Provisioning a Cloudera Hadoop cluster on Azure
This post covers how to provision a Cloudera-certified Hadoop IaaS cluster on Azure, for Production, from the Azure Preview Portal using an Azure Resource Manager template available in the marketplace that was developed by Cloudera. At the time of writing the blog, the CDH version was 5.6.0.
Details covered are:
1. Cluster options
2. Instructions on provisioning a cluster
3. Services enabled on the cluster
4. Nodes and Roles
5. Infrastructure
6. Connecting to the cluster
7. Versions
8. Notes/Constraints
9. References
1.0. Cluster options
There are two options you can select from, a Production cluster and a PoC cluster. With both, you can configure the number of data nodes. The underlying virtual machine sizes will differ with the "Production" cluster running a higher-end virtual machine.
2.0. Step by step instructions for provisioning a cluster
Prerequisites - Create a resource group
1. Go to https://ms.portal.azure.com
2. Click on resource groups on the left navigation bar
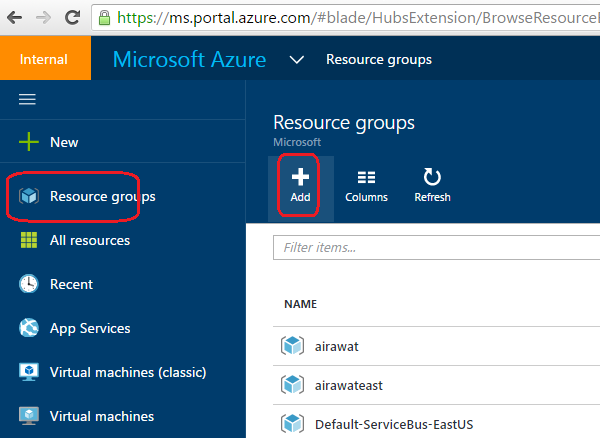
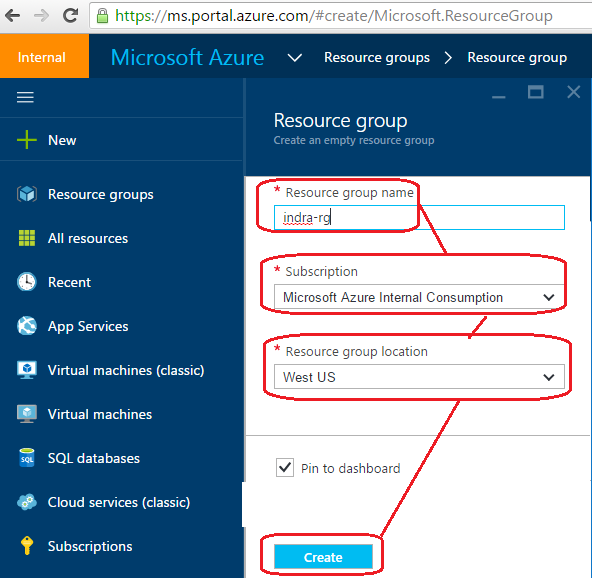
3. Enter a name for your resource group, pick the subscription and availability region and click on "create".
This will create a resource group that we will use in the cluster setup.
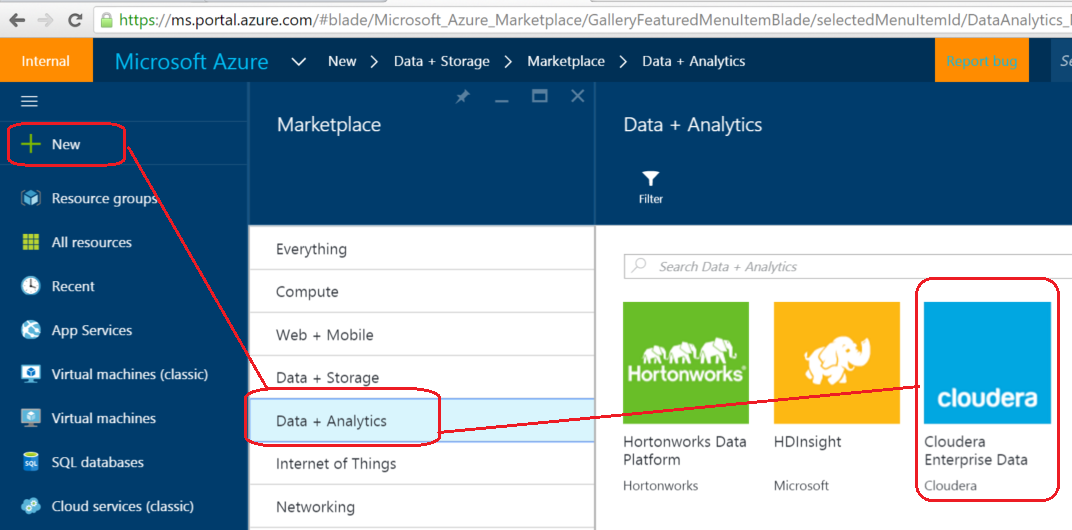
Cluster setup
4. Click on "New", then on "Data + Analytics" and then on "Cloudera Enterprise Data Hub"
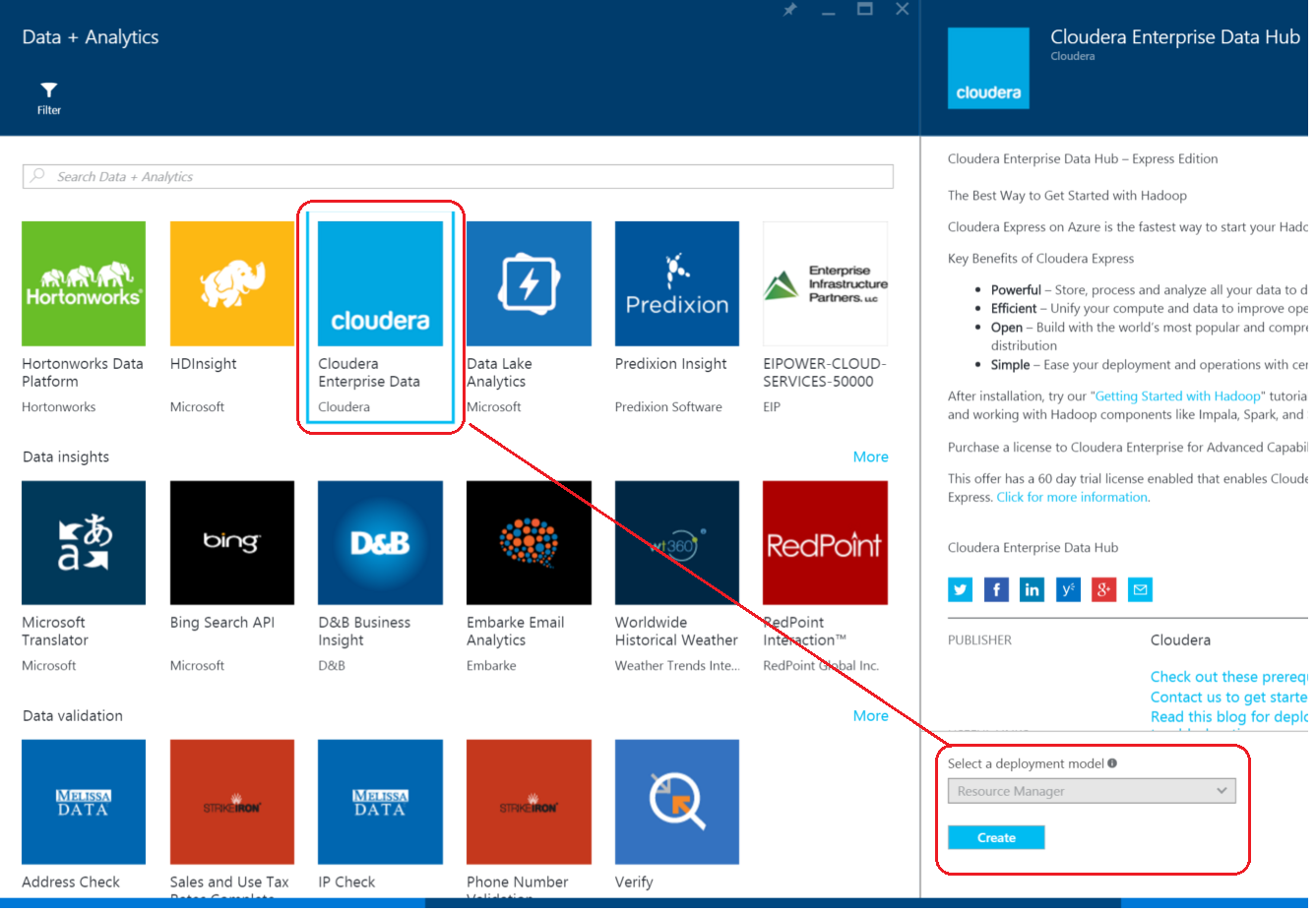
5. In the blade that opens up, under "Select deployment model", click on "Resource Manager", the click "Create"
