Troubleshooting a DCOM issue: Case Study
Hi all,this is my first post after a LONG LONG time since I created the (so far empty) blog. I guess it is not by coincidence that last night it snowed in Milan .
Let's get started with the case study at hand. In the Distributed Services team in Microsoft Developer Support we support technologies for developing distributed systems, including DCOM/COM+, Distributed Transactions, Windows Communication Foundation (WCF), Workflow Foundation (WF), CLR COM Interoperability, and more.
This case study refers to a DCOM problem which I have been handled recently. The purpose is not only to go into some details on how some pieces of DCOM work, but also to show a troubleshooting strategy for these types of issues.
Problem Definition
The problem can be summarized as follows: a client-server DCOM application works perfectly fine but, from time to time, an XML operation on the server fails with error -2147417856. This happens mainly when a long-running DCOM call is in progress from the client to the server, and only on some machines. Other machines running the same application are unaffected.
The operating system is Windows XP.
First Steps
First, HRESULT -2147417856 is hexadecimal 0x80010100 and symbolic RPC_E_SYS_CALL_FAILED, defined in the header file winerror.h:
// MessageId: RPC_E_SYS_CALL_FAILED
//
// MessageText:
//
// System call failed.
//
#define RPC_E_SYS_CALL_FAILED _HRESULT_TYPEDEF_(0x80010100L)
The HRESULT's facility is 0x0001 or FACILITY_RPC, which means this error comes from the RPC layer. This tells us that we should focus on the lower-layers of the DCOM communication infrastructure instead of the application layer (customer code).
Second, we need to better understand what an "XML operation on the server fails" really means. Upon further investigation it turns out that a method of a server-side DCOM object is receiving an IStream COM object from the client, and it is calling msxml's IXMLDOMDocument::load(), passing the IStream object as an argument. In pseudo-code:
HRESULT MyObj::Method1(IStream* pXml)
{
IXMLDOMDocument* pDoc;
// create the document object here
// ...
return pDoc->load(pXml);
}
It could therefore be that the problem is not so much in the msxml DOMDocument object, but instead in the IStream object which is being passed as an argument: the load() implementation will call methods on the IStream object in order to read XML from the stream and, most likely, will fail if any of those methods fails.
So let's modify the server's code implementation so that we make a preliminary call to the client's IStream object and check its return value:
HRESULT MyObj::Method1(IStream* pXml)
{
IXMLDOMDocument* pDoc;
// create the document object here
// ...
// make a method call to the IStream object and check its value
HRESULT hr;
if (FAILED(hr = pXml->Seek(0, STREAM_SEEK_SET, NULL))
{
// log the failure here
}
return pDoc->load(pXml);
}
With this change in place, the next occurrence of the problem tells us that, indeed, the Seek() method on the IStream object fails, returning RPC_E_SYS_CALL_FAILED. This is our current understanding of the issue:
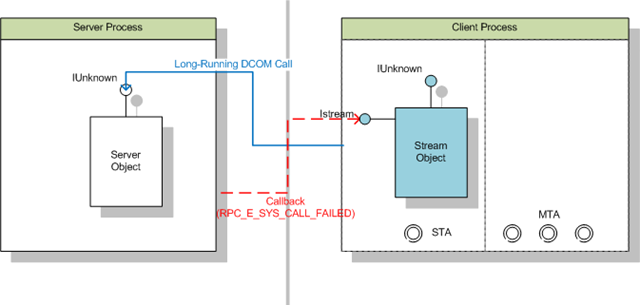
Ok, I guess it is time to go back and understand a bit more about the client.
Going a bit deeper
IStream is a generic COM interface which has many implementations shipping out-of-the-box in COM, not mentioning that it could be implemented by any customer COM objects; so which object implements the IStream interface we are handing out as an argument in the COM call to the server?
It turns out the object implementing IStream is created on the client side by a call to CreateStreamOnHGlobal(), so this is an in-memory, native (unmanaged) stream. Also, the client always succeeds in creating the IStream object and in calling methods on it, it is only when the object is passed on to the server that, sometimes, method calls fail.
