Encoding the Hive query file in Azure HDInsight
Today at Microsoft we were using Azure Data Factory to run Hive Activities in Azure HDInsight on a schedule. Things were working fine for a while, but then we got an error that was hard to understand. I've simplified the scenario to illustrate the key points. The key is that Hive did not like the Byte Order Mark (first 3 bytes) in the hive .hql file, and failed with an error. Be careful which text editor and text encoding you choose when saving your Hive Query Language (HQL) command into a text file.
We are using Azure Data Factory (Feb 2016) with a linked service to Microsoft Azure HDInsight Hadoop on Linux (version 3.2.1000.0) which is the distribution from Hortonworks Data Platform version 2.2.7.1-36 and includes Hive 0.14.0.
Error message:
Hive script failed with exit code '64'. See 'wasb://adfjobs@mycontainer.blob.core.windows.net/HiveQueryJobs/92994500-5dc2-4ba3-adb8-4fac51c4d959/05_02_2016_05_49_34_516/Status/stderr' for more details.
To drill into that stderror logging, In the Data Factory activity blade, we see the error text, and see the log files below. We click on the stderr file and read it in the log blade.
Stderr says:
WARNING: Use "yarn jar" to launch YARN applications.
Logging initialized using configuration in jar:file:/mnt/resource/hadoop/yarn/local/filecache/11/hive.tar.gz/hive/lib/hive-common-1.2.1.2.3.3.1-1.jar!/hive-log4j.properties
FAILED: ParseException line 1:0 character '' not supported here
That's strange, because the Hive query file looks fine to the naked eye.
If you use a binary editor though you can see these two text files are not the same.
I have Visual Studio handy, and it can show the hex representation of these files.
File > Open > File…
Next to the open button there is a drop down – choose "Open with…"
Choose Binary Editor. 
Notice that file2.hql shown below has 3 extra bytes in the beginning. This is called a byte-order mark (BOM).

The Standards Controversy
There is some controversy about whether UTF-8 text files should have a byte order mark or not.
The standards folks say don't use it in most cases, but also don't remove it if you already have a BOM. We software developers sometimes forget that and are inconsistent -Microsoft Windows vs. Linux vs. Apache Hive
Citing the crowdsourced Wikipedia information here for neutrality:
https://en.wikipedia.org/wiki/Byte_order_mark
UTF-8 byte order mark is EF BB BF in hex.
The Unicode Standard permits the BOM in UTF-8,[2] but does not require or recommend its use.
The standard also does not recommend removing a BOM when it is there, so that round-tripping between encodings does not lose information, and so that code that relies on it continues to work.
In Linux distributions since around 2004 the convention is to generate UTF-8 files without a BOM.
Microsoft compilers[10] and interpreters, and many pieces of software on Microsoft Windows such as Notepad treat the BOM as a required magic number rather than use heuristics. These tools add a BOM when saving text as UTF-8, and interpret as UTF-8 on reading only when the BOM is present.
The Litmus Test
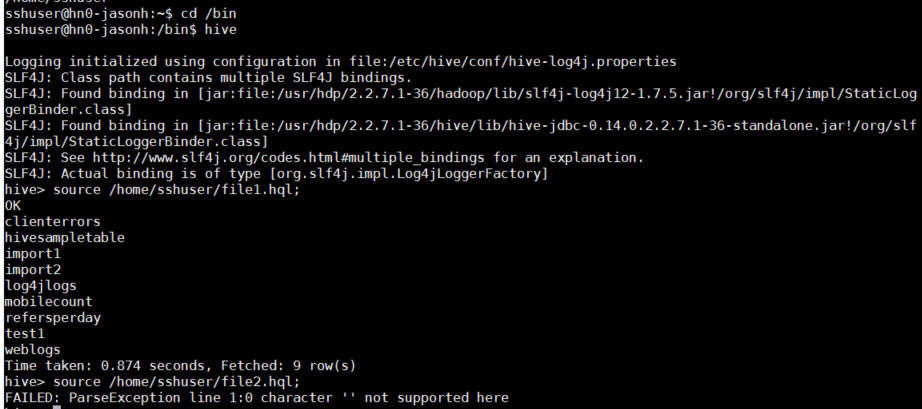
So let's try the two .hql text files in Hive console directly outside of Azure Data Factory to see if they work in Hive alone. I am using SSH to connect to my Linux head node in HDInsight. I have uploaded the two files using SFTP (easy to do in MobaXTerm if you like that 3rd party tool – I can't endorse any specific tool, but seems nice). The source command here is running the query file from within the hive app.
1. First I launch Hive on my SSH session.
Cd /bin
Hive
2. Then I run the script from the first file. It works well and returns a list of my Hive tables from my metastore.
source /home/sshuser/file1.hql;
OK
3. Then I run the script from the second file. It fails with a parsing error
source /home/sshuser/file2.hql;
FAILED: ParseException line 1:0 character '' not supported here
The lesson learned
So the lesson learned is that Hive doesn't like the .hql text files when they are encoded in UTF-8 with a Byte-order mark up front in the hex/binary.
UTF-8 is the encoding of choice, but the byte-order mark is not desired.
Action Required!
Check your favorite text editor to see if it is marking the BOM or not.
1. Windows Notepad seems to encode UTF-8 files to include a Byte Order Mark, so avoid that one.