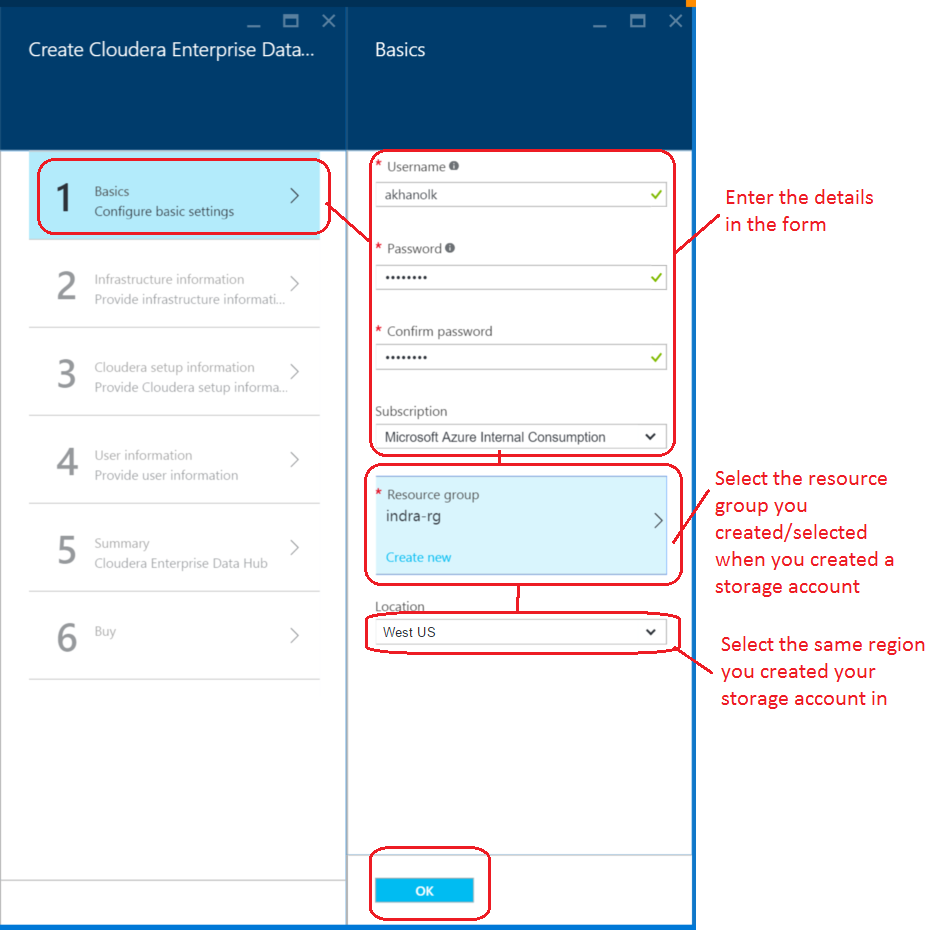
6. In the blade that opens, click on "Basics, Configure basic settings"; Here, enter the following:
User name (Linux user)
Password
Azure Subscription ID (select from pre-filled dropdown)
Resource group (Select group created as part of the prerequisites)
Geographic region (select from pre-filled dropdown)
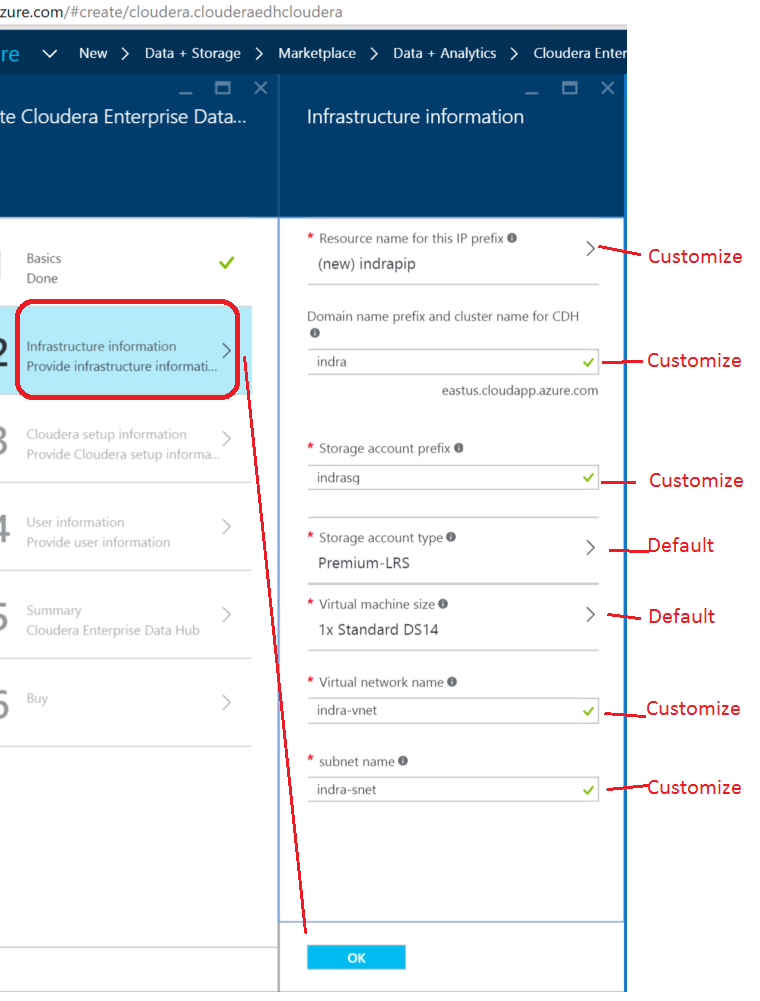
7. Next, click on "Inftrastructure information"; See screenshot below for where you can customize, and where to leave defaults.
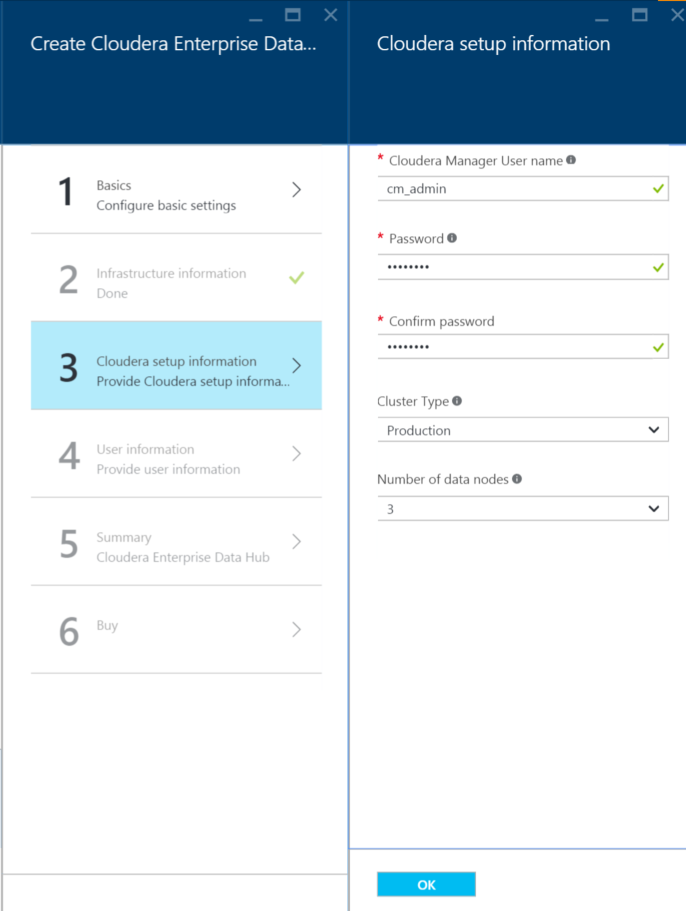
8. Next, click on "Cloudera setup information"; Here, enter the following:
Cloudera Manager User Name
Password
Cluster Type (two options - POC and Production)