The big difference between method calls to the IStream object made from the client directly and method calls made from the server is that the first are intra-apartment method calls, whereas the second are cross-apartment method calls. Cross-apartment method calls always involve marshaling, the details of which depend on the type of COM apartments (for completeness sake, intra-apartment calls may also require marshaling; this is called lightweight marshaling because it does not involve a thread switch). The client DCOM apartment is a single-threaded apartment (STA), since it needs to handle the User Interface. DCOM relies on windows messages and windows message queues in order to dispatch DCOM calls to an STA, so the theory goes that the error condition could be due to a problem in this communication mechanism. Remember: RPC_E_SYS_CALL_FAILED is a FACILITY_RPC error so it makes sense to focus on the communication layer.
Ok, enough conjecturing for now, it's time to get our hands dirty with debugging and such.
First debugging
Let's attach the debugger to the client process and run another session, waiting for the problem to occur. One of the purposes of running a process under the debugger is to check for first-chance exceptions: these exceptions are raised in the process and handled, so they would go unnoticed in a normal run. However, since the debugger is notified of every exception occurring in the debuggee, irrespective of whether the process handles it or not, attaching a debugguer is a great way to check whether some handled exceptions occur in the process.
A run under the debugger shows that there are, indeed, some first-chance exceptions occurring in the client process, but they occur at times that are seemingly unrelated to the RPC_E_SYS_CALL_FAILED failure, in that we have not come yet to the point of calling our server and handing over the IStream object. So let's take a dump of the process when one such exception occurs and have a look.
This is the exception:
0:003> .exr -1
ExceptionAddress: 7c812a5b (kernel32!RaiseException+0x00000053)
ExceptionCode: 80010100
ExceptionFlags: 00000001
NumberParameters: 0
So the exception is exactly RPC_E_SYS_CALL_FAILED. It is being raised on thread 3, which has this call stack:
0:003> k200
ChildEBP RetAddr
0f9ef4ac 77e624c2 kernel32!RaiseException+0x53
0f9ef4c4 77eb65f1 rpcrt4!RpcpRaiseException+0x24
0f9ef4d4 77eb4ead rpcrt4!NdrProxySendReceive+0x60
0f9ef8b0 77eb4e42 rpcrt4!NdrClientCall2+0x1fa
0f9ef8d0 77e4a453 rpcrt4!ObjectStublessClient+0x8b
0f9ef8e0 769b6191 rpcrt4!ObjectStubless+0xf
0f9ef968 76a1a7c6 ole32!CObjectContext::InternalContextCallback+0x122
0f9ef9b8 7a0bf7db ole32!CObjectContext::ContextCallback+0x85
0f9efa04 7a0c04b2 mscorwks!CtxEntry::EnterContextOle32BugAware+0x2b
0f9efb24 79ffb8a1 mscorwks!CtxEntry::EnterContext+0x322
0f9efb58 79ffb929 mscorwks!RCWCleanupList::ReleaseRCWListInCorrectCtx+0xc4
0f9efba8 79f8770b mscorwks!RCWCleanupList::CleanupAllWrappers+0xdb
0f9efbec 79ef32ee mscorwks!SyncBlockCache::CleanupSyncBlocks+0xec
0f9efdb0 79fb99b9 mscorwks!Thread::DoExtraWorkForFinalizer+0x40
0f9efdc0 79ef3207 mscorwks!WKS::GCHeap::FinalizerThreadWorker+0xca
0f9efdd4 79ef31a3 mscorwks!Thread::DoADCallBack+0x32a
0f9efe68 79ef30c3 mscorwks!Thread::ShouldChangeAbortToUnload+0xe3
0f9efea4 79fb9643 mscorwks!Thread::ShouldChangeAbortToUnload+0x30a
0f9efecc 79fb960d mscorwks!ManagedThreadBase_NoADTransition+0x32
0f9efedc 79fba09b mscorwks!ManagedThreadBase::FinalizerBase+0xd
0f9eff14 79f95a2e mscorwks!WKS::GCHeap::FinalizerThreadStart+0xbb
0f9effb4 7c80b683 mscorwks!Thread::intermediateThreadProc+0x49
0f9effec 00000000 kernel32!BaseThreadStart+0x37
Note from the line in blue that this is the GC Finalizer thread which is doing its cleanup. The line in red tells us that the finalizer is doing cleanup of the Runtime Callable Wrappers (RCWs), the managed wrappers for a COM object reference. Last, the line in green means that, as part of the cleanup of the RCW, the thread is making an RPC call to another thread. Since cleanup of an RCW basically means calling IUnknown::Release() on the underlying COM object, this means that the RCW that we are cleaning up has a reference to a COM object which lives in an apartment other than the one which hosts the GC finalizer.
