Better Intranet Navigation: Statistically Improbable Phrases
On Amazon.com today, I noticed a feature that David Weinberger mentions in his book, but I don't think is yet 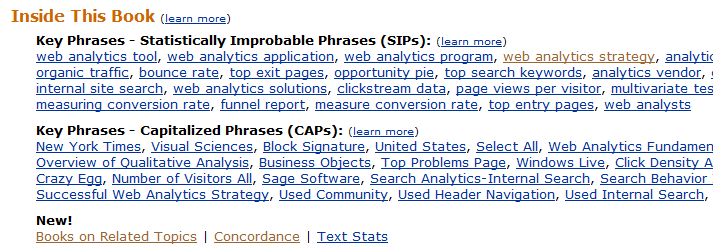 available on Amazon's UK site. Books for which they have electronic access to the text have been scanned and effectively auto-tagged. These tags then become navigational aids to allow you to find books on similar topics. Two sets of tags are listed:
available on Amazon's UK site. Books for which they have electronic access to the text have been scanned and effectively auto-tagged. These tags then become navigational aids to allow you to find books on similar topics. Two sets of tags are listed:
- Statistically Improbable Phrases are phrases that occur a large number of times in a particular book relative to all books scanned.
- Capiltalised Phrases are things such as names and places mentioned frequently in a book.
Going one step up the value chain:
- Books on Related Topics shows other related books based on their usage of similar Statistically Improbable Phrases.
- Concordance shows a tag cloud of the 100 most popular words in a book.
This got me wondering. Is there is a wide enough distribution of topics in the documents generated in a typical company to enable this sort of approach to work in the enterprise? Let's say I navigate to a document, Acme Corp Widget 3000 Marketing Plan, and alongside it I see a list of SIPs. Widget 3000 is an SIP. Clicking the link takes me to page listing other documents containing that term. Sites about the topic. Discussion lists etc. This could be a powerful way of navigating Intranet content without trying to create complex taxonomies and trying to get authors to categorize things in the right way.
I'd love to see us try something like this in Office 14. What do you think?
Technorati tags: Amazon.com, Taxonomy, Folksonomy, Tagging, Document Management