Calculating RPS statistics from IIS logs
Performance management is a key factor in a lot of modern web applications, and SharePoint is no exception to this. When you are planning a new SharePoint deployment having an understanding of how many requests are coming in per second so that you can plan an appropriate number of servers to handle the load. While this isn't always possible (if you are planning a new deployment you won't have any logs to base things off) but in the event of an upgrade you can gather logs from you're existing environment. IIS collects logs for incoming requests so it gives us all the data we need to report on RPS - but how do we go from multiple log files to some form of meaningful data that we can use?
Introducing Log Parser 2.2
Log Parser is a must have in the IT pro toolkit - it is a command line tool that is designed to read from log files and perform queries on them to get data from them. The great thing about this tool though is that it supports reading data from a wide range of log files, outputting to a number of formats, as well providing a common syntax to query them regardless of the source format. The querying is similar to a SQL statement (in the format of SELECT this FROM that WHERE something ORDER BY this then that) so you can write queries easily and not worry about the logs being spread across multiple files, in a specific format (like CSV, or tab separated, or others) and then spit out the results in the format you need. If you haven't had a look at Log Parser before check it out at https://technet.microsoft.com/en-us/scriptcenter/dd919274.aspx
Calculating RPS based on IIS logs
So now we have the tool for querying the logs, what are the specific steps for getting some RPS statistics from our log files? The first step is to go and grab the IIS log files and bring them all together in to one spot. The file naming is not important in this case (which is good because if you bring log files from multiple SharePoint WFE servers the file names for the logs will be the same from each server, just name them however you want) just put them all in the one directory. Next we need to craft some queries for getting meaningful data out of all of the log files - In my case where I gathered some data together to help write this post I grabbed a week worth of logs, but you can really run with as much data as you want to help get a meaningful result. To help with the querying I started with some guidance we have previously published - "Analyzing Microsoft SharePoint Products and Technologies Usage" lists how you can user Log Parser to gather a bunch of different things from log files, but has a good section on how to get some RPS numbers. You can start with this to get the info you need and leave it at that - or, you can take things a little further with PowerShell. I wont regurgitate the scripts here, the ones I'm using have come from the document directly, but with one exception. I decided to filter out a few more file extensions than it discusses (filtered out SVC example to make sure calls to the CSOM get filtered out) as well as using the user agent string to filter out any calls that have come from the search crawler so I can get a good idea of genuine end user traffic, not traffic generated by search. The where clause looks like this:
where sc-status<>401 and fext<>'gif' and fext<>'png' and fext<>'bmp' and fext<>'js' and fext<>'css' and fext<>'axd'
and fext<>'svc' and fext<>'asmx' and cs(User-Agent) not like '%MS+Search+6.0+Robot%'
Automating the queries and compilation of data
Because automation is the in thing these days, I decided to take to the commands from the document above with PowerShell to string them all together. PowerShell is more than capable of throwing the command arguments out to the Log Parser exe, so we can string the commands together there. The steps missing from the above document though are around how to extract the final statistics and put them in to Excel, so I wrote a script to put it all together. The script creates a CSV file with all of the relevant numbers that can be pasted in to an Excel document that has the charts already made up and ready to go. The report I'm generating based on the queries in the original document reports on three main statistics:
- Average requests per minute
This is a calculation of the total number of requests across the given hour, averaged out per minute (meaning this value multiplied by 60 represents the total number of requests in the hour) - Peak per minute average
This is a calculation of the average RPS across each minute in the hour, and the value shown is the highest number in this set. So this represents the average RPS over the busiest minute in the hour - Peak per second
This is a raw view of the RPS values recorded for each second, and is the busiest single second in the entire hour
Which I put in to a graph that looks a little like this:
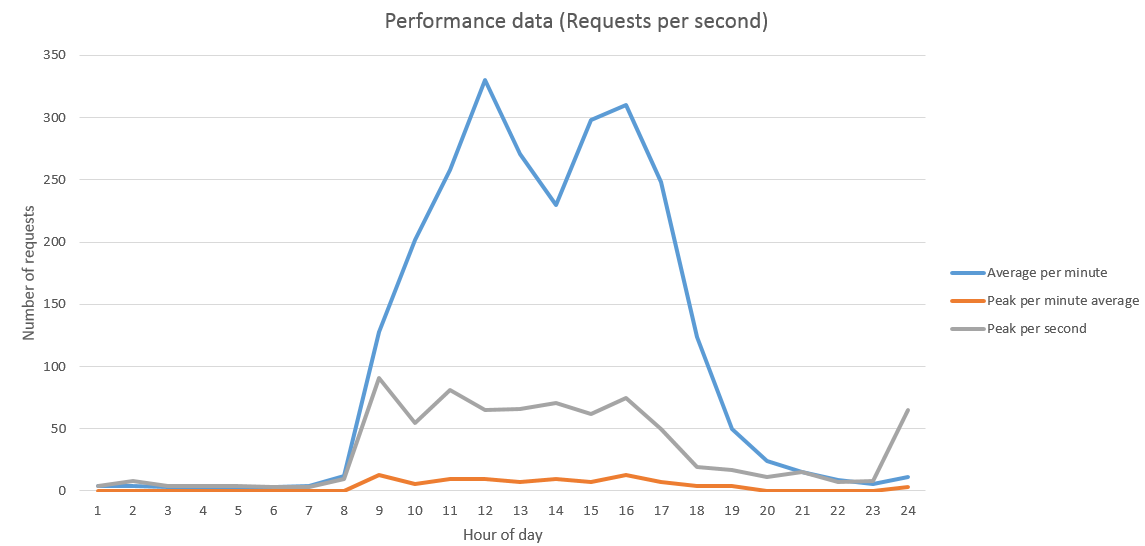
Why these statistics matter
The main statistic out of those I'm looking at here is the middle one - the peak per minute average. The reason being that it give me a good overview of what the RPS is like over a sustained period. The main RPS figure is great to get a feel for what the highest RPS you have is, but that could show a single spike as a representative figure for that whole hour. Now you might decide that you want to cater for the highest spikes of usage like this, but you might also look at these short term spikes and decide that you want to only cater for sustained periods of high usage. The peak per minute average shows the busiest minute in the hour, and what the average RPS was across that minute. This gives a bit more of a view about where there is a lot of usage that doesn't happen in as short of a time window as the single second spikes. Obviously where you have times where those higher impact seconds come up your environment will take a performance hit to catch up, but the average being much lower (like in my graph above) tells me those single second spikes are the exception rather than the rule - so aiming to the lower number might be a good trade off of cost for hardware vs. meeting usage requirements. It's all really down to your requirements and what performance goals you are looking to meet.
This isn't the be all and end all of capacity planning!
Just to be very clear - knowing statistics like RPS is just one part of a much larger and more complicated discussion around capacity planning for SharePoint, so don't take a set of data like this and let it be you're only measure for sizing a new farm. There are a couple of great articles on TechNet that discuss capacity planning in much more detail and are well worth the read if you are looking at sizing an on-prem environment.
- Capacity management and sizing overview for SharePoint Server 2013
- Capacity planning for SharePoint Server 2013
Lastly I will call out that this approach to gathering RPS statistics is not specific to SharePoint - this will work with any IIS site. You might want to tailer the WHERE clause in the initial query to suit your application specifically, but the basic premise is the same.
Download the scripts
If you're lazy and don't want to write your own PowerShell scripts and reports for this, then take a copy of mine. Just drop your log files in to the same folder as the reports here, run the PowerShell script then copy the data from the resulting results.csv file in to the results.xlsx file, then you're done! Enjoy!