Muenchian Grouping and Sorting in BizTalk Maps
Update many years later... Check out this improved approach: https://code.msdn.microsoft.com/Muenchian-Grouping-and-790347d2
First, I'll admit the title of this post isn't entirely accurate, because you can't do the grouping and sorting I'm about to show using the BizTalk mapper. We'll be overriding the XSLT for a BizTalk map, so therefore it might be more appropriate to call this "Muenchian Grouping and Sorting in XSLT." But since I'm doing this from a BizTalk perspective, I can live with the subtle difference. :)
Let's say I have a flat file schema to import sales order information. Being a flat file, we can assume that it's completely denormalized, meaning there won't be defined relationships and we'll have redundant data. Let's take a simplified flat file that looks something like this:
Order222|Item123 Order111|Item456 Order222|Item789
Notice that for each line, we repeat the sales header info (in this case it's just "OrderID," but typically this would include customer info, order date, etc.) again and again. Our schema ends up looking like this:
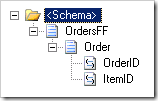
However in our destination schema, we want to group the line data for each header, and we want to sort it, too. Here's the destination schema we need to use.
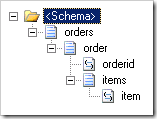
Sounds like fun, right? Great! Let's get started...
What I like to do first is to create a new BizTalk map, and then steal its XSLT to use as a template. This way we know the namespaces and such are correct. So I've created a new BizTalk map and added our OrdersFF as the source schema and our Orders schema as the destination. Right-click on the map and choose "Validate," then steal the output ".xsl" file. Then click on the functoid grid in the graphical map, and set the Custom XSL Path property to your saved .xsl file.
Within the XSLT, we're going to be using a method called the Muenchian Method to handle the grouping and sorting. This method allows us to group and sort data very quickly (faster than some of the grouping options you can do with the graphical mapper, in fact).
Just below the <xsl:output> block of our XSLT, we're going to create a key value for this grouping. This creates an index which the transform engine can use to loop through each unique value of that key.
<xsl:key name="groups" match="Order" use="OrderID"/>
From there, at the top of where we're going to start our /Orders branch, we can modify the "for-each" block to loop through our key instead of source nodes, like we might typically do.
<xsl:for-each select="Order[generate-id(.)=generate-id(key('groups',OrderID))]">
If we want to apply sorting, we can add:
<xsl:sort select="OrderID" order="ascending"/>
Finally we loop through the "groups" key we created before and output our data:
<xsl:for-each select="key('groups',OrderID)">
The whole /orders branch of our XSLT now looks something like this:
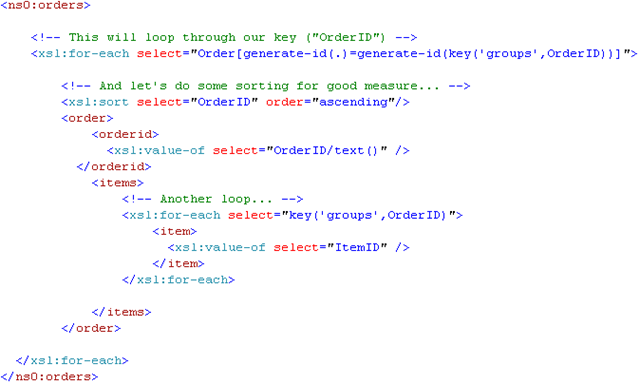
And here's the XML output:
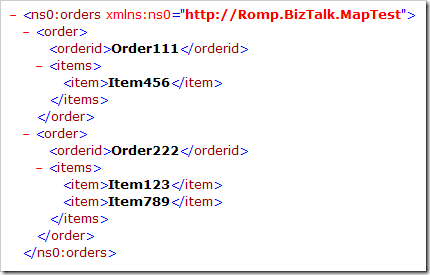
Notice that the orders are now sorted, despite being unsorted in the source file, and the items are now grouped by order. Nifty, huh?
Sample code: