How to manually compile and create your own jar file to execute on HDInsight
Hi, my name is Bill Carroll and I am a member of the Microsoft HDInsight support team. At the heart of Hadoop is the MapReduce paradigm. Knowing how to compile your java code and create your own jar file is a useful skill, especially for those coming from the C++ or .Net programming world. So our goal for the post is to manually compile and create our own jar file and execute it on HDInsight
The data set I have chosen is electronically traded funds data from 2007 to 2014. From Wikipedia, An ETF is an investment fund traded on stock exchanges, much like stocks. An ETF holds assets such as stocks, commodities, or bonds, and trades close to its net asset value over the course of the trading day. Most ETFs track an index, such as a stock index or bond index. The data is common to other investments, so a much larger population could be used. Think of analyzing data from every stock, mutual fund, ETF on exchanges all over the world at 5 second intervals. That's big data!
Data
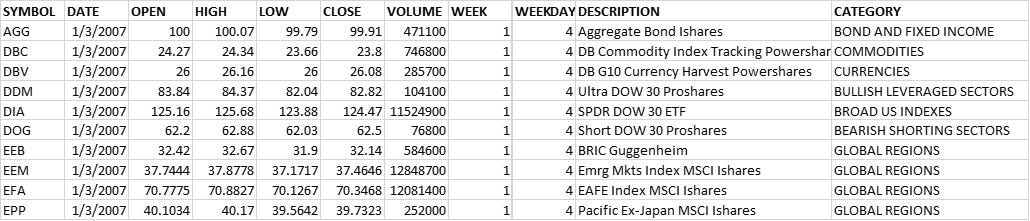
Let's familiarize ourselves with the data. You can download the ETF-WATCHLIST.CSV file and java code from here. The data is an ANSI comma separated file with 11 columns. You can see it has both text and numeric data and is currently sorted by DATE and SYMBOL.
| SYMBOL | TEXT | ETF exchange symbol |
| DATE | TEXT | Date in the file is YYYY-MM-DD format. |
| OPEN | NUMERIC | Opening price |
| HIGH | NUMERIC | High price for the day |
| LOW | NUMERIC | Low price for the day |
| CLOSE | NUMERIC | Closing price for the day |
| VOLUME | NUMERIC | Number of shares traded for the day |
| WEEK | NUMERIC | The week of the year |
| WEEKDAY | NUMERIC | The day of the week (Sunday = 1) |
| DESCRIPTION | TEXT | Description of the ETF |
| CATEGORY | TEXT | Category of the ETF |
Code
Let's get to today's goal, to manually compile and create our own jar file and execute it on HDInsight. I am going to assume you have reviewed the classic Apache WordCount Example already. Below is the java code. The purpose of the code is to write out the ETF symbol + description along with a count of trade days.
package BigDataSupport;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class ETFRun1
{
public static class Map extends Mapper<Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
String[] stringArray = value.toString().split(",");
String line = value.toString().trim();
String symbol = stringArray[0].toString().trim();
String date = stringArray[1].toString().trim();
double open = Double.parseDouble(stringArray[2].toString().trim());
double high = Double.parseDouble(stringArray[3].toString().trim());
double low = Double.parseDouble(stringArray[4].toString().trim());
double close = Double.parseDouble(stringArray[5].toString().trim());
int volume = Integer.parseInt(stringArray[6].toString().trim());
int week = Integer.parseInt(stringArray[7].toString().trim());
int weekday = Integer.parseInt(stringArray[8].toString().trim());
String description = stringArray[9].toString().trim();
String category = stringArray[10].toString().trim();
context.write(new Text(symbol + " " + description), new Text(line));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
{
Integer ctr = 0;
Iterator<Text> it = values.iterator();
while(it.hasNext())
{
ctr++;
it.next();
}
context.write(key, new Text(ctr.toString()));
}
}
public static void main(String[] args) throws Exception
{
JobConf conf = new JobConf();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Usage: <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "ETFRun1");
job.setJarByClass(ETFRun1.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
There are some things I want to point out in the code above. We are using our own customer package name called BigDataSupport. This will become important when we create our jar file and execute our jar file on HDInsight. We have imported several java and apache Hadoop files. On HDInsight java is installed at c:\apps\dist\java\bin. We will pick up the import java file from this location when we compile. We also need two apache Hadoop jar files to compile successfully. These are located on HDInsight at C:\apps\dist\hadoop-1.2.0.1.3.2.0-05\ hadoop-core-1.2.0.1.3.2.0-05.jar and C:\apps\dist\hadoop-1.2.0.1.3.2.0-05\lib\ commons-cli-1.2.jar. In the c:\apps\dist\java\bin folder are the javac.exe, and jar.exe files. We will use the javac.exe to compile our java code and the jar.exe to create a jar file. Because we intend to compile and build multiple times, let's create a simple build-ETFRun.cmd file that we can reuse.
