Introduction à Azure Data Lake - 1ère partie
Azure Data Lake est un nouveau service Azure qui permet de stocker et d’analyser tous types de données, quelles que soient leur taille, leur forme ou leur vitesse. Le but de ce service est d’éliminer la complexité liée à la réception et au stockage de l’ensemble de vos données tout en accélérant la mise en route du traitement par lots, du streaming ou des analyses interactives.
Azure Data Lake s’intègre complètement aux autres services Azure et permet donc la création de solutions sécurisées (Intégration avec Azure Active Directory) et avancées autour de la gestion du cycle de vie de la donnée (Intégration avec SQL Data Warehouse, Azure Machine Learning,…).
Azure Data Lake est un service distribué basé sur Apache YARN qui bénéficie d’une mise à l’échelle dynamique, et bénéficie d’un nouveau langage de programmation qu’est le U-SQL, combinant les avantages du Transact SQL avec la puissance du code C#.
Avec Franck Mercier, un beau jeune homme plein de talents, dans le cadre de la préparation de notre session aux Journées SQL Server (JSS2015), nous avons pas mal creusé le sujet. Nous partageons via une série d’articles nos investigations et espérons que cette série d’articles vous sera bénéfique.
Ce premier article est un article d’introduction à Azure Data Lake. On vous présente comment créer un ADLS et un ADLA puis on réalisera une première opération, toute simple, en U-SQL.
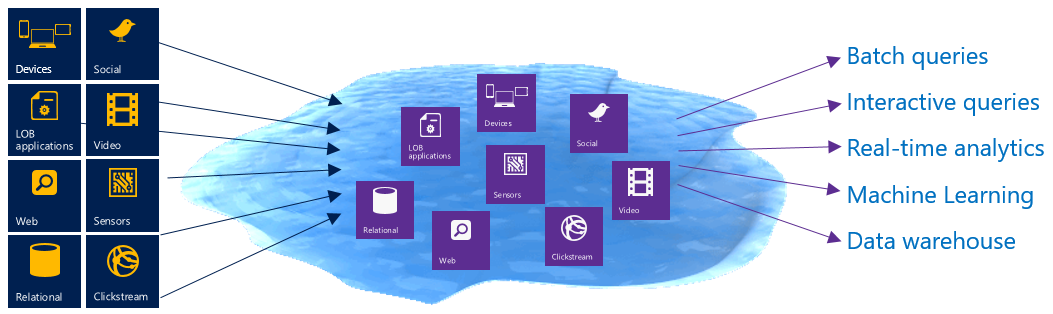
Présentation d’Azure Data Lake
Azure Data Lake est un nouveau service Azure, qui en réalité est composé de 2 services :
- Azure Data Lake Store (ADLS)
- Azure Data Lake Analytics (ADLA)
Ci-dessous un schéma illustrant Azure Data Lake :
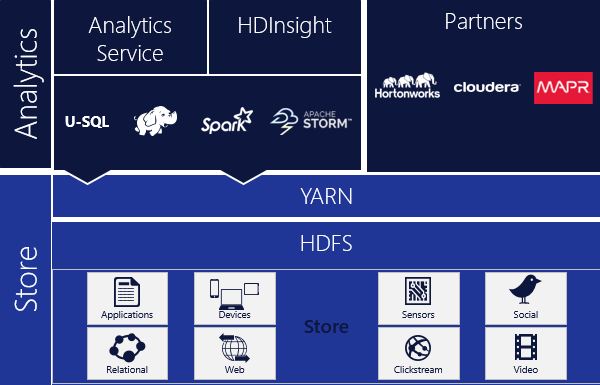
Azure Data Lake Store
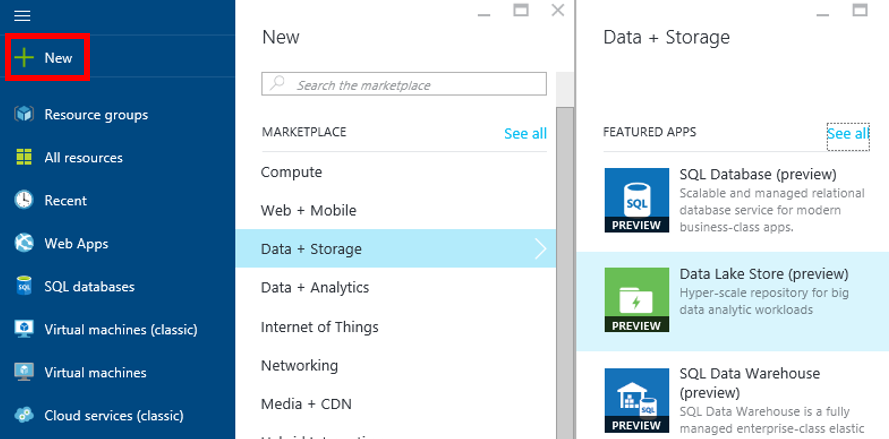
Pour créer un stockage Azure Data Lake, connectez vous au portal Azure : https://portal.azure.com.