2. Visual Studio 2013 / 2015 gives you the option to save "With Encoding" on the drop down beside the Save button, then you can pick which Encoding you want.
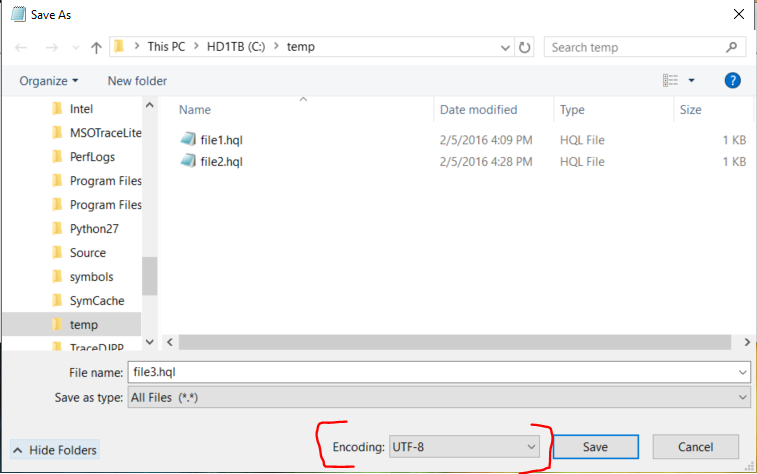
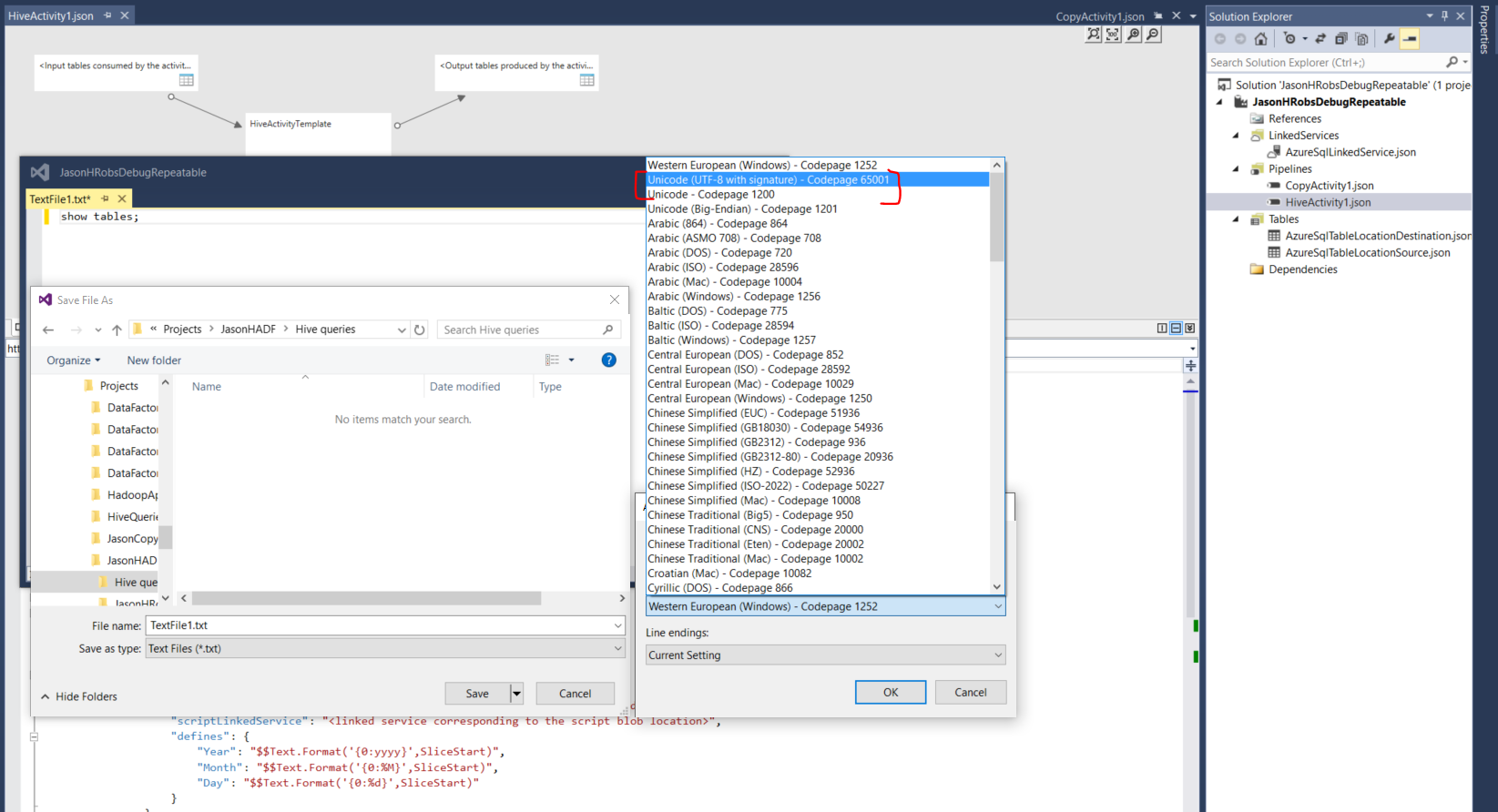
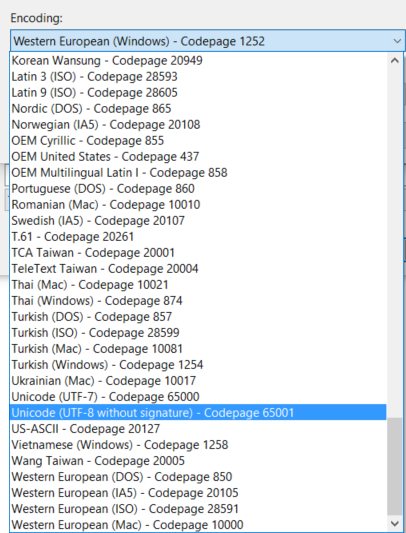
First trial - I picked Unicode (UTF-8 with signature) – Codepage 65001. That "signature" means it adds a BOM, which is undesirable for Hive to interpret.
Second trial – I picked Unicode (UTF-8 without signature) - Codepage 65001. Looks better now. That's the one without the BOM in the first three bytes, so Hive should be OK to read this one.

3. Linux's common Vi text editor

The hex representation does not have a BOM, so we are good to use this with Hive.

Hive can run this one OK

4. Nano – another easy text editor on Linux
Looks good as well, no BOM

Hive can run this one OK too.

To be continued... There are many more text editors, so please let me know if you have trouble with encoding using another text editor when saving Hive queries to text.