AppFabric Caching and SharePoint: Concepts and Examples (Part 1)
Part 1: AppFabric Caching and SharePoint: Concepts and Examples
Part 2: AppFabric Caching (and SharePoint): Configuration and Deployment
To assist with scaling and performance, SharePoint 2013 utilizes Windows Server AppFabric to maintain an in-memory cache of frequently-used data. While this in-memory cache achieves its goals and does improve scalability, it also adds another service to maintain to SharePoint’s long list of supporting elements. In this article I’ll summarize and distill information on AppFabric from across MSDN and TechNet and add a SharePoint tinge to it to help you prepare for and manage SharePoint’s Distributed Cache service.
If you’re an AppFabric admin, there’s a lot of detail here that will help you as well. Just view SharePoint’s AppFabric cluster and caches as an example of an AppFabric implementation.
We’ll begin with the fundamentals to ensure we all share the same basic understandings.
What is a cache?
As I said, we'll start with the fundamentals :). A cache is a local, non-authoritative copy of data created and/or stored authoritatively elsewhere. Because retrieval of the data from its authoritative source is an expensive operation, instead of retrieving it freshly each time it’s needed, previous copies of the data are retained and used for subsequent needs.
Reasons to avoid the authoritative operation include:
- Network latency and delays. The data may be stored across relatively slow network links or require multiple intermediate hops to be retrieved. Rather than retrieving it for each request, a copy is stored nearby. An example of this in SharePoint is the BLOB cache; BLOBs from content databases are stored locally on front-end servers to avoid the need for further network trips to SQL.
- User mediation required. The user may have to participate in retrieving the data, such as via authentication prompts and browser redirects. Imagine if a user had to undergo the three-legged process of WS-Federation authentication for every request! Far simpler to cache a security token and rely on it for subsequent requests.
- Processing power required. The authoritative data may be generated locally, but a relatively high amount of processing power is needed to generate it. Instead of regenerating the data for each request, a copy of the processed data is retained for a while. A good example of this is ASP.NET’s page output cache, which avoids ASP.NET having to fully process each request. A SharePoint-specific example is the SiteData Object Cache, wherein the results of cross-site list item queries are cached and used for subsequent requests to avoid the processing hit of running the query again.
- Authoritative source not consistently available. Perhaps the client or server cannot be consistently connected. If the client depended on always communicating with the data’s authoritative source, it wouldn’t be able to work when not connected. Caching the data locally mitigates this. SkyDrive Pro is an example of offline caching.
It’s important to call out that in all cases of caching, the expense of generating or retrieving the authoritative data is traded for greater memory requirements where the data is cached. Either RAM (short term) or hard disk (long term) memory will need to be allocated for the data.
Implications of Caching
The defining characteristic of a cache is that it isn’t the authoritative source of the data. This leads to some important ramifications:
- Cached data may not be completely current. Results and data may have changed at the authoritative source and not yet be reflected in the cached data. This effects many cache configuration choices, such as how long the cached data should be relied upon. There may be cases where the cache should be completely bypassed, or when a cache shouldn’t be used at all.
- Caches generally don’t need to be as resilient as the authoritative source. If cached data is lost, it can be retrieved or regenerated, albeit at an expense. Again, this effects decisions about cache configuration, such as redundancy and high availability. Since the cache can be regenerated with a minor performance hit, secondary copies and resiliency may be less important. Then again, they may be quite important, depending on how difficult regenerating the data could be.
Having discussed shared characteristics of all caches, let’s discuss some of SharePoint’s caching mechanisms.
Caches in SharePoint
Caches abound in SharePoint – from disk-based caches of data from databases, to in-memory caches of processed queries and pages, to caches of properties retrieved from internal and external services. The Distributed Cache service in SharePoint and its AppFabric underpinnings are just one example of a SharePoint cache. To emphasize this point, let’s begin by discussing some caches that have been around in SharePoint for a little while already.
Some common SharePoint caches include the BLOB cache, the ASP.NET page output cache, and the User Profile Service properties cache. We’ll describe them one by one to help you understand caches and their implications better.
BLOB Cache
Or Binary Large Object Cache. My wife always perks up when I bring up the cash blobs in SharePoint, at least till I start explaining them. If you’re reading this, you’re more interested in knowing that when a user requests a byte-stream object in SharePoint, such as a document or an image, and the item is retrieved from a SQL database to be sent to the user, the BLOB cache stores this object on the local file system of web servers. This avoids the need to retrieve the data from SQL again for subsequent requests for the same object.
