HDInsight Name Node can stay in Safe mode after a Scale Down
This week we worked on an HDInsight cluster where the Name Node has gone into Safe mode and didn't leave that mode on its own. It's not very common, but I wanted to share why it happened, and how to get out of the situation, in case it prevents a headache for someone else.
HDInsight Scaling up & down is so useful
HDInsight offers elasticity by giving administrators the option to scale up and scale down the number of Worker Nodes in the clusters. This allows a cluster to be shrunk during after hours or on weekends, and grown during peak business demands.
Let's say there is some batch processing that happens one day a week or once a month, the HDInsight cluster can be scaled up a few minutes prior to that scheduled event so that there is plenty of Memory and CPU compute power. You can automate that with PowerShell cmdlet Set-AzureRmHDInsightClusterSize. Later, after the processing is done, and usage is expected to go down again, the administrator can scale down the HDInsight cluster to fewer worker nodes.
From the Azure Portal, find your HDInsight, click the Scale Cluster setting, then on the Scale blade, you just type in the number of worker nodes, and click save, and in a few minutes your HDInsight cluster will have been resized. You can go up or down.
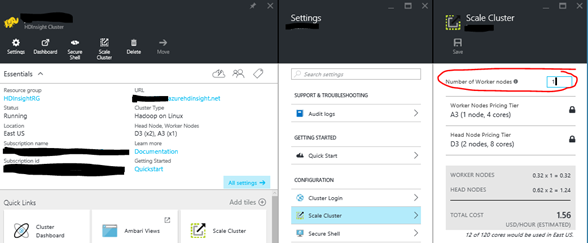
In a few occurrences, we have had HDInsight customers shrink their cluster down to the bare minimum 1 worker node as shown above. That works most of the time for them if you start at 1 worker node. But once in a while, scaling from a bunch of nodes all the way down to 1 worker node caused HDFS to get stuck in safe mode during maintenance when they are not expecting it.
Maybe when worker nodes are rebooted due to patching, or right after the scale, safe mode can occur during that maintenance timeframe.
The Short Story – If you get in Safe mode, you can manually Leave Safe Mode to ignore the issue (most of the time)
The gist is that Hive uses some scratchdir files, and by default expects 3 replicas of each block, but there is only 1 replica possible if you scale down to the minimum 1 worker node, so the files in the scratchdir are under replicated. HDFS stays in Safe mode because of that at the time when the services are restarted after the scale maintenance.
One way to get HDFS out of safe mode is to just leave safe mode (ignoring the cause assuming its benign). For example, if you know that the only reason safe mode is on is that the temporary files are under replicated (discussed in detail below) then you really don't need those files anyway because they are hive temporary scratch files, so it's reasonable to leave Safe Mode "safely" without a worry.
HDInsight on Linux:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
** note that the tick marks/apostrophes are slanted due to blog formatting. Please use plain quote/tick mark.
HDInsight on Windows:
hdfs dfsadmin -fs hdfs://headnodehost:9000 -safemode leave
After leaving safe mode, that you can remove the problematic temp files or wait for Hive to clean them up if you are optimistic.
The Details
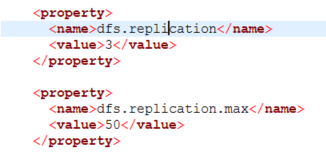
Even in HDInsight, the default HDFS configuration is set to require least 3 worker nodes to a copy of each file's blocks to be considered healthy. That is to say HDFS is configured with the dfs.replication setting of 3, so the blocks of those files are under replicated whenever there are less than 3 worker nodes online, because there are not 3 copies of each file block available.
We know from working with HortonWorks Support from time to time, that in an Hadoop in a on-premise environment where disks can get full, disks can fail, and networking errors between worker nodes can happen, it is common to see Safe mode from time to time during a catastrophie. But in the Azure cloud, most of those things are not going to happen, so unexpected Safe mode is probably not a hardware problem going on. Other folks have blogged about it
Examples of errors we saw when running Hive queries after the safe mode was turned on:
ERROR 1
H070 Unable to open Hive session. org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.RetriableException): org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode. The reported blocks 75 needs additional 12 blocks to reach the threshold 0.9900 of total blocks 87. The number of live datanodes 10 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached.
