Just enough Azure for Hadoop - Part 2
This blog is part 2 of a series that covers relevant Azure fundamentals - concepts/terminology you need to know, in the context of Hadoop. Some of the content is a copy of Azure documentation (full credit to the Azure documentation team). I have compiled relevant information into a single post, along with my commentary, to create a one stop shop for those new to Azure and thinking Hadoop.
In part 1 of the series, I covered Azure networking. Here's what's covered in this post:
Section 05: Azure storage
Section 06: Azure blob storage
Section 07: Azure disk storage options
Section 08: Azure managed disks
Here are links to the rest of the blog series:
Just enough Azure for Hadoop - Part 1 | Focuses on networking, other basics
Just enough Azure for Hadoop - Part 3 | Focuses on compute
Just enough Azure for Hadoop - Part 4 | Focuses on select Azure Data Services (PaaS)
5. Azure Storage - overview
Azure has many offerings from a storage perspective. This section will touch on ones relevant from the Hadoop perspective.
Azure storage - offerings:
Azure Storage offers choices of non-relational data storage including Blob Storage, Table Storage, Queue Storage, and Files.
Only those relevant to the Hadoop context are covered in this section.

6. Azure Blob Storage
Is Azure's object store PaaS service and includes three types - block blobs, append blobs, page blobs. From the perspective of Hadoop, Azure Blob Storage is HDFS compatible, and you can leverage it as a secondary HDFS - to offload cool data to a cheaper storage tier, when compared to disks.
6.1. Blob Service Components:
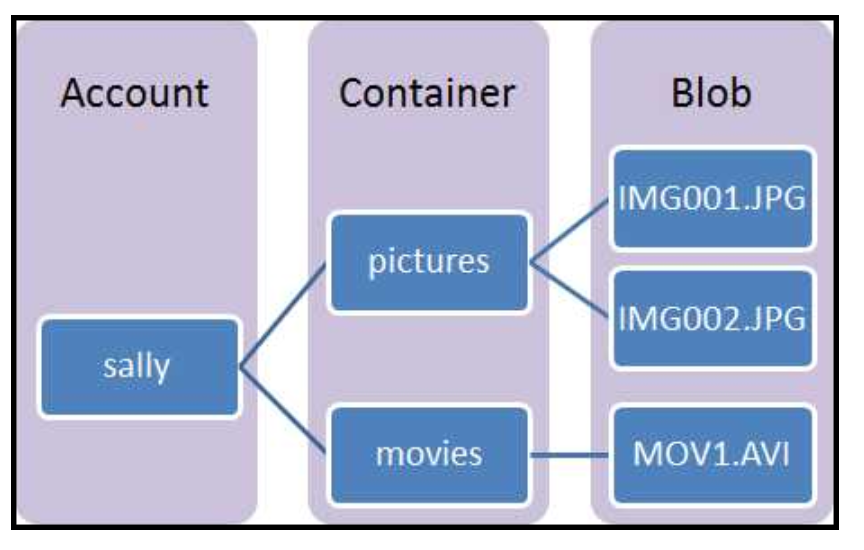
Storage Account:
Is an entity within which your provisioned Azure storage sits. All access to storage services takes place through the storage account. The storage account is the highest level of the namespace for accessing each of the fundamental services. It is also the basis for authentication.
A storage account has limits - IOPS limits, throughput limits, and a subscription has number of storage accounts limit. This details scalability limits.
This storage account can be a General-purpose storage account or a Blob storage account which is specialized for storing objects/blobs.
Container:A container provides a grouping of a set of blobs. All blobs must be in a container. An account can contain an unlimited number of containers. A container can store an unlimited number of blobs. Note that the container name must be lowercase.
Blob:
A file of any type and size. Azure Storage offers three types of blobs: block blobs, page blobs, and append blobs.
6.2. Types of blob
1. Block blob:
Block blobs are ideal for storing text or binary files, such as documents and media files.
Block blobs are the only relevant type of blob in the context of Hadoop. Block blobs are HDFS storage compatible and a block blob storage account can be attached to Hadoop cluster as auxiliary HDFS - see section below called "WASB"
2. Append blobs:
Append blobs are similar to block blobs in that they are made up of blocks, but they are optimized for append operations, so they are useful for logging scenarios.
3. Page blogs:
Page blobs are disk abstractions - can be up to 1 TB in size, and are more efficient for frequent read/write operations. Azure Virtual Machines use page blobs as OS and data disks. Page blobs are relevant in the context of Hadoop when you use unmanaged disks - covered further down in this blog.