Let's look at the threads in the process from a CLR perspective:
0:003> .loadby sos mscorwks
0:003> !threads
ThreadCount: 3
UnstartedThread: 0
BackgroundThread: 3
PendingThread: 0
DeadThread: 0
Hosted Runtime: no
PreEmptive GC Alloc Lock
ID OSID ThreadOBJ State GC Context Domain Count APT Exception
0 1 b08 000f52a8 4220 Enabled 00000000:00000000 000ee0c0 0 STA
3 2 520 001057d0 b220 Enabled 00000000:00000000 000ee0c0 0 MTA (Finalizer)
5 3 e50 000779a0 880b220 Enabled 00000000:00000000 000ee0c0 0 MTA (Threadpool Completion Port)
The output confirms that thread 3 is, indeed, running the GC Finalizer, and this thread is part of the process' Multi-Threaded Apartment (MTA). It also confirms that thread 0 in the client process is an STA, handling the user interface for the process. Indirectly, it also says that, if the COM object the finalizer is releasing lives in this same process, the apartment we are calling into has to be the STA hosted by thread 0, since there are no other apartments in this process (truth to be said, we would need to double-check this by looking at each and every thread in the process, not only to managed threads shown by the !threads extension). We can double-check this by looking at the RCW data structure. This step requires an in-depth look at the call stack. Let's unassemble the function in red in the call stack above up to the point where it calls mscorwks!RCWCleanupList::ReleaseRCWListInCorrectCtx():
0:003> u 79ffb920
mscorwks!RCWCleanupList::CleanupAllWrappers+0xd2:
79ffb920 8d45d8 lea eax,[ebp-28h]
79ffb923 50 push eax
79ffb924 e8b9bef8ff call mscorwks!RCWCleanupList::ReleaseRCWListInCorrectCtx (79f877e2)
79ffb929 8b4de0 mov ecx,dword ptr [ebp-20h]
79ffb92c 3bcb cmp ecx,ebx
79ffb92e 740c je mscorwks!RCWCleanupList::CleanupAllWrappers+0xee (79ffb93c)
79ffb930 e8e579e7ff call mscorwks!CrstBase::Enter (79e7331a)
79ffb935 c745e401000000 mov dword ptr [ebp-1Ch],1
So @ebp-28 holds the reference to the data structure that we are passing to mscorwks!RCWCleanupList::ReleaseRCWListInCorrectCtx(). Being the ebp for this frame 0f9efba8, this address is
0:003> ?0f9efba8-28
Evaluate expression: 262077312 = 0f9efb80
In turn, this points to a data structure which has, at offset 8, the pointer to the RCW:
0:003> ? poi(poi(0f9efb80)+8)
Evaluate expression: 310740888 = 12858798
0x12858798, therefore, points to our RCW and the thread for the hosting STA is at offset 0x24 of the RCW data structure:
0:003> dd 12858798+74 L1
1285880c 000f52a8
Note that this is the managed object for thread 0, as reported by the !threads command above. This confirms that the RCW points to a COM object which lives in the STA (Thread 0) of this process.
Note: the offsets which we used here are specific of version 2.0 of the CLR, they are potentially subject to change.
So what does all this mean? Well, at this point we have evidence that cross-apartment calls to the STA of this process, at some point, fail. And this happens from at least 2 different "client" apartments: the Multi-Threaded Apartment (MTA) in the same process, or an apartment in a different process.
So we can come to a more refined formulation of the problem: at some point the main STA in the client process reaches a state in which it cannot receive DCOM method calls from other apartments. Bear with me and let's try to understand why.
Looking into the kernel
We know that COM method calls are delivered to STAs through window messages. More precisely, PostThreadMessage() is used to deliver the messages, so that the message is delivered asynchronously and the caller is not blocked.
So, for the method call to fail we would need PostThreadMessage() to fail. Let's look at what the documentation has to say on PostThreadMessage():
"There is a limit of 10,000 posted messages per message queue".
If we reach that limit, PostThreadMessage() fails. Since the message queues for each thread are in the kernel address space, we need to take and analyze a kernel dump in order to verify our theory. So let's configure the system so as to take a kernel dump when our application runs into the problem, and let's analyze the dump:
0: kd> !process 0 0
PROCESS 88be5020 SessionId: 0 Cid: 0d30 Peb: 7ffdf000 ParentCid: 0f30
DirBase: 375f9000 ObjectTable: e4259840 HandleCount: 1446.
Image: Test.exe
0: kd> .process /r /p 88be5020
Implicit process is now 88be5020
0: kd> !process 88be5020
PROCESS 88be5020 SessionId: 0 Cid: 0d30 Peb: 7ffdf000 ParentCid: 0f30
DirBase: 375f9000 ObjectTable: e4259840 HandleCount: 1446.
Image: Tune.exe
VadRoot 88b37608 Vads 1565 Clone 0 Private 161460. Modified 1581. Locked 0.
DeviceMap e12178e8
Token e4f81030
ElapsedTime 01:15:53.736
UserTime 00:01:20.953
KernelTime 00:02:07.781
QuotaPoolUsage[PagedPool] 399032
QuotaPoolUsage[NonPagedPool] 79756
Working Set Sizes (now,min,max) (180369, 50, 345) (721476KB, 200KB, 1380KB)
PeakWorkingSetSize 180369
VirtualSize 1071 Mb
PeakVirtualSize 1071 Mb
PageFaultCount 478046
MemoryPriority BACKGROUND
BasePriority 8
CommitCharge 181025
DebugPort 88ab7e00
THREAD 891d6838 Cid 0d30.0d1c Teb: 7ffde000 Win32Thread: e4ed52e0 RUNNING on processor 1 <= STA
...
Again we need a bit of internal information here. The posted-messages queue is at offset 0xd0 in the Win32Thread structure, and the number of messages in the queue is at offset 8 of the posted-messages queue structure:
0: kd> dd e4ed52e0+d0+8 L1
e4ed53b8 00002710
0: kd> ?00002710
Evaluate expression: 10000 = 00002710
Note: the offsets which we used here are specific of Windows XP and they are potentially subject to change.
So here we go: the message queue for posted messages of our STA is, indeed, full. This explains why window messages, including COM method calls, cannot be delivered to this thread. If you are curious, by now you'll already have come up with the next question: "Ok, the message queue is full but why did we end up in this situation?".
Fair enough, I agree this is a legitimate question, so let's try and find an explanation.
Inspecting the Windows Message Queue
Windows Message Queues are per-thread and they work like all the other queues: someone places items (window messages) in the queue, and someone else takes them away from the queue. If the rate of arrivals of items in the queue is higher than the rate of retrieval of items from the queue, it's only a matter of time before the queue fills up.
For Windows Messages, PeekMessage() without the PM_NOREMOVE flag and GetMessage() are the functions which remove messages from the message queue. So if the queue reaches its limits it means those functions are not being called fast enough, at least compared to the rate of message arrival.
Let's first of all find out which messages are left in the queue: the messages are in a list starting 8 bytes before the number of messages
0: kd> dd e4ed52e0+d0 L1
e4ed53b0 e4ddd110
Let's dump some of them:
0: kd> dl e4ed52e0+d0 30
e4ed53b0 e4ddd110 e1487008 00002710 00000000
e4ddd110 e43f2d70 00000000 00020300 00000113
e43f2d70 e4f93670 e4ddd110 00020300 00000113
e4f93670 e12a9878 e43f2d70 00020300 00000113
e12a9878 e4eefb90 e4f93670 00020300 00000113
e4eefb90 e4c18238 e12a9878 00020300 00000113
e4c18238 e5019370 e4eefb90 00010364 0000c105
e5019370 e12f1c30 e4c18238 00000000 0000c0fe
e12f1c30 e513f860 e5019370 00010364 0000c109
e513f860 e3fa7fd0 e12f1c30 00020300 00000113
e3fa7fd0 e1640050 e513f860 00010364 00000113
e1640050 e3bd8d68 e3fa7fd0 00020300 00000113
e3bd8d68 e5291230 e1640050 00020300 00000113
