How to configure Hortonworks HDP to access Azure Windows Storage
Recently I was asked how to configure a Hortonworks HDP 2.3 cluster to access Azure Windows Storage. In this post we will go through the steps to accomplish this.
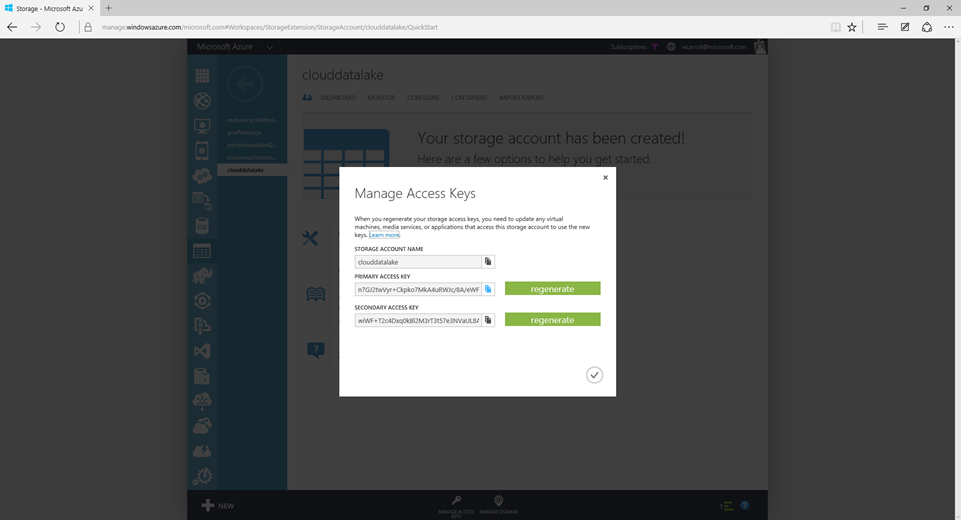
The first step is to create an Azure Storage account from the Azure portal. My storage account is named clouddatalake. I choose the "local redundant" replication option while creating the storage account. Under the "Manage Access Keys" button at the bottom of the screen you can copy and or regenerate your access keys. You will need the account name and access key to configure our HDP cluster in later steps.
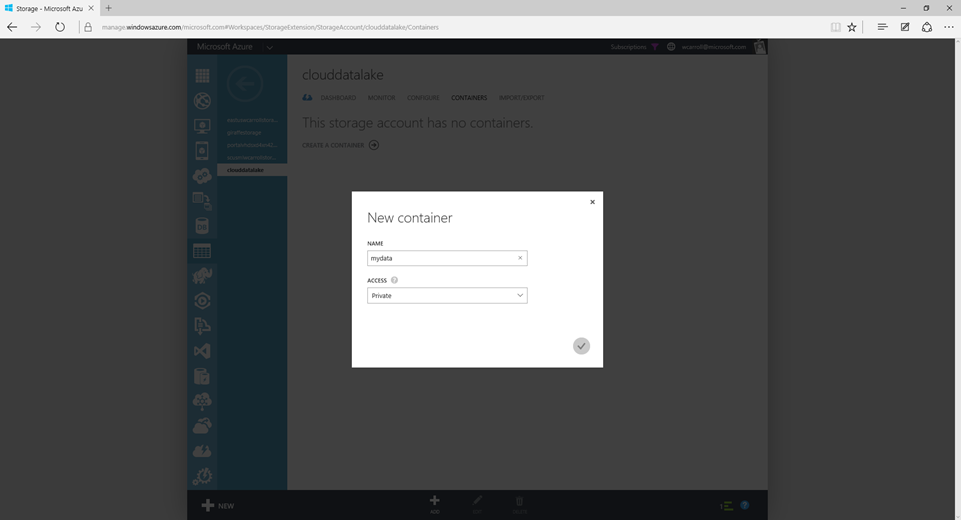
Next I created a private container named mydata. That's all you need to do on the Azure side. Everything else is done on your Hortonworks HDP cluster.
Hortonworks HDP 2.3 comes with the azure-storage-2.2.0.jar which is located at C:\hdp\hadoop-2.7.1.2.3.0.0-2557\share\hadoop\common\lib. You need to add a property to your core-site.xml file which is located at C:\hdp\hadoop-2.7.1.2.3.0.0-2557\etc\hadoop. You need to modify the name and value to match your Azure storage account. Replace the clouddatalake below with your storage account name and the value with your access key which you can copy from the Azure portal under the "Manage Access Keys" button. Save the core-site.xml file.
<property>
<name>fs.azure.account.key.clouddatalake.blob.core.windows.net</name>
<value>n7GJ2twVyr+Ckpko7MkA4uRWJc/8A/eWFztZvUVPorF4ZiLNeAe0IabudXpuxfFtj9czt8GUFpyKgP4XRc6b7g==</value>
</property>
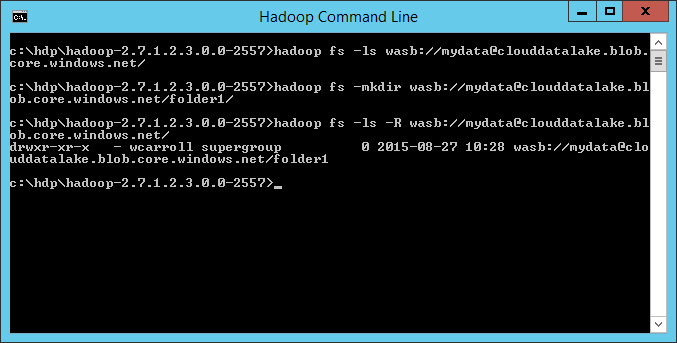
Next restart your hdp services. This causes the namenode and resourcemanager services to read the core-site.xml file and populate its memory with the configuration change. The syntax for Azure Storage is wasb://<container>@<storageaccountname>.blob.core.windows.net/<foldername>/<filename>. Next you can use the Hadoop fs –ls wasb://<mydata@clouddatalake.blob.core.windows.net/> to list the files in the container. I also used the –mkdir option to create a folder1 in the mydata container of the clouddatalake storage account.