ERROR 2
H100 Unable to submit statement show databases': org.apache.thrift.transport.TTransportException: org.apache.http.conn.HttpHostConnectException: Connect to hn0-clustername.servername.internal.cloudapp.net:10001 [hn0-clustername.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
ERROR 3
H020 Could not establish connecton to hn0-hdisrv.servername.bx.internal.cloudapp.net:10001:
org.apache.thrift.transport.TTransportException: Could not create http connection to https://hn0-hdisrv.servername.bx.internal.cloudapp.net:10001/. org.apache.http.conn.HttpHostConnectException: Connect to hn0-hdisrv.servername.bx.internal.cloudapp.net:10001
[hn0-hdisrv.servername.bx.internal.cloudapp.net/10.0.0.28] failed: Connection refused: org.apache.thrift.transport.TTransportException: Could not create http connection to https://hn0-hdisrv.servername.bx.internal.cloudapp.net:10001/. org.apache.http.conn.HttpHostConnectException: Connect to hn0-hdisrv.servername.bx.internal.cloudapp.net:10001 [hn0-hdisrv.servername.bx.internal.cloudapp.net/10.0.0.28] failed: Connection refused
ERROR 4 - from the Hive logs
WARN [main]: server.HiveServer2 (HiveServer2.java:startHiveServer2(442)) - Error starting HiveServer2 on attempt 21, will retry in 60 seconds
java.lang.RuntimeException: Error applying authorization policy on hive configuration: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.RetriableException): org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/70a42b8a-9437-466e-acbe-da90b1614374. Name node is in safe mode.
The reported blocks 0 needs additional 9 blocks to reach the threshold 0.9900 of total blocks 9.
The number of live datanodes 10 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1324)
You can review the Name Node logs from folder /var/log/hadoop/hdfs/ near the time when the cluster was scaled to see when it got stuck in safe mode. Log files like Hadoop-hdfs-namenode-hn0-clustername.*
The gist of these errors and this this problems is that even in HDInsight where HDFS is rarely used, Hive does depend on temporary files in HDFS while running queries, and HDFS has gone into "Safe mode". Hive cannot run queries if it cannot write to HDFS. Those temp files in HDFS are kept in the local C: drive mounted to the individual worker node VMs and replicated amongst the worker nodes 3 replicas minumum.
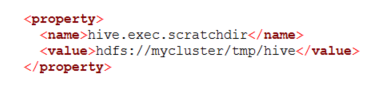
Check out how the hive.exec.scratchdir in Hive is configured in HDInsight (on Linux) "/etc/hive/conf/hive-site.xml"
How is this Safe mode issue related to Scale down?
When a scale down attempt happens, HDInsight relies upon the Ambari management interfaces to decommission the extra unwanted worker nodes, which replicates the HDFS blocks to other online worker nodes, and safely scale the cluster down. HDFS goes into a safe mode during the maintenance window, and is supposed to come out once the scaling is finished, normally.
However, when you scale to 1 node, there is no longer 3 worker nodes available to host 3 replicas of the HDFS blocks, so the file blocks that were replicated amongst 3 worker nodes or more are now only in 1 worker node, and HDFS considers those blocks "under replicated".
Recall that in Azure HDInsight, we tell you not to keep user data in the HDFS file system, and instead put your user data in Azure Blob Storage using wasb:// URI or in Azure Data Lake Store using adl:// URI paths. That azure stored data is accessible to the various Hadoop components much like HDFS without any noticeable difference, maybe even faster than HDFS, and it lives in Azure Storage within the data center, and not on the locally attached disks in the compute VMs. This model of storage in the cloud gives you flexibility to remove HDInsight clusters, and recreate them on demand later, while safely keep your data in tact and stored at a low cost.
