Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Windows Blog Archive
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
aaron margosis
Azure AD
Chris Jackson The App Compat Guy
ConfigMgr
fixing lua bugs
Internet Explorer
lua buglight
Mark Russinovich
mdt
michael niehaus
Microsoft Update Catalogue
non admin
presentations
Security
sysinternals
usmt
Utilities
vistawin7
Windows 10
windows-10
Windows 7
windows 8
Windows 8.1
windows 8 1
Windows Analytics
Windows as a service
Windows Autopilot
Windows Defender ATP
Windows Defendor
Windows Hello
Windows Insider
Windows IT Pros
Windows Update for Business
WIP
WSFB
WSUS
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed
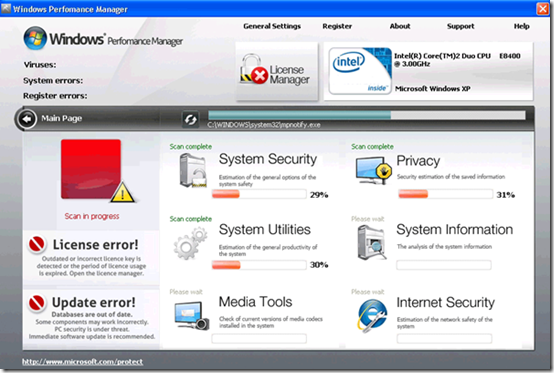
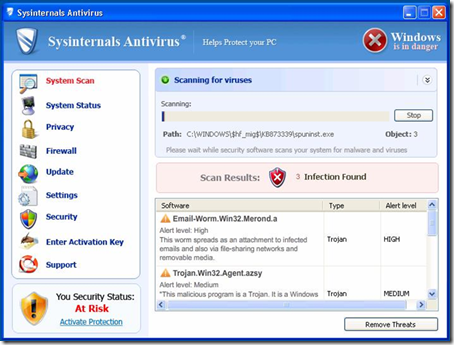





7,415

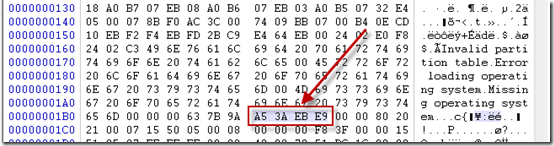
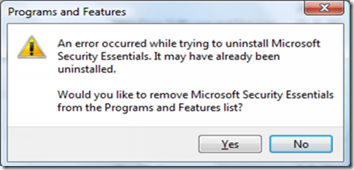

8,504
7,793
7,988

11.4K




6,791

16.4K
Latest Comments