You are probably aware that the MapReduce paradigm works on key-value pairs. Our map function takes three parameters. A key of Object data type, value as Text data type, and context as a Context data type. For the mapper, the key data will be automatically generated by MapReduce and is the offset into the file. The value data will be an individual line of our ETF-WATCHLIST.CSV file. The context will be an object that we use to write or emit out a key-value pair to the next phase of MapReduce. We use the context.write function to write out the key-value pair. The data type that the context writes out must match what is defined in our Mapper signature. Notice that Mapper is defined as Mapper<Object, TEXT, TEXT, TEXT>. The first two parameters, Object and TEXT, are what comes in and the third and fourth parameters, TEXT and TEXT, are what come out. This means that our context.write function must write out a key as data type TEXT, and a value as data type TEXT. If we want to write out other data types in the context.write function we must change our Mapper function signature to match it.
In the map function we are parsing the data by comma and placing each column into the array for Strings. Then we assign each column to a variable for the 11 columns. We then write out our key-value pair in the context.write statement. Because we have to write out a TEXT data type we create a new TEXT and pass it our symbol + description as the key. For the value we also create a new TEXT and just pass the entire line. For our first line in the ETF-WATCHLIST.CSV, the map function should be writing out:
- Key = AGG Aggregate Bond Ishares
- Value = AGG,2007-01-03,100.0000,100.0700,99.7900,99.9100,471100,1,4,Aggregate Bond Ishares,BOND AND FIXED INCOME
The Reduce function has a signature of <TEXT, TEXT, TEXT, TEXT>. The first two parameters, TEXT and TEXT, are the key and value from the map function. They must also match what your context.write function statement writes out from the map function. The third and fourth parameters, TEXT and TEXT are the data types that the reduce function will write out. Our reduce function takes three parameters, a key of TEXT data type, values as an Iterable of TEXT data type, and context as a Context data type. In between the map and reduce phases, MapReduce has a "sort\shuffle" phase. This automatically sorts our key and places each value for that key in the Iterable Object. In our reduce function we then can iterate over the values for each key. We should have one execution of our reduce function for each unique key that the map function writes out. The key-value pair coming into the reduce function should look like:
- Key = AGG Aggregate Bond Ishares
- Iterable[0] = AGG,2007-01-03,100.0000,100.0700,99.7900,99.9100,471100,1,4,Aggregate Bond Ishares,BOND AND FIXED INCOME
- Iterable[1] = AGG,2007-01-04,100.0300,100.1900,99.9400,100.1200,1745500,1,5,Aggregate Bond Ishares,BOND AND FIXED INCOME
- Iterable[2] = AGG,2007-01-05,100.0000,100.0900,99.9000,100.0500,318200,1,6,Aggregate Bond Ishares,BOND AND FIXED INCOME
In the reduce function, very similar to the WordCount example, we use the iterator to count up the number of trade days for each ETF. We then use the context.write function to write out the key and the counter. The ctr variable is of type Integer and we need to convert it to string in order to create a new TEXT object for the context.write function. The key-value pair coming out of the reduce function should look like:
- Key = AGG Aggregate Bond Ishares
- Value = 1765
The main function creates an instance of the JobConf Object and sets properties. Note that the setting properties for our map and reduce class names, the data types of our Output key and values. These need to match our Map and Reduce function signatures.