6.3. Azure Storage redundancy options:
LRS: Locally redundant storage
LRS offers intra-datacenter redundancy - keeps 3 replicas of your data within a single facility within a single region for durability
GRS: Geo-redundant storage
This is the default option for redundancy when a storage account is created. With GRS your data is replicated across two regions, and 3 replicas of your data are kept in each of the two regions.
RA-GRS: Read-access geo-redundant storage
This is the recommended option for production services relying on Azure Storage. For a GRS storage account, you have the ability to leverage higher availability by reading the storage account’s data in the secondary region.
ZRS: Zone-redundant storage
ZRS fits between LRS and GRS in terms of durability and price. ZRS stores 3 replicas of your data across 2 to 3 facilities. It is designed to keep all 3 replicas within in a single region, but may span across two regions. ZRS currently only supports block blobs. ZRS allows customers to store blobs at a higher durability than a single facility can provide with LRS
6.4. Azure Blob Storage Feature Summary
- Is a massively scalable object store - structured and unstructured data
- Is highly available - three copies are maintained with customer charged for only one copy
- Offers redundancy options detailed in section above
- Offers strong consistency
- Offers encryption at rest with Microsoft managed keys or customer managed keys
- Offers tiers based on data temperature - hot cool, archive - with cost versus performance trade-off.
6.5. WASB and HDFS:
Storage accounts - Block blobs can be leveraged as auxiliary HDFS - and are supported by all Hadoop distributions as secondary HDFS. Microsoft contributed towards the Hadoop-Azure module of the Apache Hadoop project.
Feature summary from Apache Hadoop docs:
- Read and write data stored in an Azure Blob Storage account like it were from attached disks.
- Present a hierarchical file system view by implementing the standard Hadoop
FileSysteminterface. - Supports configuration of multiple Azure Blob Storage accounts.
- Supports both block blobs (suitable for most use cases, such as Spark, MapReduce) and page blobs (suitable for continuous write use cases, such as an HBase write-ahead log).
- Reference file system paths using URLs using the
wasbscheme. - Also reference file system paths using URLs with the
wasbsscheme for SSL encrypted access. - Tested on both Linux and Windows.
- Tested at scale
The experience is seamless other that the fact that you have to provide the WASBS URI of your blob storage to read/write - see section 6.7. You can use HDFS FS shell commands and read/write just like you would from primary HDFS.
6.6. Attaching a storage account to your Hadoop cluster:
You need to create a storage account, you will need to make an entry into core-site.xml - the storage account name, and associated access key, save and restart HDFS and dependent services.

You can encrypt the key for added security.
6.7. Interacting with your storage account from HDFS shell/Spark etc - WASB URI:
Always use wasbs scheme - wasbs utilizes SSL encrypted HTTPS access.
In general, you have provide the fully qualified blob storage URI as detailed in the example below.
% hdfs dfs -mkdir wasbs://<yourcontainer>@<yourstorageaccountname>.blob.core.windows.net/dummyDir
% hdfs dfs -put dummyFile wasbs://<yourcontainer>@<yourstorageaccountname>.blob.core.windows.net/dummyDir /dummyFile
% hdfs dfs -cat wasbs://<yourcontainer>@<yourstorageaccountname>.blob.core.windows.net/dummyDir/dummyFile
"Do what you love and love what you do"
6.8 Encryption of storage accounts attached to your Hadoop cluster:
At rest:
Azure offers storage service encryption (AES 256 bit) - server side, transparent encryption with Microsoft managed keys or customer provided keys secured in Azure Key Vault.
In transit:
When you use wasbs scheme (https), data transfer is over SSL.
6.9. Blocking wasb scheme (http) in storage accounts attached to your Hadoop cluster:
You can configure your storage account to allow only wasbs scheme.
6.10. Blocking external access to storage accounts attached to your Hadoop cluster:
Configure VNet service endpoint to your storage account and specify subnets to allow access to and configure to not allow access from elsewhere.
6.11. Distcp to WASB
You can distcp from your on-premise cluster to your Azure storage account
% hadoop distcp
hdfs://<yourHostName>:9001/user/<yourUser>/<yourDirectory> wasbs://<yourStorageContainer>@<YourStorageAccount>.blob.core.windows.net/<yourDestinationDirectory>/
6.12. Architectural considerations/best practices with using blob storage as auxiliary HDFS:
This section is specific to block blobs.
