Flat File Schema creation with Tag Identifiers in the input flat file repeating in a random fashion.
Recently I faced an issue wherein I had to create a flat file schema for the input flat file having Tag Identifiers repeating several times in a random fashion.
Input file is as shown below:
TYP1~COL1~COL2~COL3TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP1~COL1~COL2~COL3TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP1~COL1~COL2~COL3TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP1~COL1~COL2~COL3TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP1~COL1~COL2~COL3TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8 |
Steps to achieve the goal:
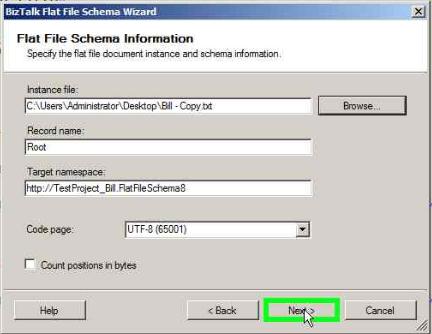
Import the flat file schema in your BizTalk project using the Flat File Schema Wizard and click Next
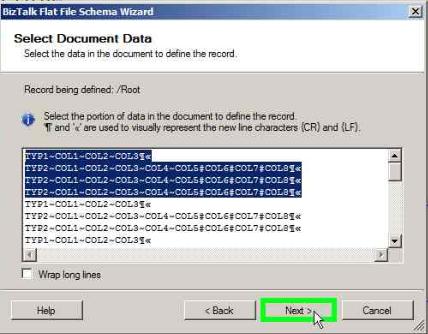
From the input file, we select the highlighted group as one record and make this as a repeating record.
TYP1~COL1~COL2~COL3
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP1~COL1~COL2~COL3
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP1~COL1~COL2~COL3
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP2~COL1~COL2~COL3~COL4~COL5#COL6#COL7#COL8
TYP1~COL1~COL2~COL3