Using this familiar example, let’s call out some of the advantages and disadvantages of the Blob Cache.
- The key advantage is avoiding the network latency of retrieving large files from across the network from SQL. In exchange for avoiding this trip, additional disk space is needed on the front-end servers. Note also that if the speed of retrieving data from disk isn’t faster than retrieving data from across the network, there’s limited benefit to this cache.
- Data could be stale. A user sending a request to one front-end server might update the large file, but a second user working on a different server could still be served an older copy cached on that server. There are mechanisms in place to check for updated files and deprecate the cached version, but there will always be points in time where the cached data is stale.
- The data is cached separately on each server. If a user requests the BLOB via one front-end server, the BLOB will be cached only there. If another user requests the same BLOB via another front-end server, that server will have to retrieve the BLOB itself, and store it again in its own file system. Note that AppFabric and the Distributed Cache are designed largely to mitigate this issue of cache locality (though not for the BLOB cache).
- The cache is less resilient than the database. If you lose the cached blobs, no critical data loss will occur. As such, you only back up and provide high availability for the database, not the cache.
Now let’s move on to the ASP.NET Page Output Cache.
ASP.NET Page Output Cache
Another well-known cache in SharePoint is the ASP.NET Page Output cache, which is actually a standard ASP.NET feature. It provides a good example of an in-memory cache designed to save processing power. Every incoming HTTP request causes activity and requires CPU cycles for ASP.NET’s HTTP handlers. The Page Output cache allows the results of this activity to be stored and re-used, avoiding the need for repeated processing of identical or similar requests. While for a request or two the performance gains may be small, for sites processing hundreds or thousands of requests, avoiding repeated processing saves a lot of resources and vastly improves scalability.
Let’s call out advantages and disadvantages of the Page Output cache.
- The key advantage is avoiding the use of processing power to process identical requests many times. In exchange for avoiding this CPU usage, memory is required to store the page output.
- Data could be stale. If the page’s processing retrieves data from a web service or some other changing resource, that data might have changed since the page was last processed, but the changes won’t be reflected in the cached page. An example I recently came across is the time zone entries in Wikipedia (e.g. US Eastern Time Zone). There’s a “current time” row in the information box on the page, but the time is usually stale. You can click “Refresh the Clock,” which apparently forces Wikipedia’s servers to discard the cached version of the page and generate a new one.
- Data could be inaccurate. This is a tricky one and one which a software architect would do everything to avoid. When data is processed for the sake of one request and then served to fulfill another, there’s a possibility that the context of the latter request isn’t exactly the same as the former. Generally, you’d account for significant changes of context by caching different versions of the data, such as one for authenticated users and one for anonymous users. There remains a possibility that differences in context could slip through, though.
- More RAM is required. This of course depends on how many requests are cached. Each one requires its own space in RAM (or perhaps hard disk). CPU resources have been saved, but if memory isn’t accordingly increased the exchange might not be worthwhile.
Let’s go through one more example of a cache in SharePoint, one which probably is not so familiar.
User Profile Application Proxy Settings Caches
User Profile Service Application (UPA) Proxies retrieve configuration details from their associated UPAs and databases and cache those details in several per-process in-memory caches. Settings stored in these caches include the URLs for MySite portals, Following limits, UPA sync configuration (e.g. whether to sync inactive users), and Newsfeed settings, among many others. Details such as the expiration time span (TTL) and max size for these caches can be viewed with the following PowerShell commands:
PS:> $UPAProxy = Get-SPServiceApplicationProxy | ? TypeName -Match 'User Profile Service Application Proxy'
PS:> $UPAProxy.Parent
The UPA proxy configuration settings caches are examples of caches meant to save the latency of network trips. After retrieving these properties from the associated UPA once, the UPA Proxy continues to rely on them for a period of time instead of requesting them again.
With UPA configuration details, being aware of the potential for stale data is important. For example, by default the Application Properties cache, which stores key configuration details for the UPA, only refreshes every 5 minutes. So if, for example, you configure your User Profile Sync job to sync inactive as well as active users (via stsadm –o sync –ignoreisactive), the setting may not be reflected in the cached properties for up to 5 minutes. If you have encountered situations where “IgnoreIsActive” didn’t seem to be having an effect, perhaps you ran sync too soon after changing the property.
This concludes our presentation of three typical caches and how they’re used in SharePoint. In the following table, I’ve also highlighted where the cached data is stored. We’ll focus on this aspect of caches next.