Number of data nodes
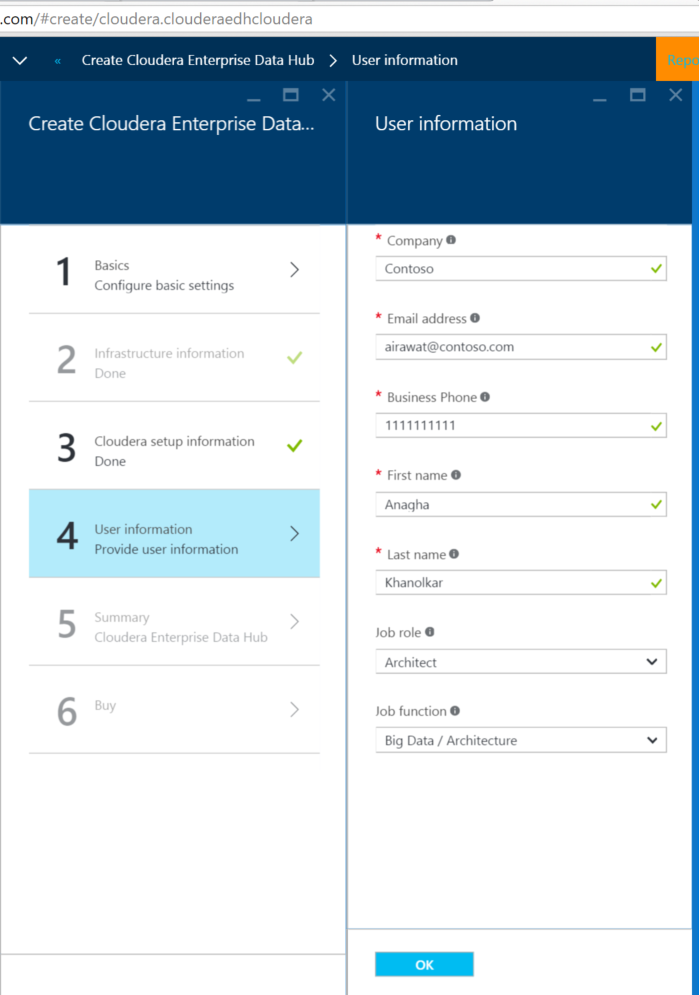
9. Click on user information, enter some details about yourself.
10. Review your input on the "Summary":
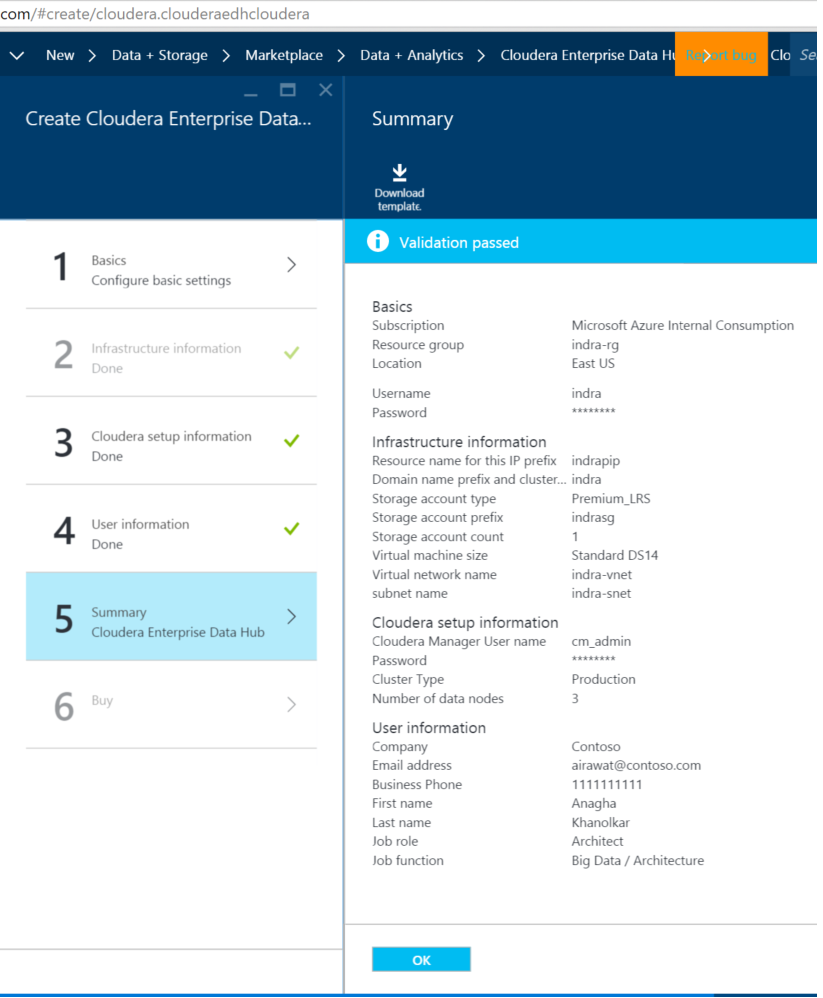
11. Click on "Buy" and then create. This will provision the cluster.