Cliquez sur « New », « Data + Storage » puis sur « Data Lake Store ».
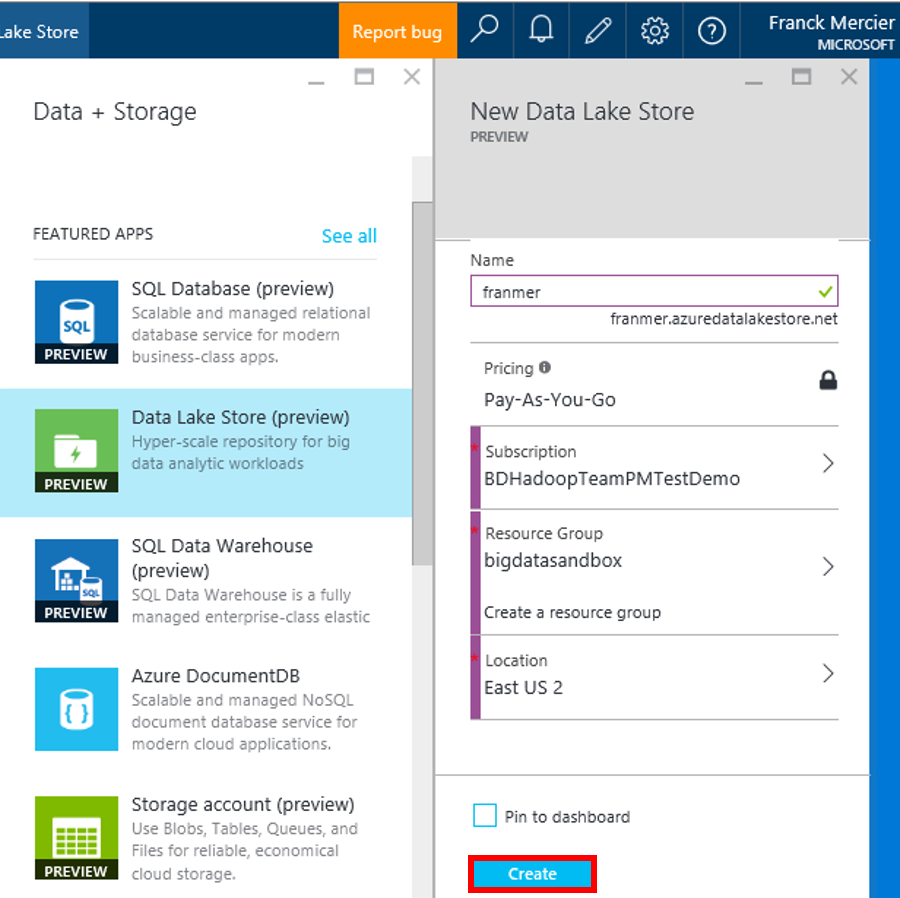
Renseignez les différents champs puis cliquez sur le bouton « Create ».
