Le Machine Learning avec Spark grâce à HDInsight – 3ième partie

La toute nouvelle sortie de la bibliothèque Microsoft Machine Learning pour Apache Spark (MMLSpark) est l'occasion de revenir sur ce billet de Machine Learning avec HDInsight à travers un regard neuf.
Rappelez-vous, dans les deux premières parties du billet ici et ici, nous avions déployé un cluster Apache Spark sur Azure HDInsight pour y mettre en place un modèle d'apprentissage automatique (Machine Learning) pour un problème de classement (classification).
J'en profite pour remercier très sincèrement Anaig Maréchal actuellement en stage au sein de l'équipe pour cette contribution ;-)
Microsoft Machine Learning pour Apache Spark
Microsoft Machine Learning Spark est un projet en Open Source disponible sur la forge communautaire GitHub. Cette bibliothèque Python fournit des outils de Machine Learning et Deep Learning qui permettent aux scientifiques des données (Data Scientists) de gagner en performance sur Spark.
En effet, si Spark est un allié de poids pour créer des modèles de Machine Learning évolutifs (scalable), nous avons vu dans les deux premières parties que l'API SparkML présente néanmoins quelques contraintes dues à son assez bas niveau.
Ainsi, nous avions notamment évoqué la nécessité i) de créer des pipelines pour éviter les redondances dans le code, ii) de transformer les variables catégoriques sous forme numérique ou encore iii) de rassembler les prédicteurs du modèle dans un vecteur.
Toutes ces opérations peuvent être simplifiées avec MMLSpark, qui encapsule des requêtes APIs Scala, ce qui permet aux Data Scientists de se concentrer sur l'aspect Machine Learning de leur projet tout en gardant les performances natives de la JVM.
MMLSpark propose donc des APIs simplifiées qui prennent directement tout type de données en paramètre, sous un format indépendant de l'algorithme. Celles-ci permettent de plus d'intégrer et utiliser très facilement les algorithmes de Deep Learning du kit en Open Source Microsoft Cognitive Toolkit (anciennement CNTK) disponible sur la forge GitHub, avec des modèles pré-entraînés ou non, ainsi que d'accélérer le traitement en utilisant un GPU.
Utiliser MMLSpark
En local
Pour installer MMLSpark en local, utilisez Docker depuis un terminal grâce à la commande :
docker run -it -p 8888:8888 -e ACCEPT_EULA=yes microsoft/mmlspark
Pour retrouver un notebook Jupyter d'exemple ou créer un nouveau notebook, on peut alors se rendre à l'adresse : https://localhost:8888/tree?
Avec HDInsight
Il est possible d'installer MMLSpark sur un cluster Linux HDInsight déjà existant. Pour cela, il faut exécuter un script sur le nœud maître (head) et les nœuds esclaves (worker).
Dans la section « Aperçu » (Overview) de la page du cluster, rendez-vous dans l'onglet « Script actions » de la configuration. Cliquez alors sur « Submit new » et renseignez :
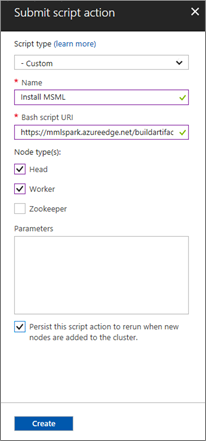
Script type : - Custom
Name : Install MSML
Bash script URI : https://mmlspark.azureedge.net/buildartifacts/0.5/install-mmlspark.sh
Node type(s) : Head & Worker
Persist this script action to rerun when new nodes are added to the cluster
Une fois le script lancé, le cluster met une dizaine de minutes à se configurer.
La bibliothèque peut ensuite être installée de façon classique sous forme de package Spark :
import mmlspark
Notez que MMLSpark nécessite Scala 2.11+, Spark 2.1+ et Python 2.7 ou Python 3.5+.
Une expérience simplifiée
Reprenons notre exemple d'apprentissage automatique sur les données de revenus d'adultes américains.
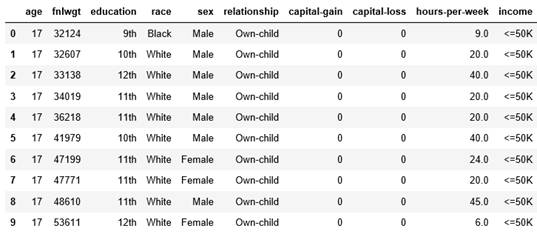
Nous avons toujours des données nettoyées sous la forme d'un data frame de 32537 lignes et de 9 prédicteurs sélectionnés. « Income » est la variable à prédire, qui indique si un individu gagne plus ou moins que $50K.
Les données ont été séparées en un ensemble d'apprentissage nommé « train » et un ensemble de test « test », représentant respectivement 70% et 30% du total.

Comme lors de l'exemple précédent, on choisit d'appliquer le modèle des arbres de décision. Les données sont automatiquement converties dans le format convenant à l'algorithme : les variables catégoriques sont encodées et les prédicteurs sont rassemblés dans un vecteur.

Le modèle a finalement une performance similaire à celle obtenue en utilisant SparkML seul, avec une précision d'environ 85%. Le nombre de lignes de code a cependant été significativement réduit.
En guise de conclusion
MMLSpark permet donc d'utiliser la puissance de calcul de Spark en Machine Learning avec des APIs plus haut niveau que SparkML. De nombreux algorithmes de Machine Learning et Deep Learning sont ainsi disponibles de façon simplifiée, incluant notamment Microsoft Cognitive Toolkit (CNTK) et OpenCV.
Pour vous lancer, n'hésitez pas à consulter la documentation complète !