e5291230 e5417c90 e3bd8d68 00020300 00000113
e5417c90 e43cc900 e5291230 0003052e 00000113
e43cc900 e11eba90 e5417c90 00020300 00000113
e11eba90 e41b2730 e43cc900 00020300 00000113
e41b2730 e513f168 e11eba90 00020300 00000113
e513f168 e41b6c70 e41b2730 00020300 00000113
e41b6c70 e4d2ab08 e513f168 00020300 00000113
e4d2ab08 e52aeb88 e41b6c70 00020300 00000113
e52aeb88 e42d2468 e4d2ab08 00020300 00000113
e42d2468 e42394a8 e52aeb88 00010364 00000113
e42394a8 e5098700 e42d2468 00020300 00000113
e5098700 e3bb7e48 e42394a8 00020300 00000113
e3bb7e48 e5832350 e5098700 00020300 00000113
e5832350 e4eadbe8 e3bb7e48 00020300 00000113
e4eadbe8 e4dad2f0 e5832350 00020300 00000113
e4dad2f0 e4fd69a0 e4eadbe8 00020300 00000113
e4fd69a0 e4eee6c0 e4dad2f0 00020300 00000113
e4eee6c0 e3b9b300 e4fd69a0 00020300 00000113
e3b9b300 e542ac10 e4eee6c0 00020300 00000113
e542ac10 e43ef8f0 e3b9b300 00020300 00000113
e43ef8f0 e42fffd0 e542ac10 00010364 00000113
e42fffd0 e1211d40 e43ef8f0 00020300 00000113
e1211d40 e436c350 e42fffd0 00020300 00000113
e436c350 e4e08378 e1211d40 00020300 00000113
e4e08378 e15b1730 e436c350 00020300 00000113
e15b1730 e1485ba0 e4e08378 00020300 00000113
e1485ba0 e583c650 e15b1730 00020300 00000113
e583c650 e41ac758 e1485ba0 00020300 00000113
e41ac758 e42417d8 e583c650 00020300 00000113
e42417d8 e12b9410 e41ac758 00020300 00000113
e12b9410 e5859630 e42417d8 00020300 00000113
e5859630 e1249278 e12b9410 00010364 00000113
e1249278 e513e3e8 e5859630 00020300 00000113
e513e3e8 e53081f0 e1249278 00020300 00000113
e53081f0 e3bfe7a0 e513e3e8 00020300 00000113
...
So we can see that, statistically speaking, the vast majority of them are messages 0x113 and a quick lookup in the WinUser.h header file (it ships with Visual Studio and with the Platform SDK) shows that this is the WM_TIMER message:
#define WM_TIMER 0x0113
Afterthought
An afterthought that occurred to me is that there is an easier way to inspect the message queue: the STA can call PeekMessage() to retrieve messages from the queue and analyze them.
This would not be easy to do in this particular case because this was customer's code but in other circumstances this would be a much easier solution than taking a kernel dump and analyzing it. Another complication in this case is that, since the STA is making long-running calls to the server, it does not have the possibility to call PeekMessage() at this time. This is not completely true, because by implementing a custom message filter (more details in the next section) the client would still have a chance to inspect messages reaching the message queue. Moreover, it would still be possible for the client to wait for the long-running COM calls to complete before calling PeekMessage().
The client could use this code to inspect which messages are in their message queue:
while (PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
// log the message somewhere
}
Note the PM_REMOVE flag: this is needed because, if we do not take the message out of the queue, we'll always be retrieving the first message at every iteration of the loop.
Back to our issue now: we still need to understand why those messages are not taken out of the message queue, don't we? So let's take our next step.