Compile and Jar
Now that we have our ETFRun1.java file created lets compile it and create a jar file. Enable RDP on your HDInsight cluster through the portal and remote desktop to your headnode. Temporarily create a c:\MyFiles folder and copy the ETFRun1.java file into the folder as well our data file, ETF-WATCHLIST.CSV. Next create a build-ETFRun.cmd file with the following commands.
build-ETFRUN.CMD
cls
REM ===My Build File===
cd c:\MyFiles
del c:\MyFiles\ETFRun1.jar
rd /s /q c:\MyFiles\MyJavaClasses
rd /s /q c:\MyFiles\BigDataSupport
mkdir c:\MyFiles\MyJavaClasses
mkdir c:\MyFiles\MyJavaClasses\BigDataSupport
c:\apps\dist\java\bin\javac.exe -classpath "C:\apps\dist\hadoop-1.2.0.1.3.2.0-05\hadoop-core-1.2.0.1.3.2.0-05.jar;C:\apps\dist\hadoop-1.2.0.1.3.2.0-05\lib\commons-cli-1.2.jar" -d c:\MyFiles ETFRun1.java
copy c:\MyFiles\BigDataSupport\*.class c:\MyFiles\MyJavaClasses\BigDataSupport\
c:\apps\dist\java\bin\jar.exe -cvf C:\MyFiles\ETFRun1.jar -C MyJavaClasses/ .
c:\apps\dist\java\bin\jar.exe -tfv C:\MyFiles\ETFRun1.jar
rem hadoop jar c:\MyFiles\ETFRun1.jar BigDataSupport.ETFRun1 /example/data/ETF-WATCHLIST.CSV /example/etf
The javac.exe takes a –classpath parameters which contains the path to the two apache Hadoop jar files we need in order to compile. A –d parameter which specifies the folder to place the .class files in. Javac.exe also takes the name of your .java file to compile into .class file. If you have multiple .java files just add them separated by a space. Because our code uses a package name the .class files are actually placed in folders under the c:\MyFiles folder to match the package name. This turns out to be c:\MyFiles\BigDataSupport. Below you can see the .class files generated by javac.exe
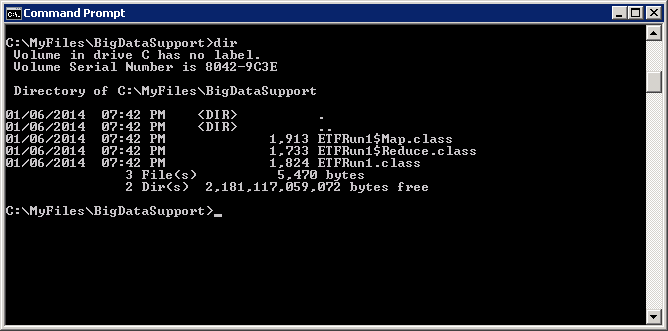
Next we use jar.exe to create a jar file that Hadoop can run. We have created a c:\MyFiles\MyJavaClass\BigDataSupport folder and copied our .class files from c:\MyFiles\BigDataSupport into c:\MyFiles\MyJavaClass\BigDataSupport before creating the jar file. If we don't get the paths correct when we execute the jar file it will raise a ClassNotFoundException. Take another quick look at the build-ETFRUN.cmd file.
Note: If you have third party jar files that you want to include in your jar file you can modify the build script to create a MyJavaClass\Lib folder and copy your third party jar into the lib folder before you jar it.
Below is an example of the ClassNotFoundException if you don't get the path correct.
Exception in thread "main" java.lang.ClassNotFoundException: BigDataSupport.ETFRun1
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:423)
at java.lang.ClassLoader.loadClass(ClassLoader.java:356)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at org.apache.hadoop.util.RunJar.main(RunJar.java:153)
The jar.exe takes –cvf parameters. Parameters c, creates a new archive, v generates verbose output and f specifies the archive file name. Jar.exe also takes the –C MyJavaClass /. parameter to tell it where the .class files are to jar up. You can also use the –tvf to display the contents of a jar file after it is created.