Its typically only the Hive Scratchdir files that are remaining in HDFS, unless one of the users accidentally saved user data into hdfs:// instead of the normal Azure stores: wasb:// or adl://
You can inventory your HDFS file system by do a list from the console to see if it is the system temporary files, or some user data:
hadoop fs -ls -R hdfs://mycluster/
How to see the health and state of your HDFS file system?
You can get a report of status from each name node to show that the name nodes are in Safe Mode or not. SSH into each head node to run this kind of command.
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode get

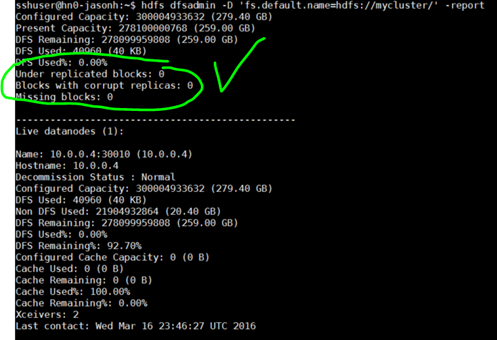
Next you can get a report that shows the details of HDFS state when all is healthy and all blocks are replicated to the expected degree.
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -report
Side bar: The reason we have to give -D switch, is that on HDInsight the default file system is Azure Blob Storage, so you have to specify the local HDFS file system in the commands like this
Let's compare a couple of example output from of a healthy hdfs file system when in and not in safe mode.
hdfs fsck -D 'fs.default.name=hdfs://mycluster/' /tmp/hive/hive
1. Healthy HDFS and no under replicated blocks:
| Connecting to namenode via https://hn0-clustername.servername.bx.internal.cloudapp.net:30070FSCK started by sshuser (auth:SIMPLE) from /10.0.0.14 for path /tmp/hive/hive at Wed Mar 16 23:49:30 UTC 2016Status: HEALTHY Total size: 0 B Total dirs: 13 Total files: 0 Total symlinks: 0 Total blocks (validated): 0 Minimally replicated blocks: 0Over-replicated blocks: 0 |
Under-replicated blocks: 0
Mis-replicated blocks: 0
Default replication factor: 3
Average block replication: 0.0
Corrupt blocks: 0
Missing replicas: 0
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Wed Mar 16 23:49:30 UTC 2016 in 5 milliseconds
2. Healthy HDFS and some under replicated blocks:
There is only one block on this file in this output, but it is under replicated, only exists on 1 worker node, and not 3 as expected by HDFS.
| Connecting to namenode via https://hn0-servername. internal.cloudapp.net:30070FSCK started by sshuser (auth:SIMPLE) from /10.0.0.14 for path /tmp/hive/hive at Thu Dec 31 19:28:03 UTC 2015./tmp/hive/hive/_tez_session_dir/62b64823-4d61-48b0-9f36-82bc60ba368f/hive-hcatalog-core.jar: Under replicated BP-2018565019-10.0.0.15-1450760688291:blk_1073741828_1004. Target Replicas is 3 but found 1 replica(s). Status: HEALTHY Total size: 253448 BTotal dirs: 31Total files: 1Total symlinks: 0Total blocks (validated): 1 (avg. block size 253448 B) |
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 2 (66.666664 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Thu Dec 31 19:28:03 UTC 2015 in 8 milliseconds
