Lies, damn lies, and benchmarks...
Hi, Folks! We just released RyuJIT CTP2, complete with a magical graph indicating the performance of the new 64 bit JIT compiler as compared to JIT64. I figured I'd describe the benchmarks we're currently tracking in a little more detail, and maybe include some source code where it's code that it's okay to share. Before that, though, let’s see that magical graph again (Positive numbers indicate CTP2 does better that JIT64):
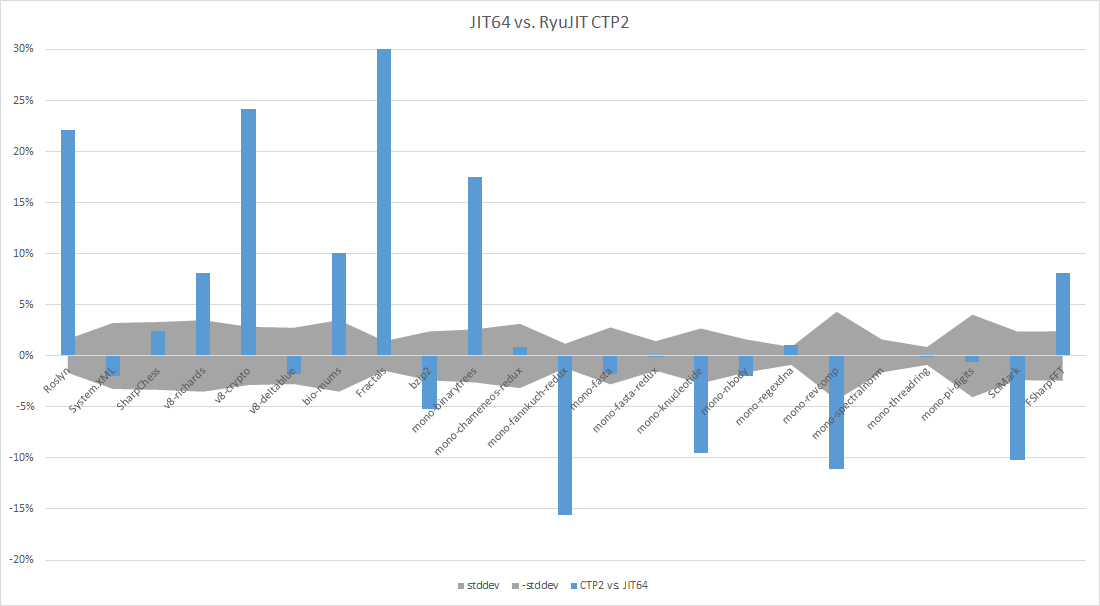
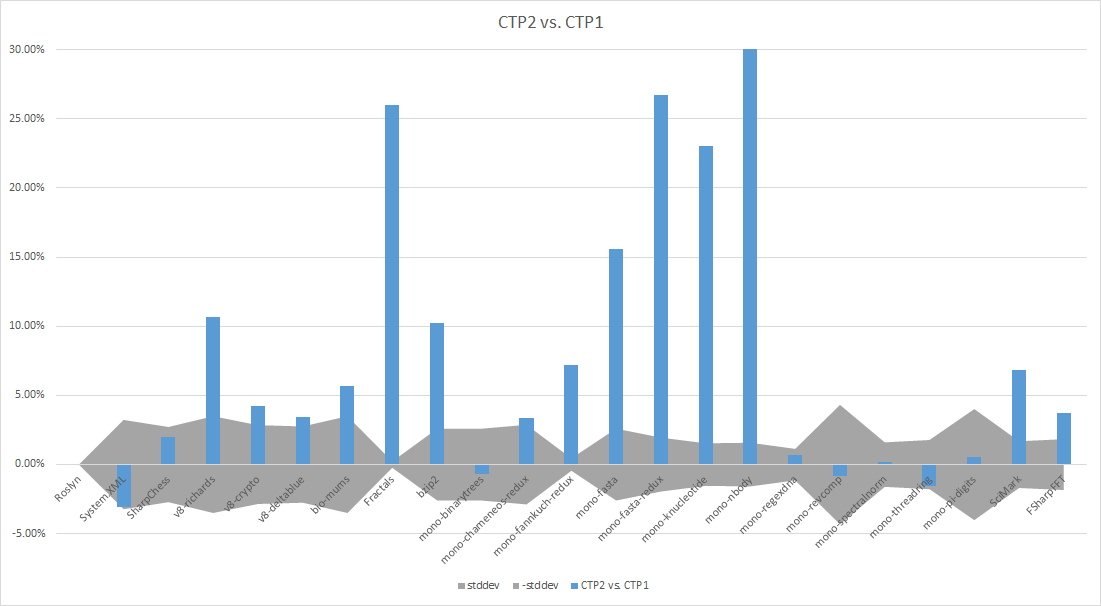
And, just for fun, let’s include one more (positive numbers indicate CTP2 does better than CTP1):
First things first: there is no rhyme or reason to the order of the benchmarks we're running. They're in a list in a file, so that's the order they run. The methodology used to measure performance is pretty straight forward: each benchmark is run once, as a "warm-up" run (get input files in the cache, etc...), then run 25 times. The average of those subsequent 25 runs is what's reported. The standard deviation is also calculated, in an effort to make it easier to detect noise from actual performance differences. The benchmarks are run on a Core i7 4850HQ, 4G RAM, an SSD, on-board video, running Windows 8.1. Nothing too fancy, just a relatively up-to-date piece of hardware that does a reasonable job of spanning laptop/mobile performance and workstation/server performance. Every benchmark is an IL-only, non-32-bit-preferred binary, so they'll all run with either a 32 or 64 bit runtime.
Now that you have a crystal clear understanding of how we're running the benchmarks, let's talk about them in left-to-right order. I'll warn you before I start: some benchmarks are better than others, and I have spent more time looking at some benchmarks more than others. That will become incredibly obvious as the discussion continues.
Roslyn:
this one is hopefully pretty self-explanatory. We perform a “self-build” of the Roslyn C# compiler: the Roslyn C# compiler reads in the C# source code of Roslyn, and generates the Roslyn compiler binaries. It’s using bits later than what are publicly available, and the source code isn’t publicly available, so this one is pretty hard for other folks to reproduce :-(. The timer is an 'external' timer: the self-build is launched by a process that has a timer, so the time reported includes process launch, JIT time, and code execution time. This one is probably the single largest benchmark we have. The improvement in JIT compile time (Throughput) accounts for more than half of the improved performance. Outside of improved throughput, there are places where we generate better code for Roslyn (code quality: CQ for short) and places where we’re worse. We’re continuing to look into performance of this code. Since the Roslyn team works closely with the .NET Runtime & Framework team, we have lots of experts in that code base nearby. One final note on Roslyn: it may appear at first glance that we did nothing here between CTP1 and CTP2, but the CTP1 build didn’t work properly. So we fixed a few bugs there to get where we are now.
System.XML:
this one should probably not really be included for RyuJIT CTP runs. It's running the XML parser against an input XML file. The reason the data isn't particularly interesting is because the XML parser is in System.XML.dll, which is NGen'ed, which means that it's actually just running code that JIT64 produced, where RyuJIT is only compiling the function that's calling the parser. Internally, we can use RyuJIT for NGen as well, so that's why it's there, but it's not showing anything observable for CTP releases of RyuJIT.
SharpChess:
This is an open source C# chess playing application written by Peter Hughes. You can download the latest version from https://www.sharpchess.com. We’re using version 2.5.2. It includes a very convenient mode for benchmarking which reads in a position, then prints out how many milliseconds it takes to calculate the next move. RyuJIT does a respectable job, keeping pace with JIT64 just fine, here.
V8-*:
these benchmarks are transliterations of JavaScript benchmarks that are part of the V8 JavaScript performance suite. A former JIT developer did the transliteration many years ago, and that’s about the extent of my understanding of these benchmarks, exception that I assume that v8-crypto does something with cryptography. Of the 3, Richards and Crypto have fairly innocuous licenses, so I’ve put them on my CodePlex site for all to enjoy. DeltaBlue due to lincensing restrictions can’t be hosted on CodePlex.
Bio-Mums:
This is a benchmark picked up from Microsoft Research’s “Biological Foundation” system several years ago. Since we grabbed it, they’ve open-sourced the work. Beyond that, I know it has something to do with biology, but just saying that word makes my brain shudder, so you’ll have to poke around on the web for more details.
Fractals:
Matt Grice, one of the RyuJIT Developers, wrote this about a year ago. It calculates the Mandelbrot set and a specific Julia set using a complex number struct type. With Matt’s permission, I’ve put the source code on my CodePlex site, so you can download it and
marvel at its beauty, its genius. This is a reasonable micro-benchmark for floating point basics, as well as abstraction cost. RyuJIT is pretty competitive with JIT64 on floating point basics, but RyuJIT demolishes JIT64 when it comes to abstraction costs, primarily due to Struct Promotion. The graph isn’t accurate for this benchmark, because RyuJIT is just over 100% (2X) faster than JIT64 on this one. But if that value were actually visible, nothing else would look signficant, so I just cropped the Y axis.
BZip2:
This is measuring the time spent zip’ing the IL disassembly of mscorlib.dll. RyuJIT is a few percent slower than JIT64. This benchmark predates the .NET built-in support for ZIP, so it uses the SharpZip library.
Mono-*:
We grabbed these benchmarks after CTP1 shipped. A blog commenter pointed us at them, and they were pretty easy to integrate into our test system. They come from “The Computer Language Benchmarks Game”. When we started measuring them, we were in pretty bad shape, but most have gone to neutral. We do still have a handful of losses, but we’re still working. For details about each benchmark, just hit up the original website. They’re all pretty small applications, generally stressing particular optimization paths, or particular functionality. Back when JIT64 started, it was originally tuned to optimize C++/CLI code, and focused on the Spec2000 set of tests, compiled as managed code. This generally tuned for optimizations that pay off in this set of benchmarks, as well. The only benchmark out of the batch that you won’t find on the debian website is pi-digits. The implementation from the original site used p/invoke to use the GMP high-precision numeric package. I implemented it using .NET’s BigInteger class instead. Again, you can find the
code on my codeplex site.
SciMark:
This one is pretty self-explanatory. SciMark’s been around a long time, and there’s a pretty reasonable C# port done back in Rotor days that now lives here. It’s a set of scientific computations, which means heavy floating point, and heavy array manipulation. Again, we’re doing much better than we were with CTP1, but RyuJIT still lags behind JIT64 by a bit. We’ve got some improvements that didn’t quite make it in for CTP2, but will be included in future updates.
FSharpFFT:
Last, but not least. When we released CTP1, there was some consternation about how F# would perform, because JIT64 did a better job of optimizing tail-calls than JIT32 did. Jon Harrup gave me an F# implementation of a Fast Fourier Transform, which I dumped into our benchmark suite with virtually no understanding of the code at all. We’ve made some headway, and are now beating JIT64 by a reasonable margin. One item worth mentioning for you F# fans out there: We’ve got the F# self-build working with RyuJIT, which was pretty excellent. Maybe we’ll start running that one as a benchmark, too!
There you have it: a quick run through of the benchmarks we run. Having read through it anyone that paid attention should be able to tell that I don’t write code, I just run the team :-). If folks would like more details about anything post questions below, and I’ll see what I can do to get the engineers that actually write the code to answer them.
Happy benchmarking!
-Kev