Securing:
- Encrypt at rest with Storage Service Encryption
- Encrypt during transit - Make wasbs (/https) the only mode supported for data transfer
- Encrypt the storage credentials in core-site.xml; Periodically regenerate keys for added security
- Block external access with VNet service endpoint
- Ensure the right people have access to your storage account using Azure service level RBAC
Configuring some of these from the Azure portal are covered in Azure Cloud Solution Architect, Jason Boeshart's blog
High-availability:
Out of the box
Disaster recovery:
Plan for replication to DR datacenter, just like you would with primary HDFS
Sizing:
With blob storage, size for the actual amount of data you want to store (without replicas).
E.g. Lets say you have 5 TB, with disks you would size for 5 TB * 1 only
Tiers:
Choose between hot/cool/archive based on your requirements
Pricing:
Microsoft does not charge for the replicas, and you pay per use.
Consistency:
Is strong
Constraints and workarounds:
Storage accounts come with IOPS limits - be cognizant of the same, and shard data across multiple storage accounts to avoid throttling and outages from the same
500 TB limit of storage account limit can be increased with support ticket
200 storage account per subscription limit can be increased with support ticket
Performance:
Understand performance versus cost tradeoff with using Azure blob storage as your secondary HDFS
Egress charges:
Understand that you will incur egress charges for data leaving your storage account.
6.13. Apache Ranger plug-in for WASB
Microsoft developed a Ranger plug-in for fine-grained RBAC for WASB. Will cover this in detail in subsequent blogs.
7. Azure Disks
Azure offers two flavors of disks you can attach to your Hadoop virtual machines - unmanaged and managed disks, in two performance tiers - standard and premium.
Microsoft recommends usage of managed disks - it is supported by all Hadoop distributions. The next blog, covers Azure compute and touches on important concepts like premium managed disk throughout and VM max disk throughput and optimal number of disks to attach to guarantee performance.
7.1. Unmanaged disks: At a very high level, with unmanaged disks, you have to create a storage account, and have to deal with the constraints/limits of storage account like IOPS, it offers lower fault tolerance and a higher management overhead than its managed counterpart. I wont be covering any more on unmanaged disks - prefer managed disks over unmanaged as detailed in this video.
Documentation
7.2. Managed disks:
Azure Managed Disks simplifies disk management for Azure IaaS VMs by managing the storage accounts associated with the VM disks. You only have to specify the type (Premium or Standard) and the size of disk you need, and Azure creates and manages the disk for you.
7.3. Premium Disks:
Theyare high performance Solid State Drive (SSD)-based storage designed to support I/O intensive workloads with significantly high throughput and low latency. There are several SKUs of premium disks and you choose the option which best meets your required storage size, IOPs, and throughput. They are supported by DS-series, DSv2-series, FS-series, and GS-series virtual machine sizes, at the time of writing this blog. There are no transaction costs for premium disks.
Premium managed disks is recommended for guaranteed performance in higher environments. For masters, always use premium disks, irrespective of environment.
7.4. Standard Disks:
Standard Disks use Hard Disk Drive (HDD)-based storage media (are backed by regular spinning disks). They are best suited for dev/test and other infrequent access workloads that are less sensitive to performance variability. There are several SKUs of standard disks and you choose the option which best meets your required storage size, IOPs, and throughput. There are no transaction costs for standard disks.
Standard managed can be used in lower environments for non-master nodes.
8. Azure Managed Disks
This is a fantastic video from Azure storage team and clearly details benefits of Azure managed disks over unmanaged.
https://channel9.msdn.com/Blogs/Azure/Managed-Disks-for-Azure-Resiliency
The diagrams below are from the video.
8.1. IOPS and throughput
Azure managed disk SKUs come with IOPS and throughput limits to be cognizant of. The compute section will elaborate on this again. Here is an example of what to expect..

Value proposition and features..
8.2. Enhanced availability over unmanaged disks Azure managed disks offer enhanced storage availability. Lets say if you have an availability set with multiple VMs, with managed disks, managed disks will be placed in separate storage units per VM for higher availability.

In the above diagram, on the left, say you used unmanaged disks, and put all your masters in an availability set, you could actually lose all masters because the storage could be a SPOF. With the managed disk option, notice how Azure will ensure the VM attached disks are isolated into separate storage units for better fault tolerance.
8.3. Simplifies creation of multiple VMs with same custom image
With unmanaged disks, if you have a custom image you want to propagate across multiple VMs, you have to copy the same across multiple storage accounts, as there is a cap on number of VMs per storage account - effectively an administrative overhead.