Execute the build-ETFRUN.CMD to compile and create your ETFRun1.jar file. If it compiles and builds successfully your output should look like:
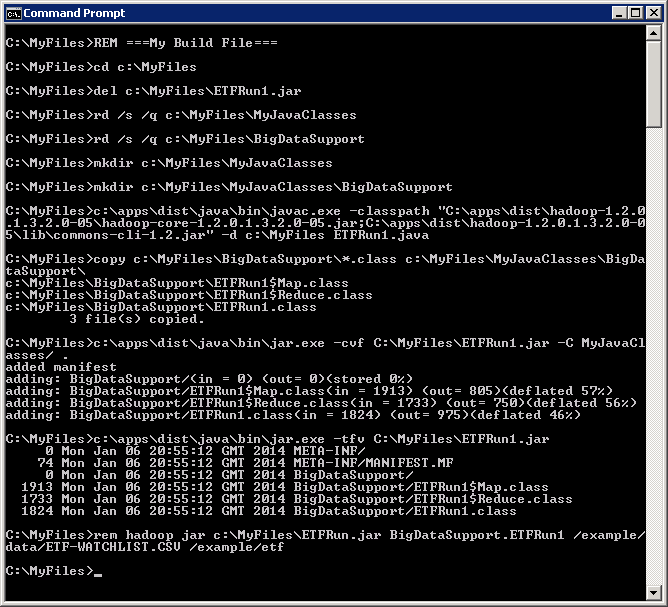
If you have syntax errors in your code they will be displayed in the output. Review them and modify your code and try again. Notice that the BigDataSupport path in the list of .class files in the jar file.
Open a Hadoop command prompt and copy your data file or the ETF-WATCHLIST.CSV to HDFS. You can also copy the ETFRun1.jar file into HDFS, but for now I will leave it in c:\MyFiles folder.
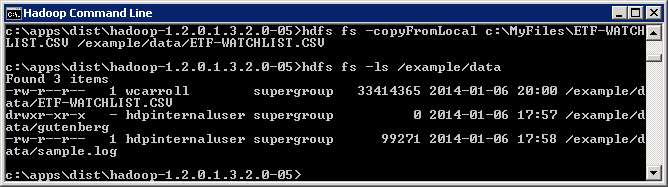
To run your jar file, execute hadoop jar c:\MyFiles\ETFRun.jar BigDataSupport.ETFRun1 /example/data/ETF-WATCHLIST.CSV /example/etf. Hadoop jar takes four parameters. The path to your jar file. The path to the class to start executing from within your jar file. Data input and data output paths. You should see output similar to below when the job runs.
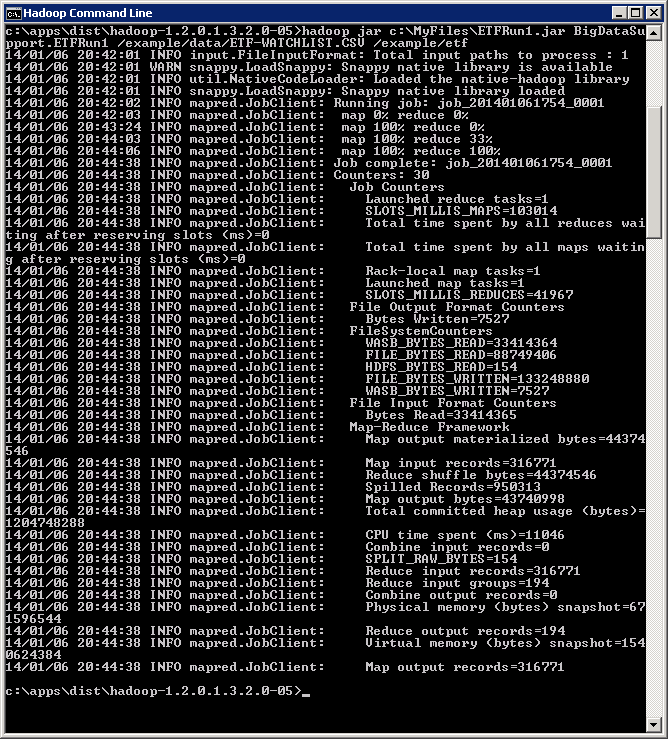
You should see the job output in the /example/etf/part-r-00000 file. You can copy it to your local drive to examine.