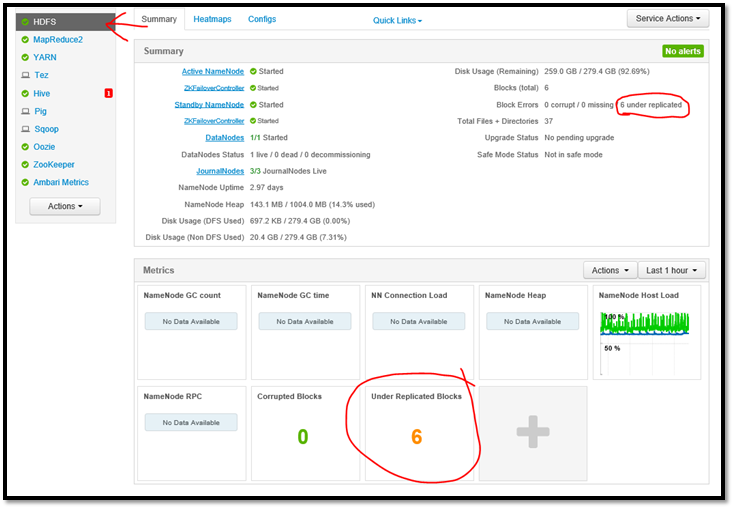
3. Ambari shows this as well.
Click the HDInsight Dashboard link from the Azure portal, and it will launch the Ambari web site. Ambari will report the block health as well, but is not as detailed as the above commands.
https://clustername.azurehdinsight.net/#/main/services/HDFS/summary
How to Prevent HDInsight from getting stuck in Safe mode due to under-replicated blocks
A little foresight can prevent HDInsight being left in Safe mode. A few options are: 
Let's go through these possibilities in more detail:
A> Queisce Hive – Stop all jobs
Stop all Hive jobs before scaling down to 1 worker node. If you know your workload is scheduled, then do your Scale Down after Hive work is done.
That will help minimize the number of scratch files in the tmp folder (if any).
B> Manually clean up behind Hive by removing scratch files
If Hive has left behind temporary files, before you scale down, then you can manually cleanup the tmp files before scaling down to avoid safe mode.
You should stop Hive services to be safe, and at a minimum make sure all queries and jobs are done.
You can list the directory hdfs://mycluster/tmp/hive/ to see if it has any files left or not.
hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive
| sshuser@hn0-servername:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hivedrwx------ - hive hdfs 0 2016-03-14 00:36 hdfs://mycluster/tmp/hive/hive/37ebc52b-d87f-4c3d-bb42-94ddf7c349dcdrwx------ - hive hdfs 0 2016-03-14 00:36 hdfs://mycluster/tmp/hive/hive/37ebc52b-d87f-4c3d-bb42-94ddf7c349dc/_tmp_space.dbdrwx------ - hive hdfs 0 2016-03-14 00:05 hdfs://mycluster/tmp/hive/hive/85122ce9-bc22-4ad2-9c34-d497492523bddrwx------ - hive hdfs 0 2016-03-14 00:05 hdfs://mycluster/tmp/hive/hive/85122ce9-bc22-4ad2-9c34-d497492523bd/_tmp_space.db |
If you know Hive is done with these files, you can remove them. You can stop Hive services to be extra safe.
Note - this can break Hive if some jobs are still running, so don't do this unless all Hive jobs are done. Be sure that Hive doesn't have any queries running by looking in the Yarn Resource Manager page before doing so.
Example command line to remove files from HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
C> Avoid going too low – Three's company, One's a lonely number
If you can't do any of the prior approaches, then you may want to avoid the problem by only scaling down to 3 worker nodes minimum. Don't go lower than that. It will cost some compute hours / money, so its nontrivial I know.
With 1 worker node, HDFS can't guarantee 3 replicas of the data will be available.
Having 3 workers node is the safest minimum for HDFS with the default replication factor.
D> Fiddle with dfs.replication settings – advanced topic
You could reduce the dfs.replication factor to 1 to prevent the under replicated scenario when using 1 worker node. This is overkill in my opinion, and an advanced option, and has consequences when other regular maintenance is done, so you need to test more thoroughly. If you keep real data (not just the Hive temporary files) in HDFS, you likely do not want to do this!! You could change this in Ambari on the HDFS configuration if you only use HDFS for temp files as recommended in HDInsight.
E> Else plan to leave Safe Mode regularly if it happens from time to time
If you can't prevent it, then if it gets in Safe mode, then tell it to leave safe mode. Once you prove the reason is just Hive temporary files are under replicated, then leave Safe mode without worry.
Linux:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Windows:
hdfs dfsadmin -fs hdfs://headnodehost:9000 -safemode leave
That's all folks. Let us know if this post helps you one day. I'm all ears.
Regards, Jason Howell (Microsoft Azure Big Data Analytics Support team)