Now you can use Hadoop distcp <src> <dst> to copy files between your local HDFS and Azure Storage. The command I used was Hadoop distcp /prod/forex/ wasb://mydata@clouddatalake.blob.core.windows.net/folder1/. This runs a mapreduce job to copy the files.
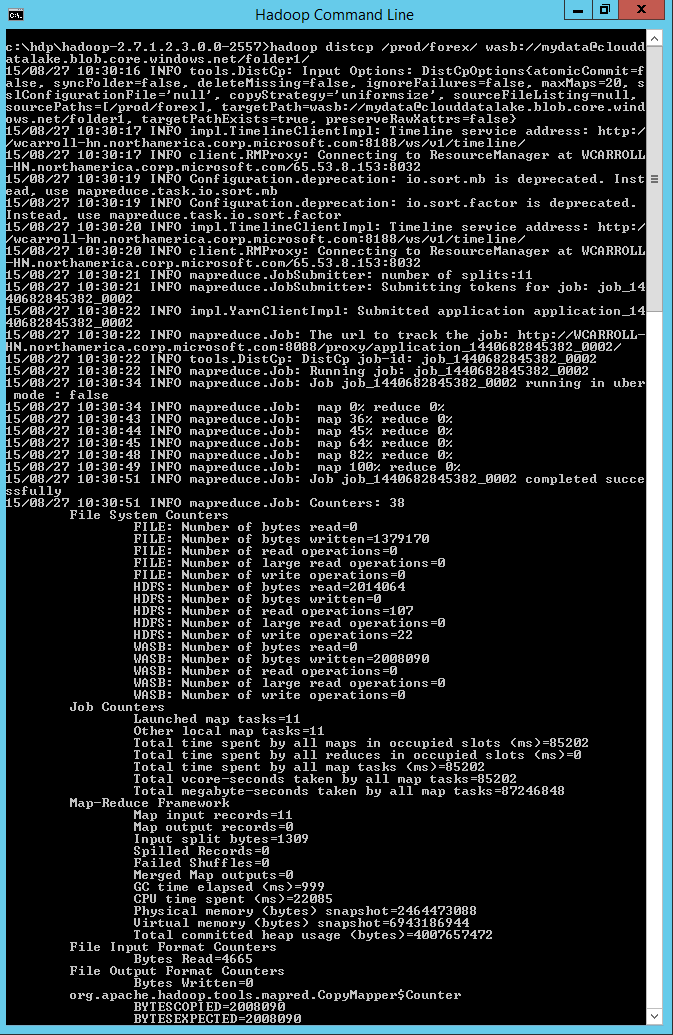
You can see that the Hadoop job completed successfully from the Hadoop Yarn Status UI.
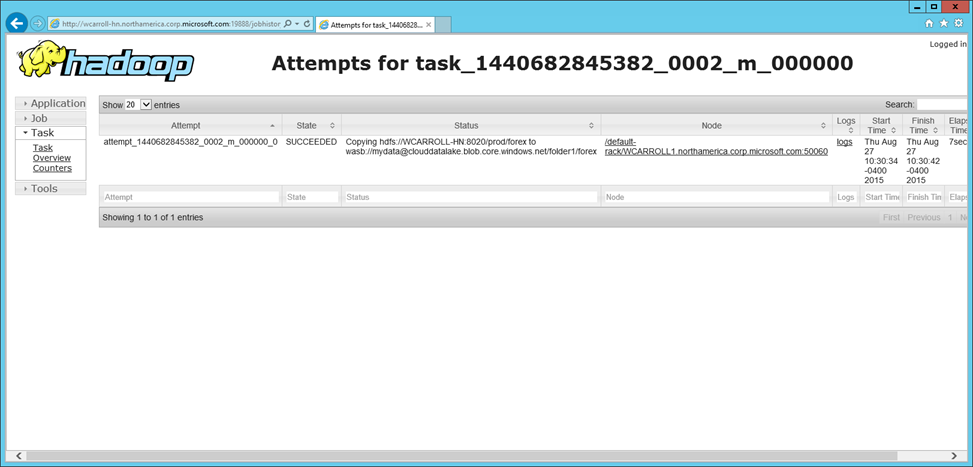
And there are the files in Azure Storage!
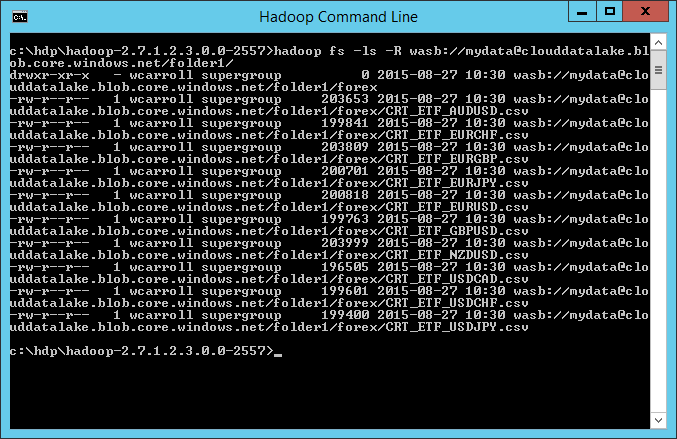
Using Azure storage to create a data lake is a great feature! This easy configuration change easily allows your Hortonworks HDP cluster to access Azure storage.
Bill