Design Patterns: Teil 1 – Inversion of Control & Dependency Injection
Bevor wir uns nach und nach den eigentlichen Design Patterns widmen, beginnen wir mit der Vorstellung zweier Entwicklungspraktiken, die die Qualität, Testbarkeit, Skalierbarkeit und Wartbarkeit von Software dramatisch erhöhen können.
Beachtet man, auch bei “Mini” Entwicklungen, diese Entwicklungspraktiken, spart man sich als Entwickler, sehr viele Nachbesserungs- und Anpassungsarbeiten.
Die Idee hinter Dependency Injection und allgemein Inversion-of-Control, ist die Anwendung des sogenannten “Hollywood Prinzips” –> “Don’t call us, we call you!”
Was bedeutet das für die Software Entwicklung? In einem klassischen Ansatz werden Klassen und deren Abhängigkeiten hard-codiert. Das heisst es wird mit konkreten Klassen gearbeitet, welche über Konstruktoren oder Properties Abhängigkeiten erhalten. Somit wird schon zur Kompilierzeit für jedes konkrete Objekt festegelegt, welche Interaktionen mit anderen Objekten bestehen. Einfach gesagt, werden alle Objekte fix miteinander “verdrahtet”. Änderungen sind nicht mehr möglich (ausser durch Umbauarbeiten im Sourcecode), ein dynamisches Beeinflussen von Interaktionen ist gar nicht möglich. 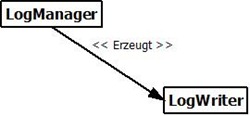
{kind=link}
Abb.1 – LogManager ist direkt abhängig von einer konkreten Implementierung von LogWriter
Besser ist eine genaue Umkehrung dieser Vorgehensweise. Also eine Komponente (Container in Abb.2), die Objekte erzeugt und selbst zur Laufzeit entscheidet, wie die einzelnen Abhängigkeiten “befriedigt” werden und welche konkreten Implementierungen zu verwenden sind, übernimmt die Kontrolle; daher –> Inversion-of-Control. Die Verwendung diese Prinzips führt implizit schon zu besserer Software, da man mit Abstraktionen wie Interfaces und Abstrakten Klassen arbeiten muss um dieses dynamische Verhalten zu erreichen. 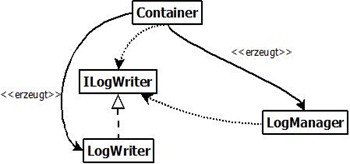
Abb.2 – Der Container erzeugt Instanzen und Injiziert Abhängigkeiten
Angenommen es soll ein einfacher Logger erstellt werden, der Zeichenketten in ein Log File schreibt. Ad-hoc könnte man mit der folgenden einfachen Methode diese Aufgabe lösen.
1: public class LogManager
2: {
3: public void WriteToLog()
4: {
5: var logWriter = new LogWriter();
6: logWriter.WriteToLog("Hello World!");
7: }
8: }
9:
10: public class LogWriter
11: {
12: public void WriteToLog(string message)
13: {
14: File.AppendAllText(@"C:\sample.log", message);
15: }
16: }
Diese Implementierung setzt zwar die Anforderung um, aber was passiert wenn sich die Anforderungen ändern, oder neue Anforderungen hinzukommen?
Angenommen es soll nun nicht mehr in eine Datei geschrieben werden, sondern in eine Datenbank oder eine beliebige andere Quelle. Was wenn im Entwicklungssystem die Datenbank in die geloggt werden soll gar nicht verfügbar ist, wie kann man das ganze testen?!
Mit der vorliegenden Lösung sehr schwierig bis gar nicht. Es wird zwar anfängliche Anforderung umgesetzt, jedoch ist der Code weder einfach wartbar noch skalierbar und testbar.
Drehen wir den Spiess um: Lassen wir den Aufrufer, die Abhängigkeiten “zusammenbasteln”. Der selbe Logger könnte mittels einfacher Dependency Injection (hier: Constructor Injection) so aussehen:
1: public class LogManager
2: {
3: private ILogWriter _logWriter;
4:
5: public LogManager(ILogWriter logWriter)
6: {
7: _logWriter = logWriter;
8: }
9:
10: public void WriteToLog(string message)
11: {
12: _logWriter.WriteToLog(message);
13: }
14:
15: }
Die konkrete Implementierung von LogWriter wurde durch ein Interface ersetzt und die Abhängigkeit des LogManagers von der einer konkreten Implementierung wurde entfernt. Die jeweilige Instanz wird einfach über den Konstruktor zur Laufzeit (!) “injiziert”.
Welche Vorteile bring das:
- Testbarkeit: Um den LogManager zu testen reicht eine Dummy (Mock) – Implementierung von ILogWriter aus. Mehr zu Mocking
- Wartbarkeit: Ändern sich die Anforderungen können neue LogWriter (Implementierungen von ILogWriter) hinzugefügt/ausgetauscht werden.
- Separation of Concerns – Eines der Wichtigsten Prinzipien im Software Engineering
- viele, viele mehr…
Dieses, sehr einfache Beispiel, verdeutlicht, wie einfach man Dependency Injection umsetzen kann und, welche Vorteile sich sofort daraus ergeben.
Damit haben wir natürlich erst ein bisschen an der Oberfläche gekratzt. In Teil 2 der Artikelreihe werden wir sehen wie man mit Hilfe eines Frameworks (Castle Project), dynamisch zur Laufzeit entscheiden kann welche Implementierungen von Komponenten verwendet werden. Der Castle Microkernel übernimmt dabei die Rolle des Containers in Abb.2.
Das Framework nimmt einem dabei die ganze Arbeit zur korrekten Instanziierung der Objekte und der Injizierung der Abhängigkeiten ab. Im Beispiel oben, würde das Framework erkennen, dass zur Erzeugung einer Instanz von LogManager eine Implementierung von ILogWriter erforderlich ist. Welche Implementierung das sein wird, wird aus einer Konfigurationsdatei gelesen.
So kann zum Beispiel zum Testen und Entwickeln eine Dummy-Implementierung von ILogWriter eingesetzt werden. Durch eine einfache Änderung in einer Konfigurationsdatei wird die Komponente die ILogWriter implementiert auf die “echte” Implementierung geändert – ohne eine Veränderung am Quellcode !
Damit ist es möglich Anwendungen zu erstellen, die aus Komponenten zusammengesetzt sind und ohne Codeänderungen an verschiedene Umgebungen angepasst werden könnnen, rein durch die passende Konfiguration. (zB. unterschiedliche Back-End Systeme, Datenbanken, Web-Services,…)
Links:
Für Interessierte, die sich nach diesem Artikel für Software Engineering begeistern können:
Software Design Prinzipien:
Theorie:
Theoretische Einführung in Dependency Injection und Inversion of Control