Une fois Azure Data Lake Store créé, il est disponible en passant par « Browse », puis « Data Lake Store ». Cliquez sur « Data Lake Store »
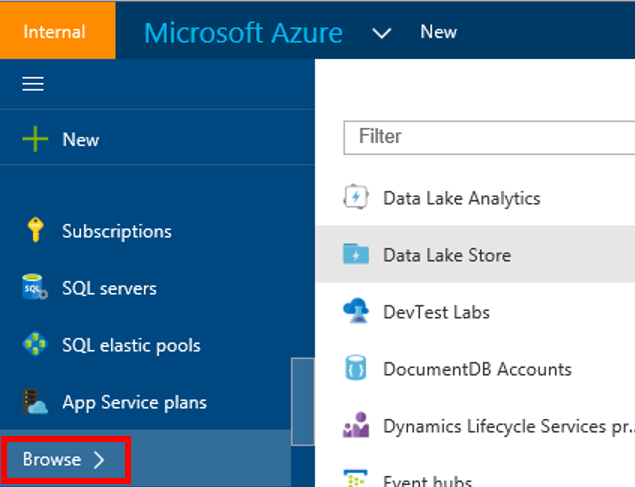
Voici ci-dessous la fenêtre de management d’Azure Data Lake Store. Pour explorer les données disponibles dans le store, cliquez sur le bouton « Data Explorer ».
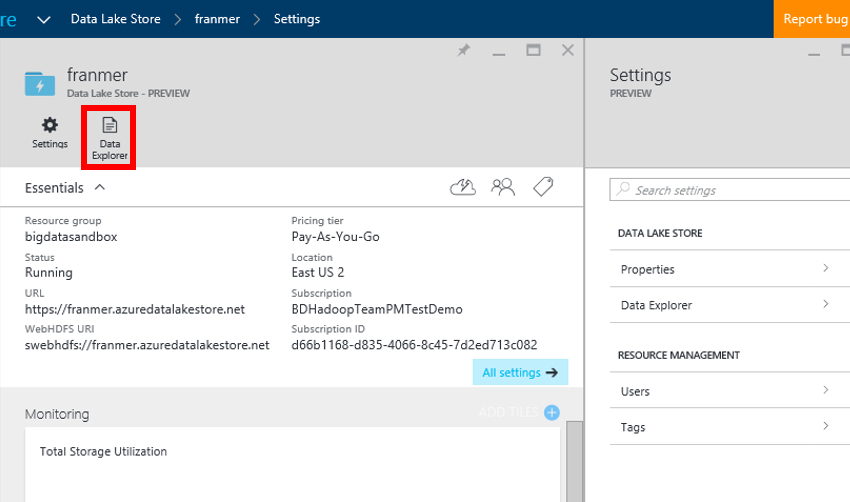
C’est dans cette fenêtre que sous aurez la possibilité de visualiser les éléments présents dans votre stockage, mais aussi d’y rajouter des éléments et gérer les accès. Nous allons utiliser cette interface pour créer un nouveau dossier. Cliquez sur « New Folder ».
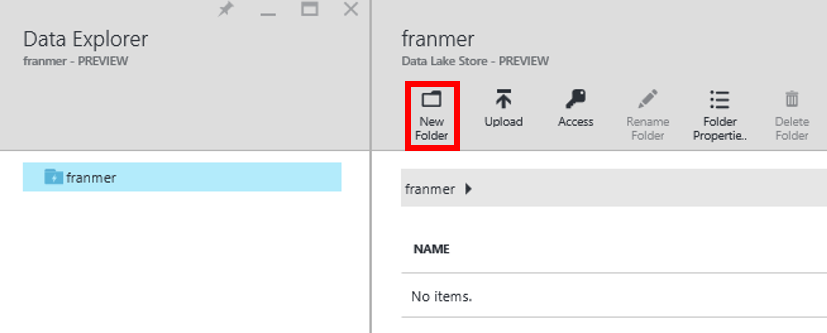
Entrez un nom pour le dossier que vous souhaitez créer. Cliquez sur « Ok ».