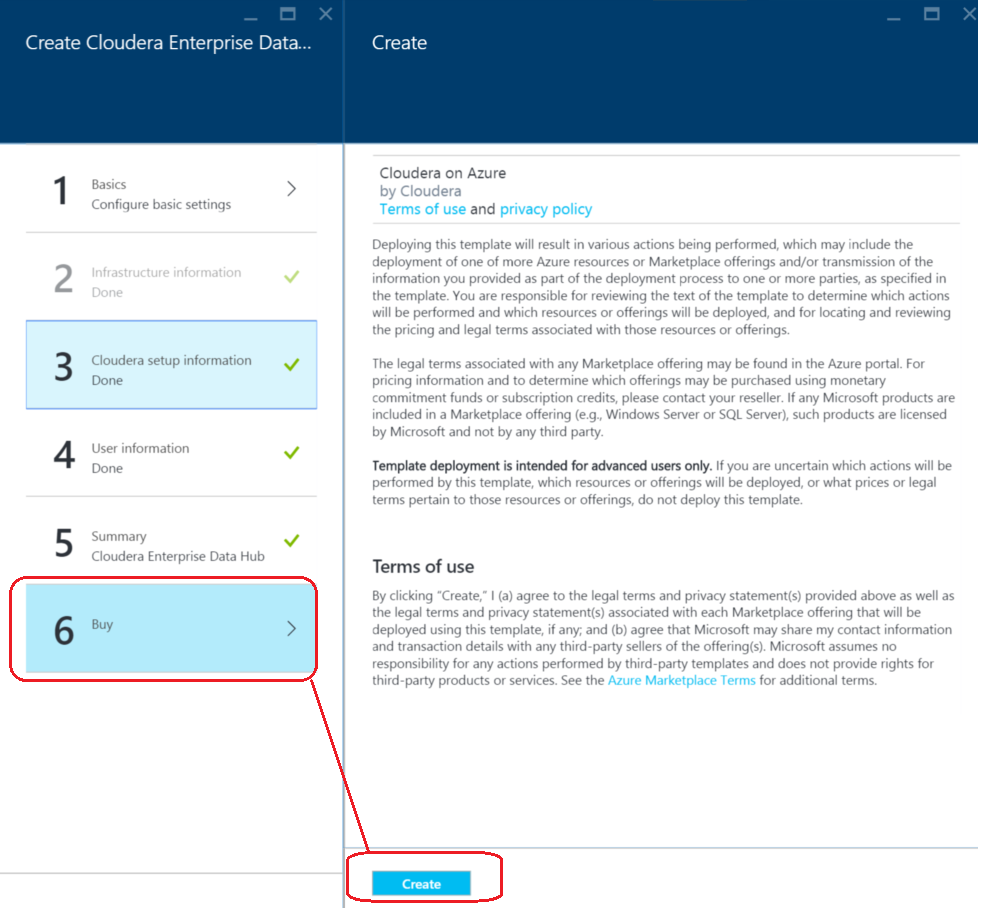
12. Step away for a long break; At the time this post was written, it took more than an hour.
You can monitor the progress from the portal.
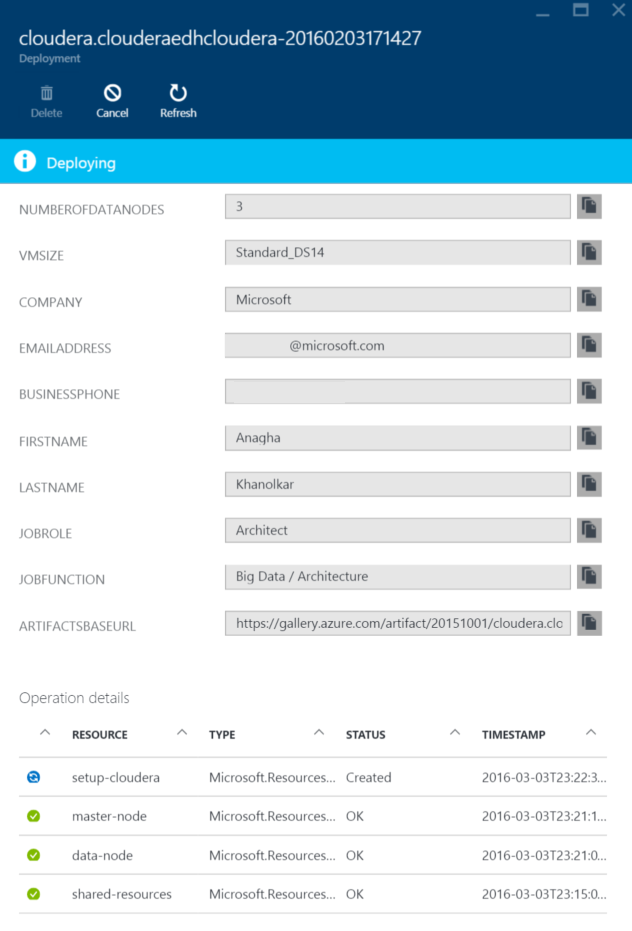
You will see a message on the portal that the deployment is complete.
