Hadoop/HDInsight Einführung Big Data mit HDInsight/Hadoop für .NET Entwickler
| “HDInsight is Microsoft’s Hadoop-based service that brings an Apache Hadoop-based solution to the cloud. It gives you the ability to gain the full value of Big Data with a modern, cloud-based data platform that manages data of any type, whether structured or unstructured, and of any size.”Quelle: https://azure.microsoft.com/en-us/pricing/details/hdinsight/ |  |
Big Data mit Hadoop und HDInsight
In dieser Blog-Reihe über Big Data mit Hadoop und HDInsight möchte ich euch, den Entwicklern, den Einstieg in die Welt von Big Data schmackhaft machen. Das natürlich auf Basis der Microsoft Lösung HDInsight, die ja zu 100% Hadoop beinhaltet. Aber bevor wir so richtig mit Hands-On loslegen können, sollten wir uns ein wenig mit der vorhandenen Technologie in der Theorie beschäftigen, die dem Ganzen zu Grunde liegt. Keine Angst, ich bin eher ein „Mann der Praxis“, ich werde mich also so kurz wie möglich halten, damit wir recht bald einmal die Praxis beleuchten können.
Was ist Big Data?
Bevor wir uns den Technologie-Stack selbst genauer ansehen können, sollten wir uns dem Begriff “Big Data” einmal genauer widmen. Nun ja, da beginnen die Schwierigkeiten bereits. Big Data kann nämlich für jeden etwas anderes bedeuten. Für mich bedeutet es, dass Daten vorliegen, die einfach zu komplex sind, um sie in traditionellen relationalen Datenbanken UND auch in multidimensionalen Datenbanken zu analysieren. Das ist aber eben nur eine Begründung für Big Data, nämlich rein die Anzahl der Daten, bzw. eben die Datenmenge. Aber für mich ist auch schon ein einzelnes Buch „Big Data“, da die Wörter in einem Buch komplett unstrukturiert vorliegen (Vorsicht in etwaigen Diskussionen über Big Data in eurem Lieblingsliteraturzirkel, der Autor eines Buches sieht das naturgemäß etwas anders) und es nun einmal schwierig ist, die Anzahl der Hauptwörter oder alle Bindewörter in einem, oder mehreren Büchern einfach einmal so zu zählen. Also wie ihr möglicherweise schon an anderer Stelle gelesen habt, zieht man sich in der einschlägigen Literatur zu dem Thema auf eine allgemeine Beschreibung zurück.
Im Allgemeinen haben sich, wenn man von Big Data spricht, die „3V’s“ eingebürgert (Doug Laney von Gartner hat schon 2001 darüber sinniert, siehe hier) . Das sind Volume, Variety und Velocity. Sehen wir uns jeden dieser drei einmal kurz an:
| · Volume – Datenmenge: Hierunter fallen sowohl große Datenmengen von Terrabytes bis Petabytes, als auch viele kleine Datenmengen, die es gemeinsam zu analysieren gilt.· Variety – Datenvielfalt: Nicht nur die (sehr) großen Datenmengen an sich, sondern auch die Vielfältigkeit der anfallenden Daten sind eine der Herausforderungen im Big Data Bereich. Ihr werdet das vermutlich selbst kennen aus eurer Vergangenheit, oder in eurer aktuellen Firma, wo die Daten aus unternehmensinternen, und/oder aber auch aus externen Quellen stammen. Diese unterschiedlichen Daten liegen entwedero strukturiert (z. B. in relationalen Datenbanken)o halb-strukturiert (z. B. Log-Dateien von Web-Servern) und/odero komplett unstrukturiert (z. B. Texte, Webseiten, Video-, Audio-Dateien) vor.· Velocity – Geschwindigkeit: Daten, die sich andauernd verändern und kurze Gültigkeit/Aktualität beinhalten. Diese erfordern eine andauernde Generierung und Verarbeitung – sehr häufig in Echtzeit. | 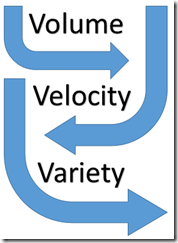 |
Noch extra erwähnen möchte ich, dass die zugrundeliegenden Daten natürlich vertrauenswürdig und korrekt sein MÜSSEN, denn wenn die Datenbasis schon schlecht ist, dann wird es mit der besten Technologie nicht gelingen brauchbare Ergebnisse für den Endbenutzer zu erzeugen, aber das war ja schon in der Vergangenheit bei euren Projekten mit relationalen Datenbanken und Analysis Services ja auch schon ein kritischer Punkt.