With managed disks, you can create a managed disk image, then capture a VM you need to replicate - this will capture all the VM metadata, it gets saved to the same resource group by default, you can then use it to provision multiple VMs with the same VM image. Some examples are - Cloudera Centos 7.3 image in the marketplace, a base VM image of a Hadoop slave node etc
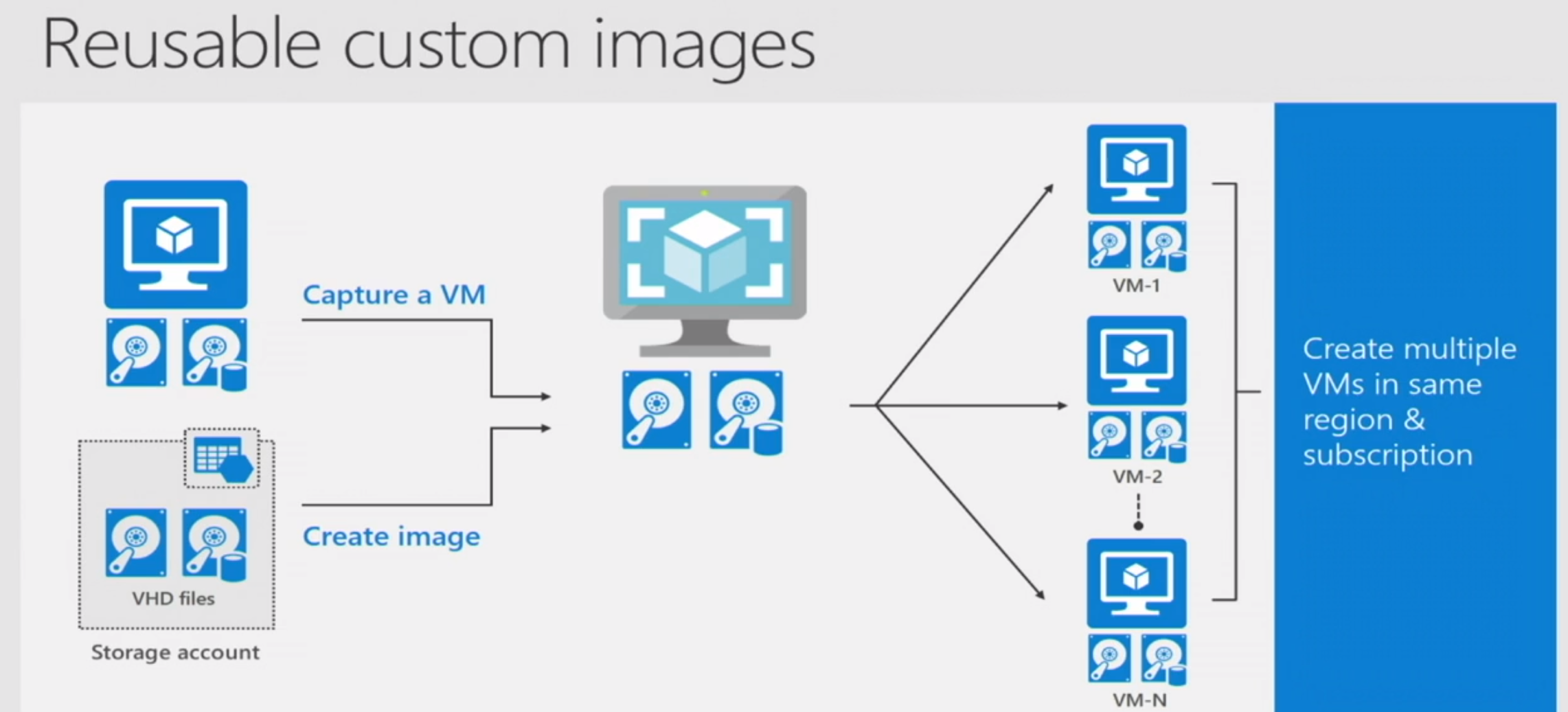
Creating a Linux VM image - documentation
In the context of Hadoop, you would, create base images of each node type and then clone them programmatically.
E.g. an image of a master node, an image of a worker node.
8.4. Create managed disk snapshots independent of the disks themselves
You can create a snapshot of managed disks and persist the same, and can even delete the managed disks after snapshotting.