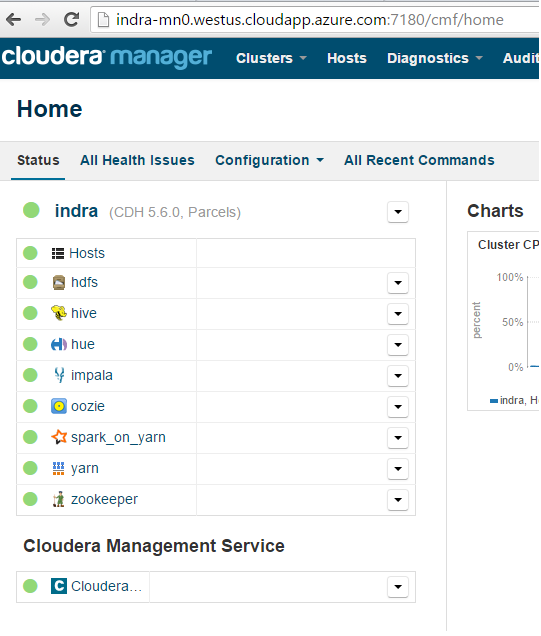
3. Services enabled on the cluster
The following services are enabled on the cluster:
HDFS
YARN
Hive
Hue
Impala
Oozie
Spark on YARN
Other distributed processing services that were available for enabling at the time of this post were:
Mapreduce, Accumulo, Flume, Kafka, HBase, Solr, Mapreduce, Sqoop
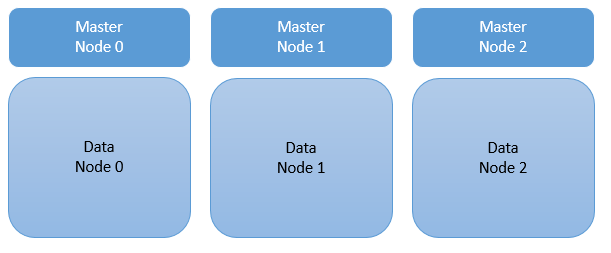
4. Nodes and Roles
In the setup, we entered 3 data nodes, and selected Production.
The following are the nodes and the roles running on them:
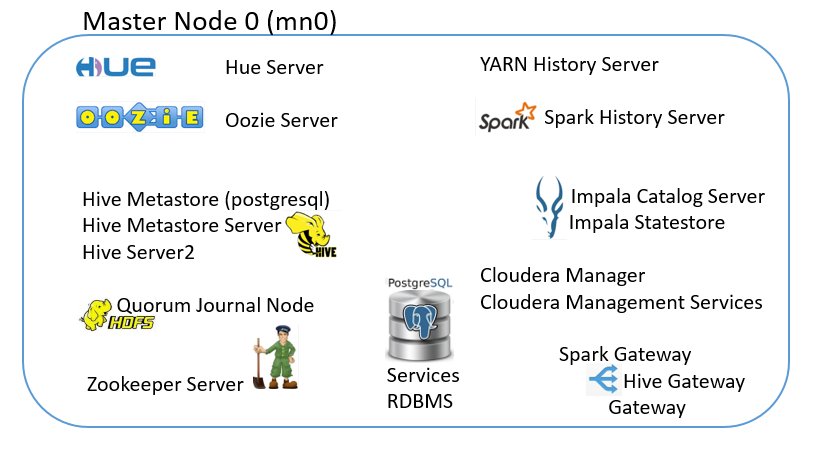
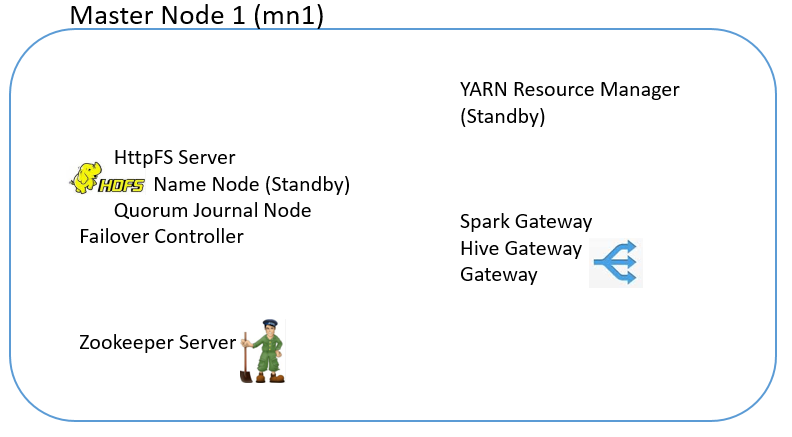
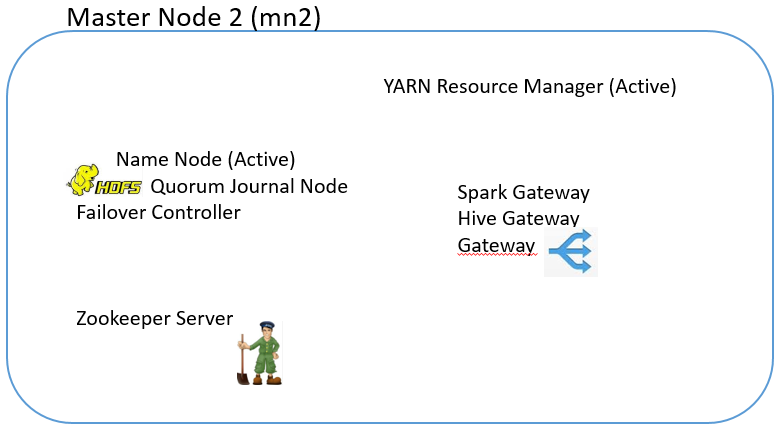
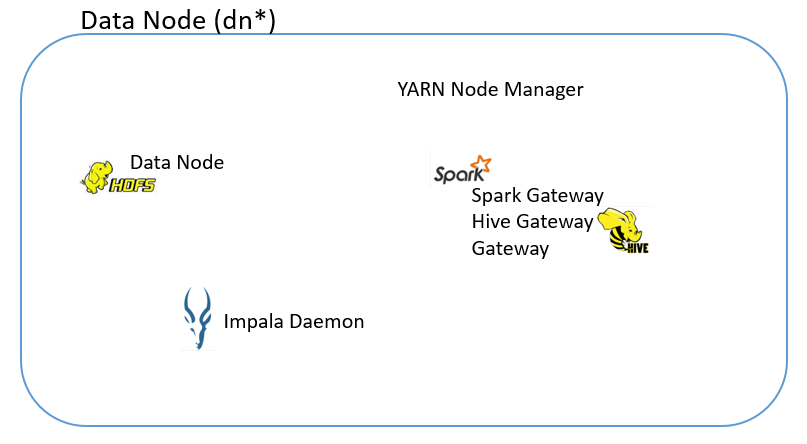
5.0. Infrastructure
5.0.1. Operating System
CentOS 6.6
5.0.2. Virtual Machine
Type: DS14
Cores: 16
Memory: 112 GB
Network: 10Gbps
Local storage: SSD-based, 200 GB
5.0.3. Storage
Storage is NOT ephemeral, and data persisted will survive a reboot, or powered off VM
5.0.3.a) Master Node: Premium, 4, 512 GB VHDs
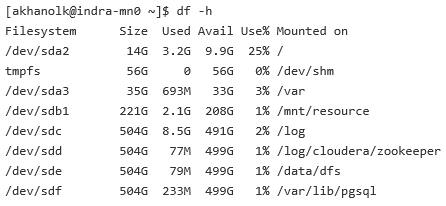
5.0.3.b) Data Node: Premium, 10, 1TB VHDs, can increase up to 31 per VM; 512 GB VHD for logs
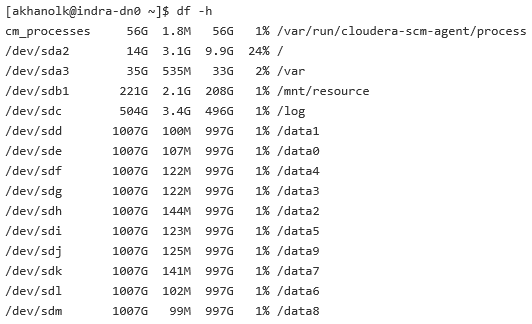
5.0.4. Services RDBMS
Cloudera Manager, Hive, Oozie, Hue are some services that require an underlying RDBMS.
The following are the database configured by the ARM template deployment:
Hue is configured to use embedded SQLLite DB
Oozie is configured to use embedded Derby DB
Hive metastore is configured to use external PostgreSQL database
Cloudera Manager services use an external MySQL database
Embedded databases are not recommended for Production workloads.