Soweit so gut, aber ich kann es schon richtig hören, wie ihr mir zuruft:
Die 3V’s sind nett und gut, aber SQL Server und/oder SQL Server Analysis Services mit den Integration Services erledigen diesen Job für die oben angeführten Problemstellungen doch hervorragend. Hmm, ja, möglicherweise, für strukturierte Daten. Möglicherweise.
Mit den unstrukturierten Daten und der komplexen Bearbeitung derselben sind wir nun schon eher bei des Pudels Kern angelangt, warum wir mit den bisher eingesetzten Technologien vermutlich an Grenzen stoßen werden und was das Thema Big Data im Endeffekt ausmacht. Wir wollen ja nicht „nur“ einen Server, der sich um die großen Daten, die unstrukturiert vorliegen (oder vielen kleinen Daten) kümmert, sondern die Bearbeitung der Daten soll mit mehreren Maschinen durchgeführt werden.
Und, Schwupps sind wir schon beim nächsten Thema angelangt. Die verwendete Technologie für das Thema Big Data. Aber eines sollte hier noch klar gesagt werden: Big Data wird keine der erwähnten Technologien ersetzen, sondern im Gegenteil. Es wird ergänzend eingesetzt. Für manche von euch ist das bestimmt eine Frohbotschaft, es kommt noch mehr Technologie auf euch zu….
Die Big Data Technologie
Die Daten sollen also mit „geballter Power“, also mit mehreren Maschinen, „beackert“ werden, und das nicht mit SQL oder MDX. Die Daten werden eher in einer Art Batch-Processing bearbeitet, das Resultat landet möglicherweise (muss nicht sein) wieder in Tabellenform. Nun, das genau ist eine (sehr kurze) Zusammenfassung der Kernfunktionalität von Hadoop. Das verteilte Bearbeiten von Daten, innerhalb eines Clusters mit einem Head-Node und mehreren Data-Nodes, wo jedes Node an einem Teil der Daten die Bearbeitung durchführt, um das gewünschte Resultat zu erzeugen.
Hadoop Übersicht
Hadoop selbst ist ein Open Source Projekt und ein Apache Projekt - https://hadoop.apache.org. Der innerste Kern besteht aus 2 Teilen:
· Hadoop Distributed File System (HDFS) – speichert die Daten im Cluster. Die Daten werden in Blöcke geteilt und auf verschiedene Nodes im Cluster verteilt.
· MapReduce – ein Programmiermodell, das in zwei Phasen aufgegliedert ist. Wie der Name schon sagt eben Map und Reduce. Damit ist es möglich die Datenbearbeitung auf mehrere Nodes zu verteilen, in der Map Phase werden so Zwischenergebnisse erzeugt, die in der Reduce Phase – ebenfalls parallelisiert - zu einem Gesamtergebnis weiter verarbeitet werden.