This is helpful for backup/DR scenarios or for testing scenarios (e.g. financial month-end/quarter-end/year-end point-in-time snapshots of data)

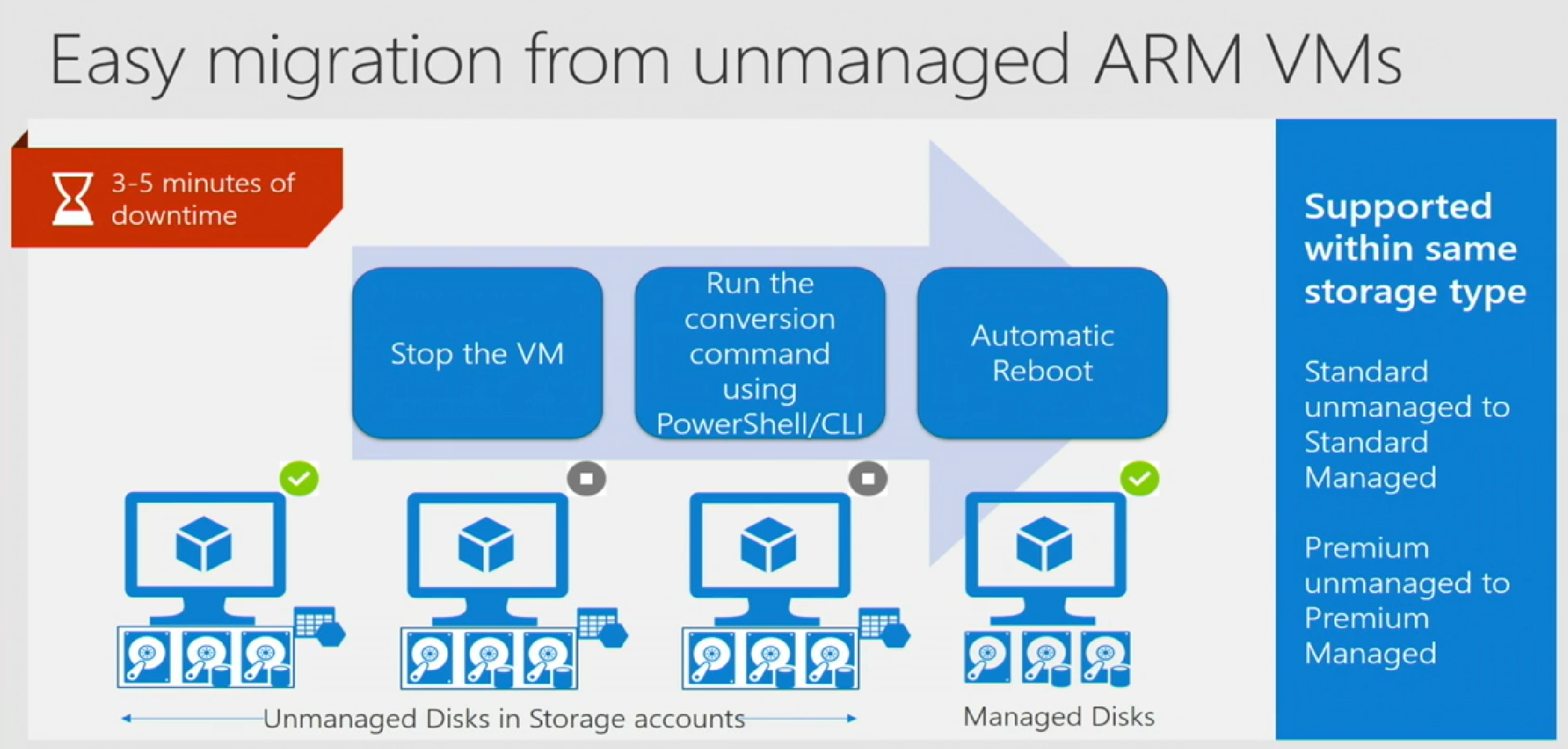
8.5. Simplified upgrade/downgrade between standard and premium managed disks The picture says it all - stop the VM, update storage type, reboot.

Where would this be useful:
Lets say - you build a cluster for a PoC/dev/test environment, and once done, want to upgrade that to production, and while in the lower environments, for cost optimization, you went for standard disks, you want the best performance in production with premium managed disks; Another example - when your engineers are doing development, maybe use standard disks and when its time to tune performance, switch to premium and then back for cost optimization.
Documentation
An example here is, periodic snapshots of your Hadoop services metastore disks.
8.6. Converting from unmanaged to managed disks
No worries if you have already provisioned unmanaged disks, we have a conversion process that will switch your disks from unmanaged to managed with a few commands.