Databases for all services, except Hue, can however be migrated, as needed, to other Cloudera supported databases.
Details on supported databases can be found here- Link
5.0.4. Network Diagram
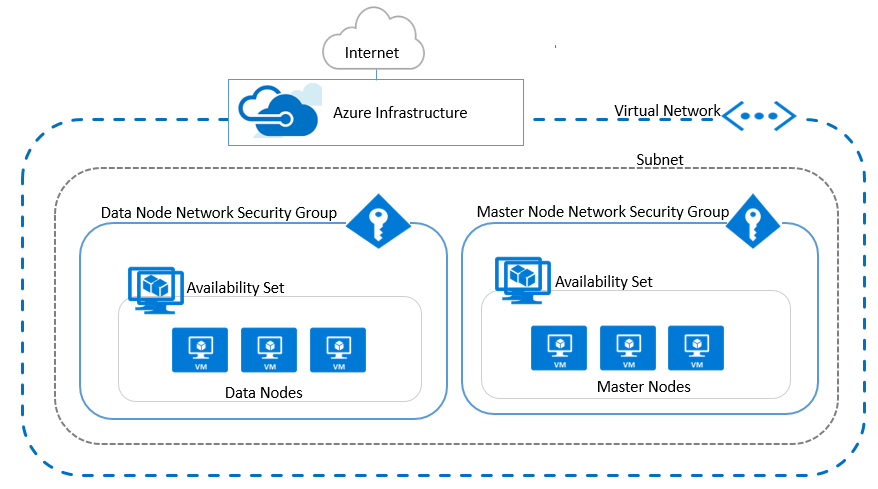
- A static public and static private IP per VM
- Network Security Groups control inbound traffic with only CDH role-specific ports open
5.0.5. Master Node Network Security Group - inbound rules 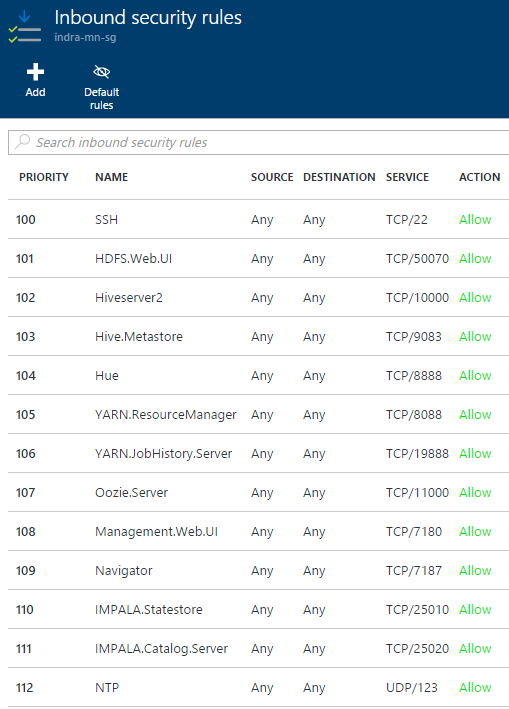
5.0.6. Data Node Network Security Group - inbound rules 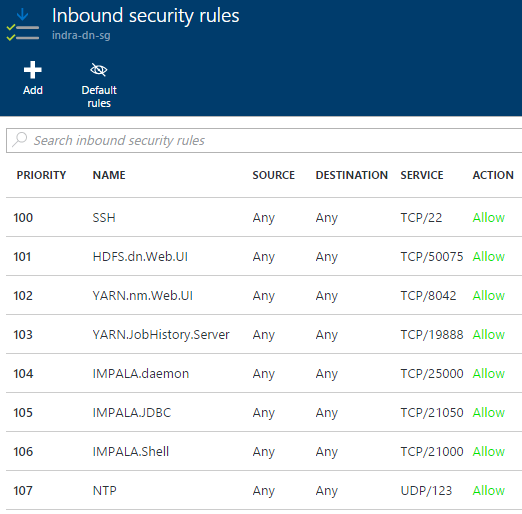
6.0. Connecting to the cluster
6.0.1. Cloudera Manager
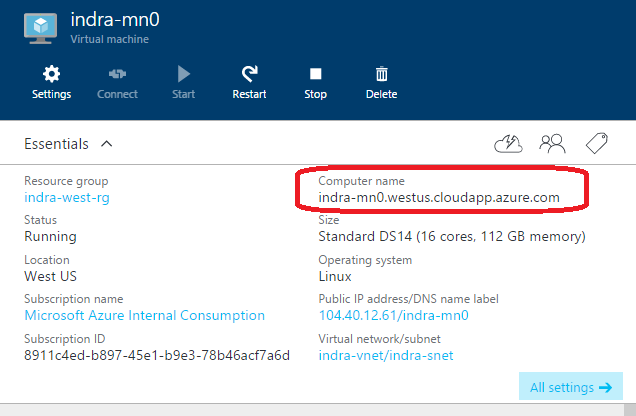
On the Azure portal, click on the resource group and look for the master node 0.
Get the FQDN of this node; The URL for Cloudera Manager is:
https://<FQDN of Master Node 0f your deployment>:7180
6.0.2. Connecting to individual nodes
ssh <userYouSetup>@<publicIPOfNode>
OR
ssh <userYouSetup>@<dnsNamePrefix>-mn0.<region>.cloudapp.azure.com
7.0. Versions At the time of writing this post, March 6, 2016, the version deployed was CDH5.6.0.
| Component | Package Version |
| Apache Avro | avro-1.7.6+cdh5.6.0+112 |
| Apache Crunch | crunch-0.11.0+cdh5.6.0+77 |
| Datafu | pig-udf-datafu-1.1.0+cdh5.6.0+17 |
| Flume-ng | flume-ng-1.6.0+cdh5.6.0+30 |
| Apache Hadoop | hadoop-2.6.0+cdh5.6.0+1025 |
| Hadoop Mrv1 | hadoop-0.20-mapreduce-2.6.0+cdh5.6.0+1025 |
| Hbase | hbase-1.0.0+cdh5.6.0+300 |
| Hbase-solr | hbase-solr-1.5+cdh5.6.0+57 |
| Apache Hive | hive-1.1.0+cdh5.6.0+377 |
| Hue | hue-3.9.0+cdh5.6.0+365 |
| Apache Impala (Incubating) | impala-2.4.0+cdh5.6.0+0 |