Cache |
Authoritative Source |
Conserved Resource |
Cache Location |
BLOB Cache |
Content Databases |
SQL Requests (over network) |
WFE Disk Drive |
ASP.NET Page Output Cache |
Processed ASP.NET Requests |
CPU Usage (on WFE) |
Web Process memory |
UPA Settings Caches |
UPA Web Services |
WCF Requests (over network) |
Web Process memory |
Cache Data Storage Location
By caching and reusing data, the consuming service subsequently saves the resources otherwise required to produce or retrieve that data again. But the scope of those savings depends on where the cached data is stored and what other elements of the service can access it. In each of the examples in the previous section, the scope of the cache is not service-wide. Not every element of the consuming service has access to the cached data; that is, not every process in the SharePoint farm has equal access to cached items. For the BLOB cache, only processes running on the same server that originally retrieved the BLOBs can access the cache; other servers still need to make a full SQL request and acquire the authoritative data. For the page output cache, each web process instance needs to generate the page once before being able to serve it, and cannot rely on the output page cache from other processes. And for the UPA settings cache, each web or service process which instantiates the UPA proxy needs to refill its own process-local caches.
The impact and resource savings of caching data can be scaled by expanding the scope of access to the cached data. If the processed ASP.NET page were accessible to all web worker processes in the farm, for example, many additional processing runs would be avoided, saving CPU cycles. In addition, if a single processed and cached copy of the page could be made easily accessible across the farm, memory needs would be reduced as well. Since in fact the output cache is per process, each process must process the request at least once (more CPU cycles required), and each process must allocate its own memory for the output page (more RAM required).
To address the need for wider scope and centralized storage of caches and cached items, centralized cache services are deployed. Instead of individual servers and processes retrieving and storing cached items locally and internally, they store them (and sometimes even retrieve them) via a centralized cache service. As a result, other servers and processes in the environment can access and benefit from the same cached data. To increase the scalability, availability, and redundancy of these cache services, they are usually deployed as distributed services, where multiple servers and processes present a single unified interface for storing and retrieving cached data. Sound familiar? We’ve just described the role and purpose of the AppFabric Caching Service, or in SharePoint-specific parlance, the Distributed Cache Service.
To state it again explicitly, the role of the AppFabric Caching Service (in SharePoint: the Distributed Cache Service) is to provide a centralized, widely-accessible service for storage of cached data items. This central service improves performance and scalability of many SharePoint processes by multiplying the benefits of caching across all of SharePoint’s servers and processes.
We’ll clarify the role of a centralized, distributed cache service by describing the data stored in some of SharePoint’s caches.
Distributed Caches in SharePoint
You can get a list of the distributed cache types used in SharePoint by running the following PowerShell command:
[Enum]::GetNames( [Microsoft.SharePoint.DistributedCaching. Utilities.SPDistributedCacheContainerType])
The caches available as of this writing (March 2013) are listed in the following table. We’ll focus here on just two of them for now: the LogonToken and ViewState caches.
ActivityFeed |
ActivityFeedLMT |
LogonToken |
ServerToAppServerAccessToken |
ViewState |
Search |
SecurityTrimming |
Access |
Bouncer |
Default |
Logon Token Cache
The LogonToken cache is the one you’re likely to encounter first both practically, since it’s used as soon as you hit your first SharePoint site, and in preparing for SharePoint deployment, since it obviates the need for affinity (sticky sessions) for WFE requests.
The process of logging on to SharePoint always culminates in creation of a session token which contains key details about the user, such as his or her username. Whether initial authentication uses Windows auth, Forms auth, or a SAML token issued by an external identity provider, the final result is this session token. To avoid the multiple steps involved in getting to this token, after it’s created during initial logon, it’s cached. Prior to SharePoint 2013, this cache was a server-local cache.
Having read the previous sections, you’ll know that a cache which is stored locally to each server has the disadvantage of requiring the authentication process to be repeated again at other servers. Depending on the situation, this could result in a) a small performance hit, as in regeneration of a Windows-based token; b) more evident delays, as in the WS-Federation redirects for external identity providers; or c) additional user prompts and interference, such as requiring the user to choose an identity provider and provide credentials again. To get around these issues, a common practice was to limit sessions to interaction with a single web server, where the necessary session token was guaranteed to be cached on first logon.