Mit diesem Wissen können wir uns schon einmal ansehen, wie die Basis Komponenten innerhalb eines Hadoop Clusters aussehen könnten (sofern dieser einmal läuft, was aber keine große Hexerei ist, wie wir in meinem nächsten Blog Eintrag sehen werden) und wie diese zusammen interagieren:
· Der Name Node (auch oft “Head Node” innerhalb des Clusters genannt): Hält primär die Metadaten für HDFS und da die Daten ja verteilt von den Daten Nodes in einzelnen Datenblöcken bearbeitet werden, muss jemand die Ablage der Daten koordinieren und den Cluster überwachen und bei einem Ausfall dementsprechend reagieren, d. h. die Daten neu auf die verbliebenen Data Nodes verteilen. Dies ist die Aufgabe des Name Node, was ihn aber auch gleichzeitig zum „Single Point of Failure“ in einem Hadoop Cluster macht.
· Data Node: Speichert ihm zugewiesene Daten in sogenannten HDFS Datenblöcken. Diese Datenblöcke werden innerhalb eines Hadoop-Clusters repliziert um Ausfallsicherheit zu gewährleisten. Jeder Data Node meldet sich fortwährend beim Name Node, der ansonsten auf einen Ausfall reagieren muss.
Soweit zur Datenhaltung, die Überwachung eine MapReduce-Jobs obliegt zwei sogenannten Trackern:
· Der Job Tracker verteilt die einzelnen Aufgaben innerhalb des MapReduce Jobs, ist aber im Fehlerfall weniger kritisch zu handhaben als der Ausfall des Name Nodes, da bei Neustart des Job Tracker alle Jobs erneut gestartet werden.
· Der Task Tracker erledigt die eigentliche Arbeit bei dem angeforderten MapReduce Job, läuft üblicherweise auf jedem Data Node.
Bildlich gesprochen lässt sich das folgendermaßen darstellen:
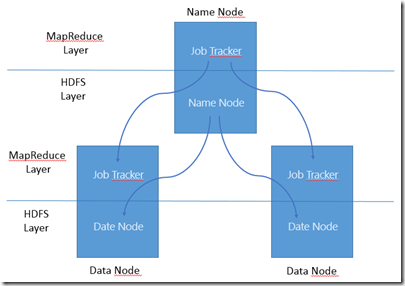
Soweit zum Core, weitere zugehörige Hadoop-Projekte, die durchaus hilfreich sind und das Gesamtbild - und die damit verbundenen technologischen Möglichkeiten - doch um einiges erweitern:
· Hive – Die Ergebnisse, die mit MapReduce Jobs erzeugt werden können mittels Hive in einer SQL ähnlichen Abfragesprache, der Hive Query Language (HQL) aus dem Hive store abgefragt werden. Hive ist ideal, um die mittels MapRedue erzeugten Ergebnisse in die bestehende BI Landschaft zu integrieren.
· Pig – Eine weitere Möglichkeit, die Daten von MapReduce Jobs abzufragen ist Pig, welches eine Scripting Engine mit dem Namen Pig Latin zur Verfügung stellt. Mit dieser können Abfragen ‚anprogrammiert‘ werden, also Prozedural abgefragt werden, im Gegensatz zu Hive, das wie erwähnt, ähnlich zu SQL – also deklarativ – arbeitet.
· HCatalog – Dieser setzt auf den Hive Metastore auf und stellt Schnittstellen für MapReduce und Pig zur Verfügung, um Daten in Tabellenform darzustellen.
· Oozie – Eine Workflow Engine für mehrere MapReduce Jobs.
· Sqoop – Wird angewendet, um Daten aus und in relationale Datenbanken in HDFS zu importieren und/oder zu exportieren.
