. Doe, John A. )
How do we handle it if Mr. Doe is a doctor? The cleanest solution, in my opinion, is to create a custom attribute in FIM to hold this title. Then, as shown above, we could use an “IIF(IsPresent” statement for the new attribute.
“LastName, Title (if present) FirstName Middle Initial” (i.e. Doe, Dr. John A. )
If the title attribute were not present, it would not be included (and neither would an additional whitespace).
Now, you may be asking, "But where's this unique value generating workflow activity? I don't have that.". Chances are, you probably don't, but fear not! This activity relies on the (recently made public) Workflow Activity Library (WAL). Download and documentation for WAL can be found here.
Questions? Comments? Love FIM so much you can't even stand it?
EMAIL US>WE WANT TO HEAR FROM YOU!<