The COM Modal Loop
Let's go back to the user-mode dump and look at the call stack of the STA (Thread 0):
0:000> kb200
ChildEBP RetAddr Args to Child
00cdec60 7c94e9ab 7c8094e2 00000002 00cdec8c ntdll!KiFastSystemCallRet
00cdec64 7c8094e2 00000002 00cdec8c 00000001 ntdll!ZwWaitForMultipleObjects+0xc
00cded00 77cf95f9 00000002 00cded28 00000000 kernel32!WaitForMultipleObjectsEx+0x12c
00cded5c 769a2235 00000001 00cdeda4 000003e8 user32!RealMsgWaitForMultipleObjectsEx+0x13e
00cded84 769a235c 00cdeda4 000003e8 00cdedb4 ole32!CCliModalLoop::BlockFn+0x80
00cdedac 76a917a2 ffffffff 17162900 00cdeeac ole32!ModalLoop+0x5b
00cdedc8 76a911b6 00000000 00000000 00000000 ole32!ThreadSendReceive+0xa0
00cdede4 76a9109a 00cdeeac 17162900 00cdef08 ole32!CRpcChannelBuffer::SwitchAptAndDispatchCall+0x13d
00cdeec4 769a2409 17162900 00cdefd8 00cdefc8 ole32!CRpcChannelBuffer::SendReceive2+0xb9
00cdeee0 769a23b2 00cdefd8 00cdefc8 17162900 ole32!CCliModalLoop::SendReceive+0x1e
00cdef4c 769b65b5 17162900 00cdefd8 00cdefc8 ole32!CAptRpcChnl::SendReceive+0x6f
00cdefa0 77eb4db5 00000001 00cdefd8 00cdefc8 ole32!CCtxComChnl::SendReceive+0x91
00cdefbc 77eb4ead 1281fc7c 00cdf004 0600016e rpcrt4!NdrProxySendReceive+0x43
00cdf398 77eb4e42 1b363c00 1b363334 00cdf3d0 rpcrt4!NdrClientCall2+0x1fa
00cdf3b8 77e4a453 0000000c 00000019 00cdf49c rpcrt4!ObjectStublessClient+0x8b
00cdf3c8 79f82703 1281fc7c 00cdf3f0 7a132f50 rpcrt4!ObjectStubless+0xf
00cdf49c 0e90b88a 000f52a8 00cdf4f0 e0588eb1 mscorwks!CLRToCOMWorker+0x196
00cdf4d8 15dbedc0 101d0efc 101e2450 00000000 CLRStub[StubLinkStub]@e90b88a
... customer code here
The ole32!CCliModalLoop::BlockFn() function on the call stack means that we are in an STA and we are making an outgoing COM method call. This is expected, since we know by now that the client process is making long-running calls to the server: here we are just in the middle of one of them.
During outgoing method calls from an STA, COM cannot block: it has to enter a message loop which checks and possibly dispatches messages, similarly to what the usual message loop does in a user-interface thread. This is necessary, for example, when the called COM method makes a callback to the caller (this is, by the way, what happens when our server, upon receiving the IStream object as an argument to a method call, calls methods on it): the callback to the STA is also delivered via a windows message so there had better be someone retrieving messages from the message queue, otherwise a deadlock would occur.
On the other hand, the modal loop (as we call the message loop used by COM during outgoing method calls) cannot dispatch all the messsages, because this would cause the user interface for the calling thread to be fully responsive. In particular, this would allow a user to repeatedly click on a button, thus starting an operation multiple times before the first one completes, and other such weird and counter-intuitive things that need to be avoided if we want to maintain consistency and predictability of the application.
So what does exactly the COM modal loop do? Without going into much detail, the loop checks whether the message should be handled by first calling PeekMessage() with the PM_NOREMOVE flag; if it is determined that the message should be processed, COM calls PeekMessage() with the PM_REMOVE flag to actually take the message out of the queue and dispatch it for processing. Otherwise, the message stays in the message queue and it will be processed sometime later when, upon returning from the COM method call, the standard message loop will be used to retrieve and dispatch messages. Since context information may be needed in order to do proper message dipatching when the outgoing is in progress, the COM modal loop allows for a customization point, in the form of a COM object implementing the standard IMessageFilter interface: when a message is in the queue during an outgoing method call, the COM modal loop calls IMessageFilter::MessagePending() and allows the customization point to kick in.
Note: as an interesting aside, some libraries that deal with the user interface often provide their own implementation of IMessageFilter. For example, MFC provides its own which displays the famous "Server Busy" message box. See COleMessageFilter for more details. So, before deciding to implement your own message filter, you should also consider whether another message filter is already installed and evaluate pros and cons of replacing it.
So how does the COM modal loop deal with WM_TIMER messages? WM_TIMER messages are not extracted and dispatched by the COM modal loop, so they stay in the queue and this explains why we found so many there.
Next question, I bet, is: "Why does this happen here and not in other cases?".
Well, by analyzing the rate at which the WM_TIMER messages are sent (time member of the public MSG structure) to the queue, it can be seen that messages reach the queue every 20 milliseconds. A check in the operating system code showed that these messages are part of the IME architecture. This, by the way, also explains why, everything else being equal, this problem was experienced only on some machines: they were the machines with Japanese user interface, where IME is used.