8.7. Simplifies scaling VMs Managed Disks handles storage for you behind the scenes. Previously, you had to create storage accounts to hold the disks (VHD files) for your Azure VMs. When scaling up, you had to make sure you created additional storage accounts so you didn't exceed the IOPS limit for storage with any of your disks. With Managed Disks handling storage, you are no longer limited by the storage account limits (such as 20,000 IOPS / account). You also no longer have to copy your custom images (VHD files) to multiple storage accounts. You can manage them in a central location – one storage account per Azure region – and use them to create hundreds of VMs in a subscription.
Managed Disks will allow you to create up to 10,000 VM disks in a subscription, which will enable you to create thousands of VMs in a single subscription.
8.8. Disk-level RBAC You can use Azure Role-Based Access Control (RBAC) to assign specific permissions for a managed disk to one or more users. Managed Disks exposes a variety of operations, including read, write (create/update), delete, and retrieving a shared access signature (SAS) URI for the disk. You can grant access to only the operations a person needs to perform his job. For example, if you don't want a person to copy a managed disk to a storage account, you can choose not to grant access to the export action for that managed disk. Similarly, if you don't want a person to use an SAS URI to copy a managed disk, you can choose not to grant that permission to the managed disk.
8.9. Azure Backup Service Support
Use Azure Backup service with Managed Disks to create a backup job with time-based backups, easy VM restoration and backup retention policies. Managed Disks only support Locally Redundant Storage (LRS) as the replication option; this means it keeps three copies of the data within a single region. For regional disaster recovery, you must backup your VM disks in a different region using Azure Backup service and a GRS storage account as backup vault.
8.10. Managed Disk Snapshot
A Managed Snapshot is a read-only full copy of a managed disk which is stored as a standard managed disk by default. With snapshots, you can back up your managed disks at any point in time. These snapshots exist independent of the source disk and can be used to create new Managed Disks. They are billed based on the used size. For example, if you create a snapshot of a managed disk with provisioned capacity of 64 GB and actual used data size of 10 GB, snapshot will be billed only for the used data size of 10 GB.
8.11. Managed disk image
Managed Disks also support creating a managed custom image. You can create an image from your custom VHD in a storage account or directly from a generalized (sys-prepped) VM. This captures in a single image all managed disks associated with a VM, including both the OS and data disks. This ties into #2 above.
8.12. Image versus Snapshot With Managed Disks, you can capture a VM image of a generalized VM that has been deallocated. This image will include all of the disks attached to the VM. You can use this image to create a new VM, and it will include all of the disks.
A snapshot is a copy of a single disk at the point in time it is taken. If a VM has only one disk, you can create a VM with either tyhe image or the snapshot. If you have multiple disks attached to a VM, and they are striped - the snapshot feature does not support this scenario yet, you have to create an image to replicate the VM.
8.13. Encryption at rest The two kinds of encryption are available - Storage Service Encryption (SSE) - at the storage service level, and Azure Disk Encryption (ADE) at the disk level (OS and data disks). Both persist keys to Azure Key Vault.
SSE is enabled by default for all Managed Disks, Snapshots and Images in all the regions where managed disks is available.
WRT to ADE, for Linux, the disks are encrypted using the DM-Crypt technology.
From the perspective of Hadoop, HDFS encryption is at the application layer, sensitive information can spill to disk. You may want to use Azure Disk Encryption in addition to HDFS encryption.
8.14. High-availability
Three replicas are maintained, and are designed for 99.999% availability. .
8.15. Pricing and billing Considerations: Disk tier - premium versus standard
Disk SKU/size
Number of transactions - applicable for standard disks only
Egress
Snaphots
In summary
Always leverage managed disks for Hadoop - primary HDFS, use premium disks for masters and workers, for cost optimization with performance tradeoff, you can use standard disks for workers. For further cost optimization, leverage Azure Blob Storage where possible.
In my next blog, I cover Azure compute and resurface managed disks in the context of availability, images/snapshots, optimal number of premium managed disks to attach to a VM for guaranteed performance.
Blog series
Just enough Azure for Hadoop - Part 1 | Focuses on networking, other basics
Just enough Azure for Hadoop - Part 2 | Focuses on storage
Just enough Azure for Hadoop - Part 3 | Focuses on compute
Just enough Azure for Hadoop - Part 4 | Focuses on select Azure Data Services (PaaS)
Thanks to fellow Azure Data Solution Architect, Ryan Murphy for his review and feedback.