Select the data as shown below to define the record and click Next
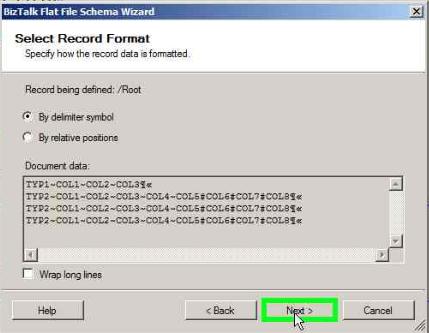
On the below window click Next
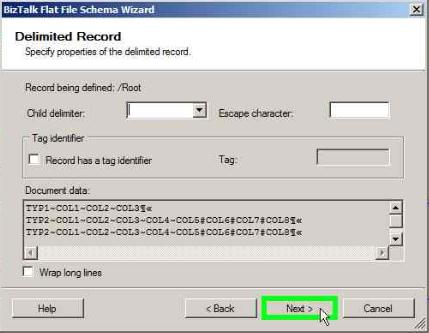
Select the Child identifier as blank and click Next
Select the Element Type as ‘Repeating record’ so that this group can be repeated N# of times and click Next
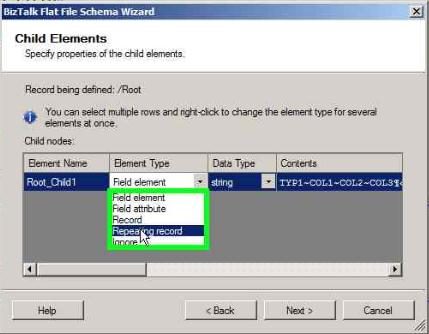
Click Next in the below window
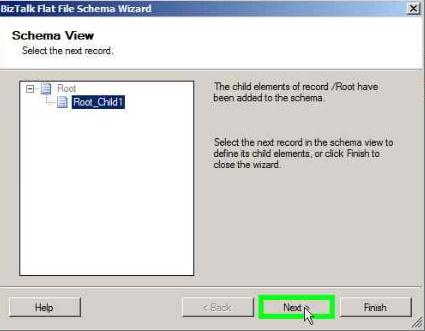
Select TYP1 and TYP2 as 2 distinct records under the above created group and click Next
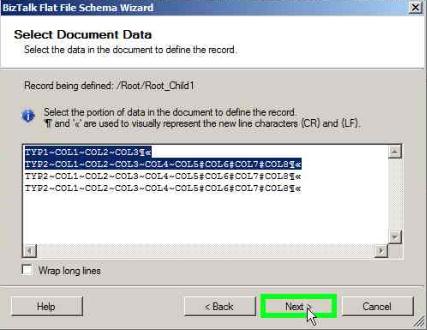
Click Next in the below window
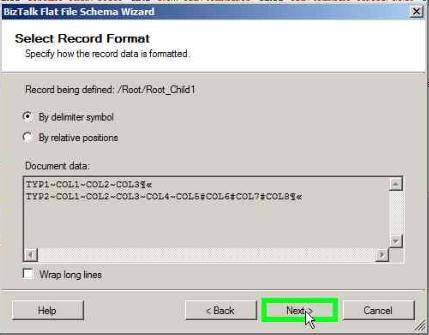
Select the Child delimiter as {CR}{LF} and click Next
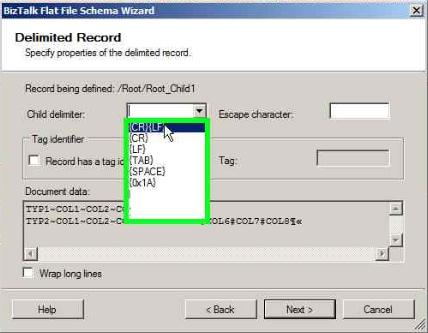
Select the Element Type as ‘Record’ for TYP1 and ‘Repeating record’ for Typ2 and click Next
Click Next in the below window
Select Typ1 record and click Next
Click Next in the below window
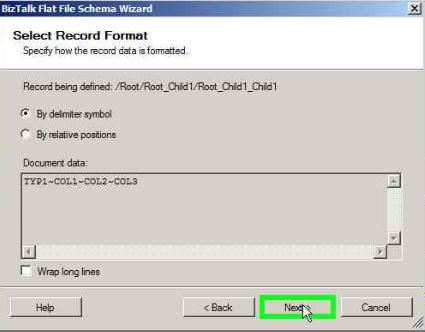
Select the Child delimiter as ~
In the Tag Identifier box, check ‘Record has a tag identifier’ and enter the Tag as ‘TYP1’
Click Next
Click Next in the below window
Click Next in the below window
Select TYP2 record and click Next
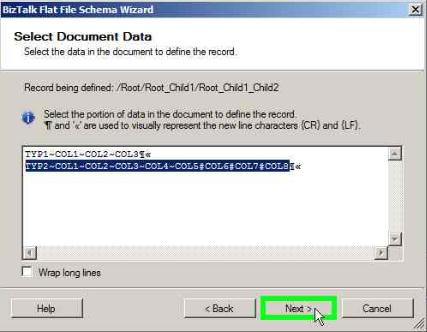
Click Next in the below window