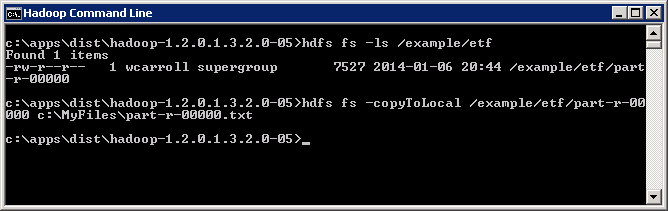
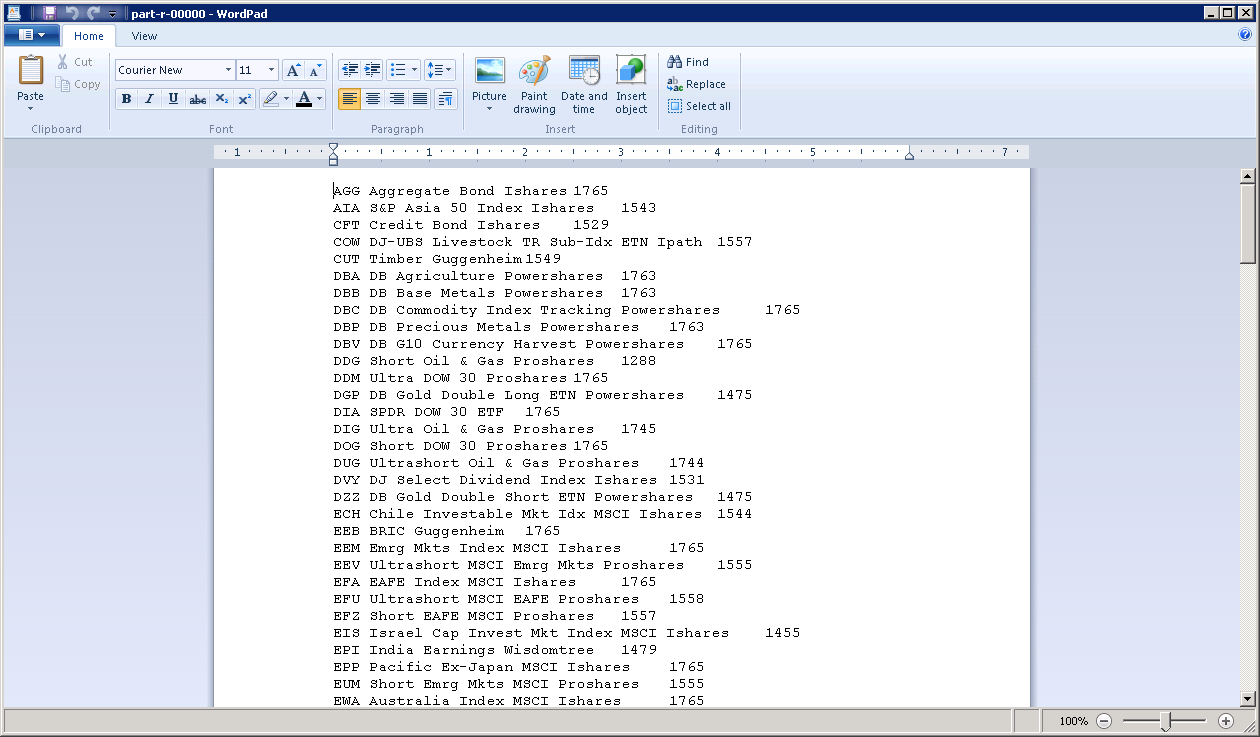
If we open up our part-r-00000 file in wordpad.exe we see that we have the symbol + description (key) and the count of trade days (value). We have 194 unique ETF's. In the output of the job look at the "Reduce input groups". We see the ETF symbol along with its description. Each ETF has a different number of trade days. They range from 688 to 1765 trade days. Some ETF's started trading after January of 2007.
Conclusion
This should give us a good foundation to use our own data, our own java code and be able to successfully compile it, create a jar file and execute it as a MapReduce job on HDInsight.