Working to a solution
Let's recap what we have learnt so far: the client makes long-running DCOM method calls to a server from a user-interface thread, WM_TIMER messages posted to the message queue by the IME accumulate in the queue during this time and eventually fill up the thread's message queue, since the COM modal loop does not process them. When we reach this situation, method calls to the STA (either callbacks from the client or RCW cleanup from another apartment in the same process) cannot be dispatched to the STA and the caller receives the RPC_E_SYS_CALL_FAILED failure HRESULT. So the problem is caused by a combination of several factors:
A. the client apartment being an STA
B. the client making long-running calls to the server, keeping the UI non-responsive in the meantime
C. the usage of windows messages as a communication mechanism for COM STAs
D. the fact that the message queue for a thread is limited to 10000 messages
E. IME using frequent WM_TIMER messages
Let's assess which options we have.
A. is unavoidable, since this thread needs to handle the user-interface of the application. Fancy solutions involving the use of COM in the client only in the MTA should not even be considered here, since they would require a massive redesign (and testing), with no guarantee that we won't end up in a similar issue anyway (after all, we may need a communication mechanism between the COM object and the UI thread anyway).
C. cannot be changed, since it is part of the COM infrastructure.
D. can be addressed by increasing the size of message queues from the default 10000 to a higher value by means of the registry value USERPostMessageLimit, as reported in the PostThreadMessage() documentation. Though alluring at first sight, this change is not advised: it is a systemwide change, for starting, so it affects the machine as a whole. Also, which value should be used? If the messages are not processed, even a higher value may not be enough, since it all depends on how long the outgoing COM call will take to complete. Last: its change requires writing rights to the registry key, which means undue requirements for the setup of our customer's application.
E. could be addressed by gaining a better understanding of when and how the IME sends those WM_TIMER messages and to design the user interface for that thread in a way that those messages never reach the message queue for that thread. Remember: WM_TIMER messages reach the message queue of this particular thread because there is at least one window owned by this thread which is involved in IME, so chances are that we can either replace this window with another (another window class), or configure its properties and styles so that it will no longer receive the WM_TIMER messages. This solution is also unadvisable because not very robust: which messages reach the message queue is something outside the control of the thread itself, other components may send this or other types of messages; or, an implementation detail change in the future may change the number and type of messages which reach our message queue.
B. can be addressed in two ways:
B.1: register a customized IMessageFilter implementation so as to dispatch the WM_TIMER message, or to "eat" it (throw it away). This approach has disadvantages as well: in our case, the client application was written with MFC which provides its own message filter implementation. But, in general, this is the most viable and flexible option.
B.2 make the outgoing COM method calls shorter, so as to prevent the message queue to fill up in this period of time. In the case at hand, it turned out that the client was actually not making one single method call to the server, but instead malking a series of calls in a tight loop, with this pseudo-code:
while(condition)
{
hr = p->Call();
}
So the change was relatively easy: insert a message loop in-between outgoing calls, so as to empty the queue, along these lines:
while(condition)
{
hr = p->Call();
while (PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
}
Note that, since we should not block the thread if no message is available, the message loop uses PeekMessage(..., PM_REMOVE) instead of GetMessage().
This change alone effectively resolved the problem.
Note: how to implement the message loop above really depends on what you want to achieve. PeekMessage(&msg, NULL, 0, 0, PM_REMOVE) retrieves all the messages, which means the user interface for the program will be fully responsive "every now and then", that is, between method calls in the loop above. Another option is to retrieve and dispatch WM_TIMER messages only, with a call like this: PeekMessage(&msg, NULL, WM_TIMER, WM_TIMER, PM_REMOVE). The downside here is that the processing of WM_TIMER messages may generate yet other messages which, with the call above, would not be taken from the queue, so the end result may be an even quicker fill-up of the message queue. Or, we may determine that we can safely get rid of the WM_TIMER messages sent by IME during the outgoing method call, in which case we may implement a message loop where PeekMessage(&msg, NULL, WM_TIMER, WM_TIMER, PM_REMOVE) is not followed by a call to DispatchMessage() - this effectively "throws away" the WM_TIMER messages. If this seems too extreme (hey, what happens to other useful WM_TIMER messages?), we may further refine the call to PeekMessage() so as to filter with the handle of the window which is the destination of the IME WM_TIMER messages: PeekMessage(&msg, hWnd, WM_TIMER, WM_TIMER, PM_REMOVE). Also note that those same considerations apply if a customized message filter is implemented (approach B.1 above).
Last but not least, I would like to mention that I worked together with my colleague Andrea to the resolution of this case.