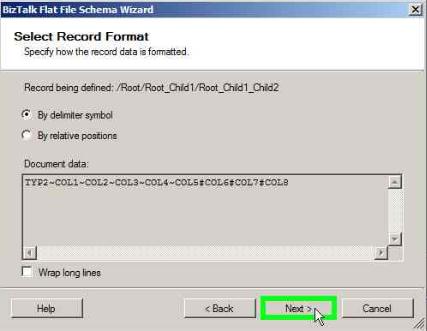
Select the Child delimiter as ~
In the Tag Identifier box, check ‘Record has a tag identifier’ and enter the Tag as ‘TYP2’
Click Next
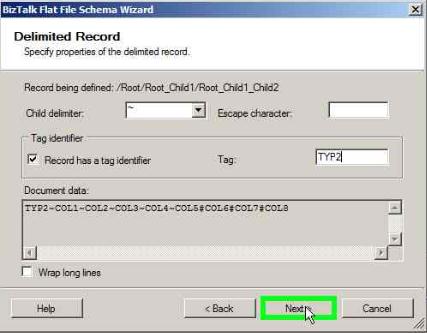
Keep the Element Type as ‘Field element’ for COL1 through CoL4
Select the Element Type as ‘Record’ for COL5 through COL8
Click Next
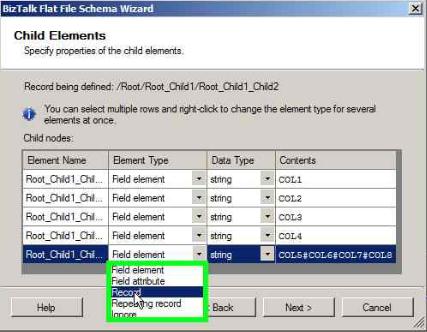
Click Next in the below window
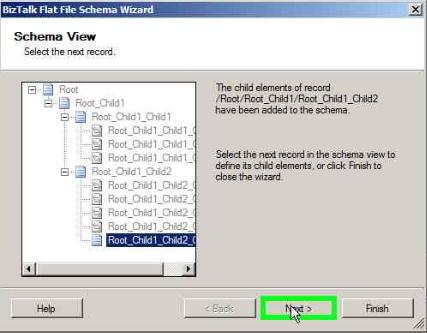
Select COL5 through COL8 and click Next in the below window
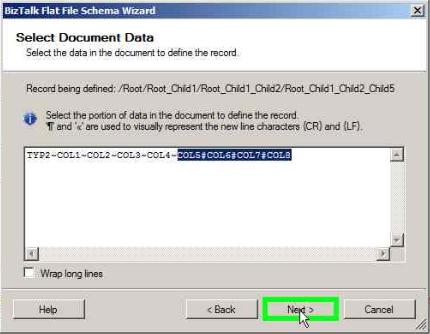
Click Next in the below window
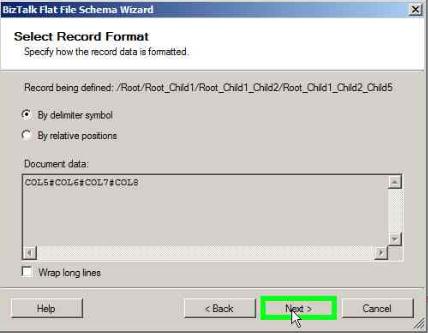
Select the Child delimiter as # and click Next
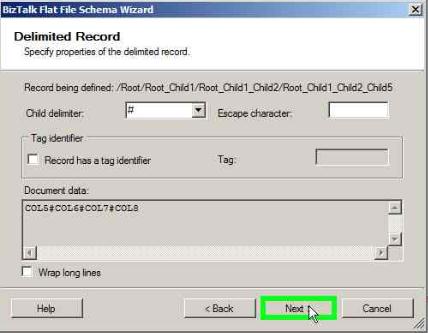
Click Next in the below window
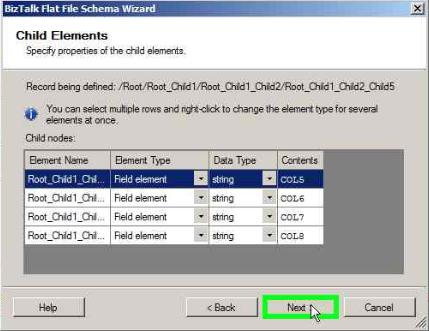
Click Finish in the below window to complete the flat file schema
Summary
To create the above mentioned flat file schema, I segregated the repeating patterns into groups that can get repeated N# of times.
If we do not go by the above mentioned approach, Tag Identifier TYP1 and TYP2 will be recognized only once by the XML.
So, completing the rest of the schema would not be possible.
Written by:
Kshitij Dattani
Reviewed by:
Jainath Ramanathan
Microsoft GTSC