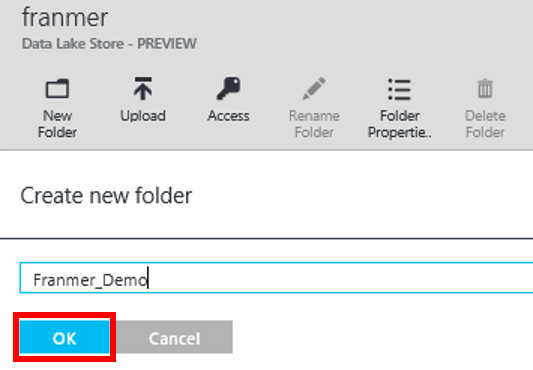
Voici ci-dessous la fenêtre que vous devez obtenir :
Nous allons maintenant télécharger un fichier dans ce dossier. Ouvrez le dossier précédemment créé, puis rajoutez un fichier en cliquant sur le bouton « Upload ». Dans le panneau de droite, cliquez sur l’icône dossier pour télécharger vos fichiers.
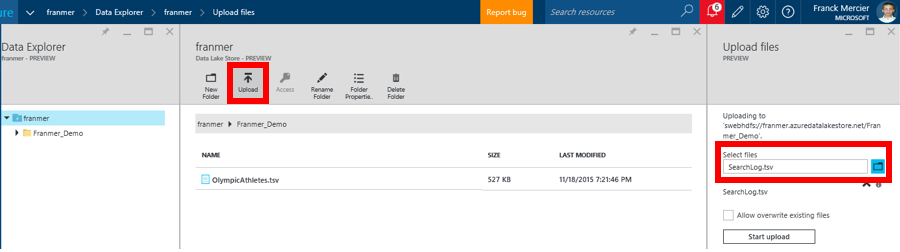
Vous devez donc obtenir une fenêtre similaire à celle présentée ci-dessous. Vous pouvez cliquer sur le fichier pour l’explorer :
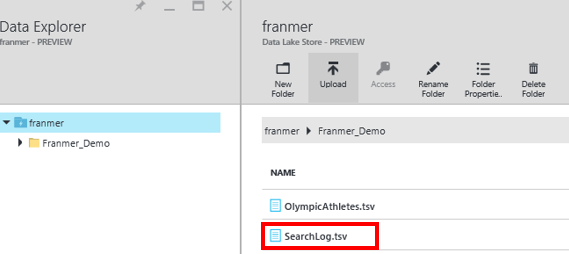
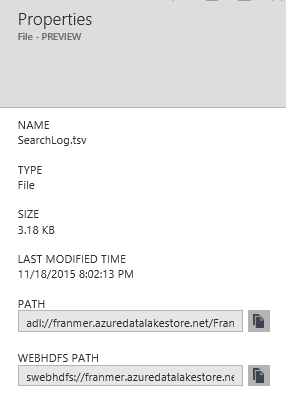
Exploration du fichier. Cliquez sur le bouton « Properties » pour récupérer le chemin du fichier. Ce chemin sera nécessaire lors du traitement avec Azure Data Lake Analytics.
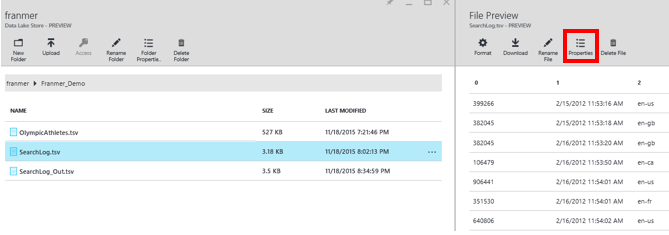 Voici les propriétés du fichier ainsi que ses chemins d’accès :
Voici les propriétés du fichier ainsi que ses chemins d’accès :
Mais que notre stockage est configuré, nous allons créer la partie « Analytics ».
Azure Data Lake Analytics
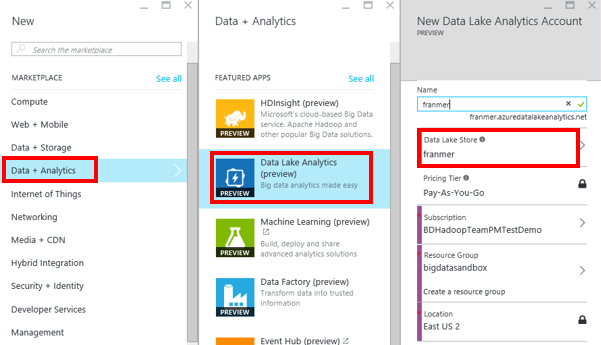
Pour créer un Azure Data Lake Analytics, cliquez sur « Data + Analytics » puis « Data Lake Analytics ». Renseignez les informations nécessaire en prenant soin de bien spécifié l’Azure Data Lake Store que nous avons précédemment créé.
Cliquez sur le bouton « Create ».
Une fois l’Azure Data Lake Analytics créé, vous pouvez y accéder en cliquant sur « Browse », puis « Data Lake Analytics ».
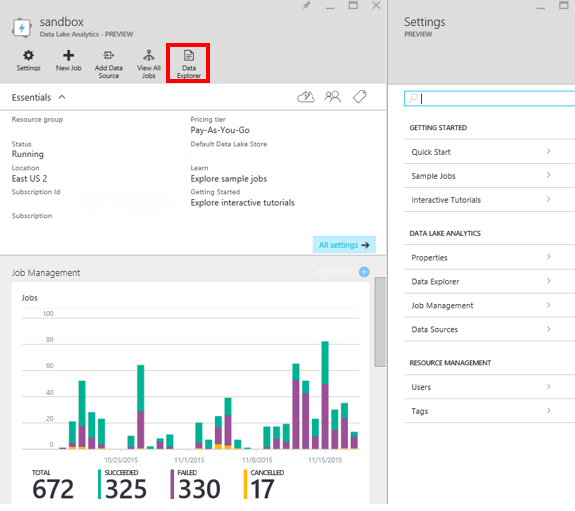
Ci-dessous, un exemple de panneau de gestion d’un Data Lake Analytics, qui vous permettra de réaliser les courantes de Data Lake. Par exemple, en cliquant sur le bouton « Data Explorer », vous pourrez naviguer dans les stockages qui lui sont associés.
Première opération
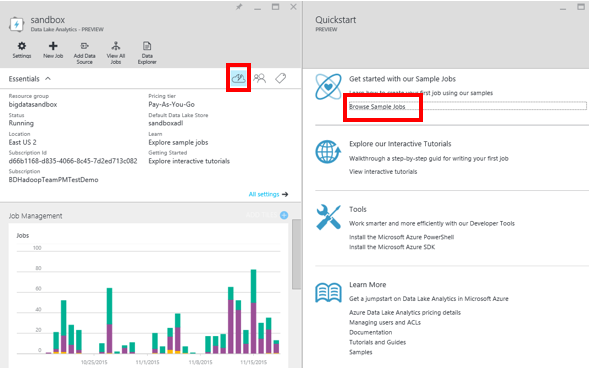
Nous allons réaliser notre première opération avec Data Lake Analytics. Dans le panneau de gestion, cliquez sur le petit nuage, puis sur « Browse Sample Jobs ».
Une fenêtre avec un exemple de script apparaît. Ce script va extraire les données d’un fichier pour les copier dans un autre dossier. On va réaliser une action de copie, tout simplement.
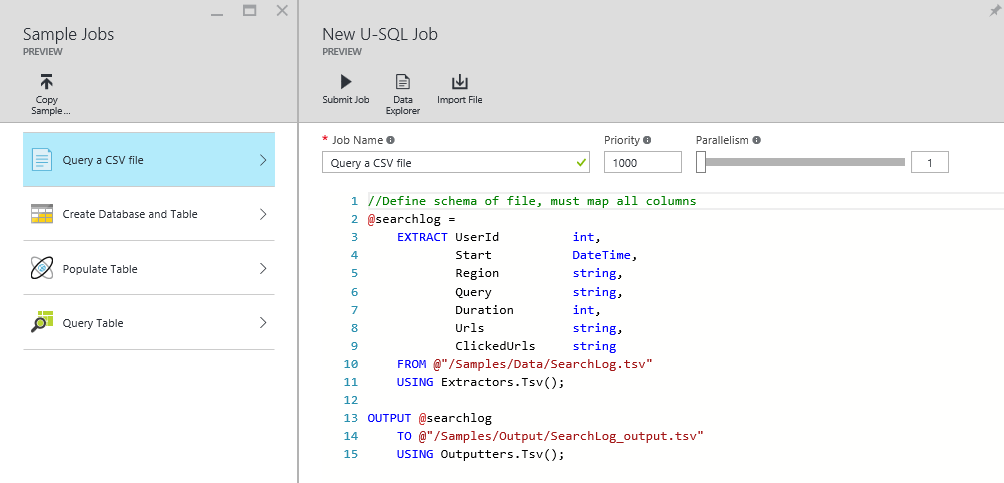
Il faut faire attention de bien modifier les chemins, qui sont relatifs à notre stockage Azure Data Lake Store. Dans cet exemple, le fichier se trouve dans le Data Lake Store qui se nomme « franmer », dans le dossier « Franmer_Demo ».
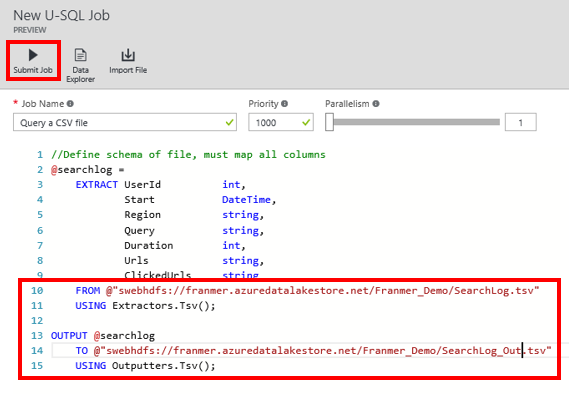
Le chemin complet se récupère de la manière présentée plus haut dans cet article et doit être de la forme : swebhdfs://franmer.azuredatalakestore.net/Franmer_Demo/SearchLog.tsv.
Cliquez sur le bouton « Submit Job ». Vous avez remarqué qu’il est aussi possible d’influer sur la priorité et le Parallélisme de l’exécution de la requête. C’est l’une des forces d’Azure Data Lake, qui permet une mise à l’échelle en fonction des besoins.
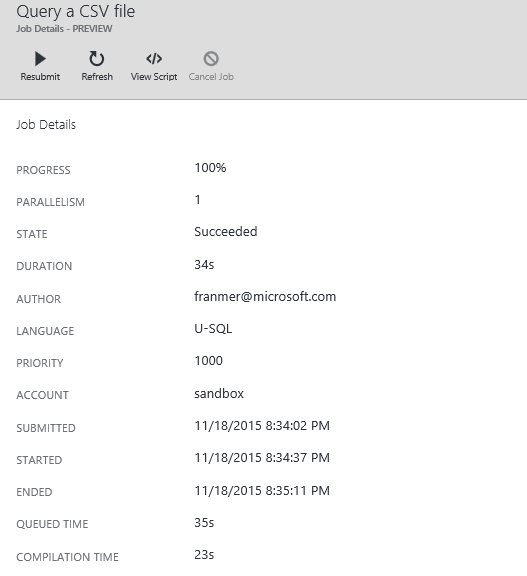
Une fois la requête terminée, vous devez avoir le rapport suivant. Si tout va bien vous devez recevoir un message avec l’état « Succeeded ».
Normalement, comme nous avons en fait réaliser une action de copie, je dois retrouver un fichier supplémentaire. En explorant notre Data Lake store, on observe bien la présence d’un nouveau fichier.