| Kite SDK | kite-1.0.0+cdh5.6.0+119 |
| Llama | llama-1.0.0+cdh5.6.0+0 |
| Apache Mahout | mahout-0.9+cdh5.6.0+26 |
| Apache Oozie | oozie-4.1.0+cdh5.6.0+235 |
| Apache Parquet | parquet-1.5.0+cdh5.6.0+174 |
| Parquet-format | parquet-format-2.1.0+cdh5.6.0+12 |
| Apache Pig | pig-0.12.0+cdh5.6.0+73 |
| Cloudera Search | search-1.0.0+cdh5.6.0+0 |
| Apache Sentry (Incubating) | sentry-1.5.1+cdh5.6.0+121 |
| Apache Solr | solr-4.10.3+cdh5.6.0+339 |
| Apache Spark | spark-1.5.0+cdh5.6.0+115 |
| Spark-netlib | spark-netlib-master.2 |
| Apache Sqoop | sqoop-1.4.6+cdh5.6.0+33 |
| Apache Sqoop2 | sqoop2-1.99.5+cdh5.6.0+34 |
| Apache Whirr | whirr-0.9.0+cdh5.6.0+17 |
| Zookeeper | zookeeper-3.4.5+cdh5.6.0+91 |
8.0. Notes/Constraints
At the time this post was written:
1. The template supports initial provisioning only
2. All VMs have public IPs
3. Connectivity to nodes is using a UID and password SSH key support has be added post-provisioning
4. There is no edge node provisioned; Every node is configured as a gateway. Based on your company's philosophy on edge nodes, and Cloudera's recommendation on ratio of edge nodes per data nodes, they can be provisioned manually using the Cloudera centos 6.6 image available in the marketplace.
5. Some services use embedded databases; See section 5.0 - Infrastructure; These can easily be migrated to external databases that are recommended for Production workloads.
Details on supported databases can be found here- Link
Details on migrating database by service can be found in Cloudera documentation sites, easily
9.0. References Cloudera Reference Architecture for Azure Cloudera Quick Start ARM Template