Why Pay for Sorting If You Don't Need It? (2 of 3)
In our last blog post, we briefly discussed high cost of LSM Trees. Here we introduce how data are organized in LSM trees and the cost induced.
LSM Tree Compaction
In a LSM tree, data are divided into multiple levels. New records are inserted into a memory buffer where all records are stored in order. When the buffer is full, content of the buffer is written to SSD or hard disk as a file in Level 0 (L0 for short). As a result, files in L0 have overlapping key ranges.
From L1 onward, each entire level is a sorted run, with files within a level having non-overlapping key ranges. Figure 1 is from a presentation about RocksDB, illustrating leveled storage and compaction. When the total size of the data in Li exceeds a threshold, a file from Li is removed from that level and merged with multiple files in Li+1 using merge sort. This operation is called a compaction. Unlike other levels, in a compaction from L0 to L1, all the files in L1 must participate in the compaction.
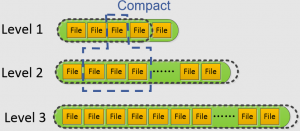
Figure 1: LSM Level Based Compaction
Deciding how many levels to use is a delicate balance. If the number of levels is too small, then one file in Li has to be merged with too many files in Li+1. This increases the amount of computation and write amplification in a single compaction, pushing performance variance to an extreme. On the other hand, If the number of levels is too large, it hurts read performance, as a read may need to check all the levels to find a key.
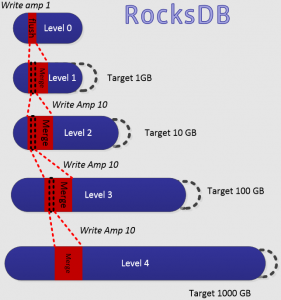
Figure 2: Compaction Induced Write Amplification
Figure 2 also comes from the same presentation about RocksDb, giving us a rough estimate about write amplification. Each compaction has a 10 time blow up. When all levels are close to full, adding one file into L0 would induce cascading compaction operations on each level, resulting in more than 40 write amplifications.
And then there are read amplifications, which means the data store reads in more data than what’s requested by the client. To serve a read request, an LSM may needs to check all the levels to find the key. This may involve reading multiple files. Using of bloom filter can reduce number of file scans, with increased memory consumption. Each file is organized as a B-tree. It may take multiple reads to load the requested record.
Moreover, there are compaction induced reads. The 40 times blow up of writes are accompanied by same number of reads. Read amplification does not hurt SSD life. However, it hogs up SSD and bus bandwidth, amplifies the performance variance, and reduces the total IOPS available to the client.
Keep in mind that all these extra read and write not only cost IOPS, but also CPU and memory. And they are caused by the need to keep data sorted.
In the next blog post, we explain in detail how to construct a memory efficient index, to provide an option to avoid the cost of data sorting.