Weitere sind noch: Fume (zum Importieren von Daten in HDFS), Mahout (machine-learning), oder Ambari (Monitoring Tool für den Cluster). Zusammengefasst sieht die Landschaft dann im Großen und Ganzen so aus:
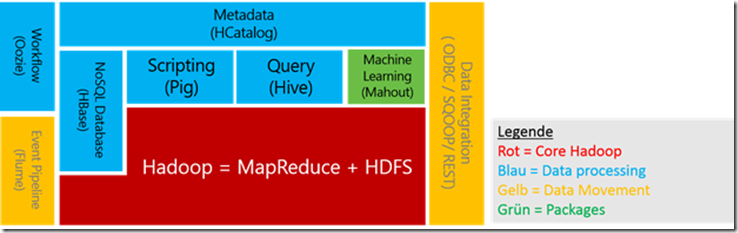
Wie man deutlich erkennen kann ist Hadoop nicht etwa (nur) eine Datenbank, bzw. ein Datenbankmanagementsystem (wie SQLServer z. B. eines ist). Es ist ein verteiltes Dateisystem, das mit riesigen (unstrukturierten) Datenmengen – mit dutzenden Terabytes - gefüttert werden kann, diese wiederum mit MapReduce Jobs bearbeitet und sortiert werden können - und das mit Hilfe der zu Grunde liegende Cluster-Technologie in Sekunden. In Kombination mit den erwähnten Unterprojekten kann Hadoop Prozesse ausführen, die weit über die Leistung eines (normalerweise) eingesetzten relationalen Datenbank, oder Datawarehouse-Systems hinausgehen.
Sehen wir uns doch einmal gemeinsam ein paar Einsatzszenarien für Big Data und Hadoop/HDInsight an.
Einsatz-Szenarien
1. Hadoop als ETL-Tool
Wenn große Datenmengen zur Verfügung stehen, dann steht man immer wieder vor der großen Herausforderung die für das Unternehmen relevanten Daten herauszufiltern. Nun, Hadoop ist hier ein eleganter Ansatz. Die Daten werden in Hadoop geladen und mit MapReduce Jobs bearbeitet. Mit eigenen Filtern und eigener Logik - das Resultat sind strukturierte, summierte Daten. Diese können mit bestehenden Analyse-Werkzeugen verfeinert werden, bzw. dem Reporting zugeführt werden.Normalerweise wird nu rein kleiner Prozentsatz vom gesamten vorhandenen Datenstrom für ein bestimmtes Business-Problem benötigt. Hadoop mit MapReduce, dem Clusteraufbau und den weiteren Unterprojekten ist dafür eine sehr gut geeignete Plattform.
2. Hadoop als Exploration-Engine
Wenn die Daten einmal im Cluster sind können nahezu beliebige Tools zur Analyse verwendet werden. Dies werden wir in einem der Blog-Einträge noch genauer betrachten, wenn wir Excel, PowerBI, Reportung Services usw. auf unseren (lokalen) Cluster loslassen. Neue Daten werden hinzugefügt, die bestehenden Ergebnisse bleiben weiter vorhanden und können aber natürlich zur erneuten/weiteren Analyse der Daten verwendet, bzw. weiter verdichtet werden. Das Laden in andere Systeme, wie einem SQLServer, bzw. einem SQL Server Analysis Server ist problemlos möglich und so können die Ergebnisse innerhalb des Unternehmens weiteren Anwendern zur Verfügung gestellt werden.
3. Hadoop als Archiv
Historische Daten Daten werden nicht ewig vorgehalten, sondern landen irgendwann einmal im Archiv. Werden die Daten für eine Analyse wieder benötigt, so ist es häufig mühsam diese wieder herzustellen. Mit dem Ergebnis, dass historische Daten oft nicht für die Analyse zur Verfügung stehen, da man versucht diesen Aufwand zu vermeiden. Die zugrunde liegende Speichertechnik in HDFS, sowie die effektiven Indizierungsmöglichkeiten innerhalb des Clusters - und da Speicher heutzutage günstig ist - können die (originalen) Daten in einem Hadoop Cluster weiter vorgehalten werden. Der Aufwand der Wiederherstellung entfällt und die Daten stehen jederzeit für eine historische Analyse zur Verfügung.
Microsoft HDInsight - Hadoop unter Windows
HDInsight ist die Microsoft Implementierung für Big Data Lösungen mit Apache Hadoop als Unterbau. Ihr braucht jetzt keine Angst zu haben, falls ihr denkt, dass Microsoft hier nun etwas eigenes gebaut hätte.
HDInsight ist zu 100 Prozent kompatibel mit Apache Hadoop und baut komplett auf den Open Source Framework auf.
Microsoft hat das Projekt großartig unterstützt, indem es die Funktionalität zur Verfügung gestellt hat, um Hadoop unter Windows laufen zu lassen, da Hadoop ursprünglich nur für Linux entwickelt wurde. Sie haben den notwendigen Source Code der Community zur Verfügung gestellt und diese hat dann diesen dankenswerter Weise (für uns Windows Entwickler) komplett in den Source einfließen lassen. Somit läuft Hadoop unter Windows und Microsoft hat hier die Unterstützung noch nicht gestoppt. Es wurden weitere APIs geschrieben, um mit C# Hadoop anprogrammieren zu können, bzw. den ODBC-Treiber entwickelt um auf die Daten von Hadoop auch aus bestehenden Applikation zugreifen zu können. Auch das werden wir in im Laufe dieser Blog-Reihe sehen können.
HDInsight ist in zwei Ausprägungen verfügbar, als Cloud-Lösung und als lokale Installation:
1. Windows Azure HDInsight Service: Solltet Ihr noch keine Azure Subscription euer eigen nennen, ist es nun soweit, HDInsight steht euch unter Azure zur Verfügung und wartet nur darauf, von euch als Cluster verwendet zu werden. Wir werden die Installation und die anfallenden Kosten im nächsten Blog-Eintrag näher beleuchten.
2. Windows Azure HDInsight Emulator: Eine hervorragende Lösung von Microsoft, die einen single-node, geeignet als Einzelplatz Installation, zur Verfügung stellt, welcher z. B. auf eurer Entwicklungsmaschine bestimmt eine ganz gute Figur macht. Dafür ist er nämlich gemacht: als lokale Big Data Entwicklungsinstallation zu dienen. Eure Resultate könnt ihr dann in das Azure HDInsight Service überführen und in einen richtigen Cluster in Produktion bringen. Erst einmal ohne anfallender Kosten für den Cluster.
Und genau diese beiden Lösungen werden wir uns im zweiten Teil dieser Blog-Reihe genauer ansehen.
Zusammenfassung
Hadoop an sich eignet sich perfekt für die Verarbeitung umfangreicher Batchjobs. Hadoop kann Dutzende Terabyte dateibasierter Daten sehr schnell verarbeiten. Mit diesen grundlegenden, aber leistungsfähigen Funktionen ist Hadoop sehr gut geeignet, um große Dateien zu durchsuchen, Informationen zu aggregieren oder grundlegende mathematische Funktionen wie Summe, Mittelwert oder Durchschnittswert auszuführen. HDInsight ist Microsoft’s Cloud Lösung für Big Data, zu 100% basierend auf den Open Source Framework Hadoop.
So, erst einmal genug der Theorie, ab jetzt wird kräftig mit der Software gearbeitet, ich hoffe ihr seid bei den nächsten Einträgen wieder fleißige Leser!
Berndt Hamböck ist seit 2007 MCT, darüber hinaus befasst er sich mit Lösungen für komplexe Anwendungsszenarien mit den neuesten Microsoft Technologien. Die Erfahrungen aus der Projektarbeit gibt er in Vorträgen und Trainings weiter und begleitet Entwicklerteams in Softwareunternehmen bei Projekten im Microsoft Umfeld. Folge ihm auf Twitter, um nichts zu verpassen.
Das ist ein Gastbeitrag. Die Meinung des Autors muss sich nicht mit jener von Microsoft decken. Durch den Artikel ergeben sich keinerlei Handlungsempfehlungen. Microsoft übernimmt keine Gewähr für die Richtigkeit oder Vollständigkeit der Angaben.