In SharePoint 2013, session security tokens are stored centrally in the Distributed Cache Service’s Logon Token cache. This cache and its tokens are thereby accessible across the farm, to all WFEs. As a result, after a user initially logs on to a SharePoint farm, they can hit any web server without the problems and penalties described in the previous paragraph. The web server uses the user’s Windows identity or session cookie to find and use the session security token in the cache.
Since we’ve introduced the logon token cache here, let’s discuss an additional element relevant to it.
The Two Parts of the Logon Token Cache
The distributed logon token cache is useful, but you likely have concerns. First, if the Distributed Cache Service isn’t running properly, the logon process and all access to the farm could be completely broken. Second, even if it’s running properly, retrieving cached data from a remote cache service takes a bit longer than retrieving it from a local cache, and first logon is a time when this is particularly conspicuous.
To address these concerns, in addition to the distributed logon token cache, there’s a complementary local logon token cache on each WFE. This is also known as the “Weak Reference Cache” because of the way it stores cached tokens. As long as the weak reference cache is enabled, as it is by default, logon tokens are cached in both the distributed cache and the local weak reference cache. When cached tokens are to be retrieved, first the weak reference cache is checked, and only if nothing is found there is the distributed cache checked.
The distributed logon token cache can be cleared with the Clear-SPDistributedCacheItem –ContainerType DistributedLogonTokenCache command. The local logon token cache can only be cleared by recycling the process where it’s contained (e.g. the w3wp process).
There are two registry values which control use of the Distributed and Local (WeakRef) caches. They’re both under HKLM:\Software\Microsoft\Shared Tools\Web Server Extensions\15.0\WSS, and are both DWORDs which default to 0 (false) if not specified. They are as follows:
DisableWeakRefCacheForToken
DisableDistributedCacheForToken
Note: I’m not advocating changing these values under any circumstances in a production environment. Please contact Microsoft Global Business Support if you need assistance.
Logon Token Cache Configuration
Key properties related to the logon token caches and their default values are listed here:
PS:> Get-SPSecurityTokenServiceConfig | Format-List *LogonToken*,*WindowsToken*
MaxLogonTokenCacheItems : 250
MaxLogonTokenOptimisticCacheItems : 100000
LogonTokenCacheExpirationWindow : 00:10:00
WindowsTokenLifetime : 10:00:00
MaxLogonTokenOptimisticCacheItems defines how many tokens are kept in the local Weak Reference cache, and MaxLogonTokenCacheItems specifies how many of these are stored as strong references instead of only weak references (details on weak references are available here). LogonTokenCacheExpirationWindow specifies how close to expiration tokens are considered to already be expired. So by default, tokens are considered expired 10 minutes prior to actual expiration time. Finally, WindowsTokenLifetime is used to set the Time-To-Live in the distributed logon token cache for cached security tokens of all types (not just Windows-bootstrapped tokens).
With these details in mind you should be better equipped to deploy, maintain, and troubleshoot the logon token caches. Let’s describe the usage and benefit of one other distributed cache, and then we’ll dive into details of the cache system itself.
The View State Cache
ASP.NET Web Forms maintain state between requests in a session using View State. Towards the end of the page processing lifecycle, details about the page’s state are serialized and added to the HTML to be sent to the browser as a hidden form field. When the browser posts back to the server on subsequent requests, it includes the hidden View State form field (named __VIEWSTATE). The server uses the posted back view state to rehydrate state from previously processed requests, creating the illusion of a stateful session across multiple stateless HTTP requests. ViewState has been around for a while and there are many articles available on it; here’s a good one if you’d like a quick review. A drawback of the ASP.NET ViewState system has always been the extra data transferred to the browser and back to the server on each response and subsequent request, which can reach the tens of kilobytes.
SharePoint is built on ASP.NET Web Forms and as such is dependent on ViewState and its attendant drawbacks. To improve page performance, beginning in SharePoint 2013 SharePoint caches ViewState data server-side rather than transferring it back and forth to clients. In the previously linked article, pay particular attention to the section on specifying where to persist the view state. In that section, an example is presented of caching ViewState data server side by storing it in the web server’s local file system.
SharePoint’s system is similar to that presented in the article, but such a server-specific scope would lead to some of the problems discussed previously for the old logon token cache system: subsequent requests would have to be routed to the same server where ViewState was originally cached. So instead SharePoint uses the same mechanism, but persists ViewState data to the distributed ViewState cache, sending only a GUID to the browser. Compare the __VIEWSTATE hidden form field from a SharePoint 2010 page to that from a SharePoint 2013 page, and you’ll see that only a Base64-encoded GUID remains.
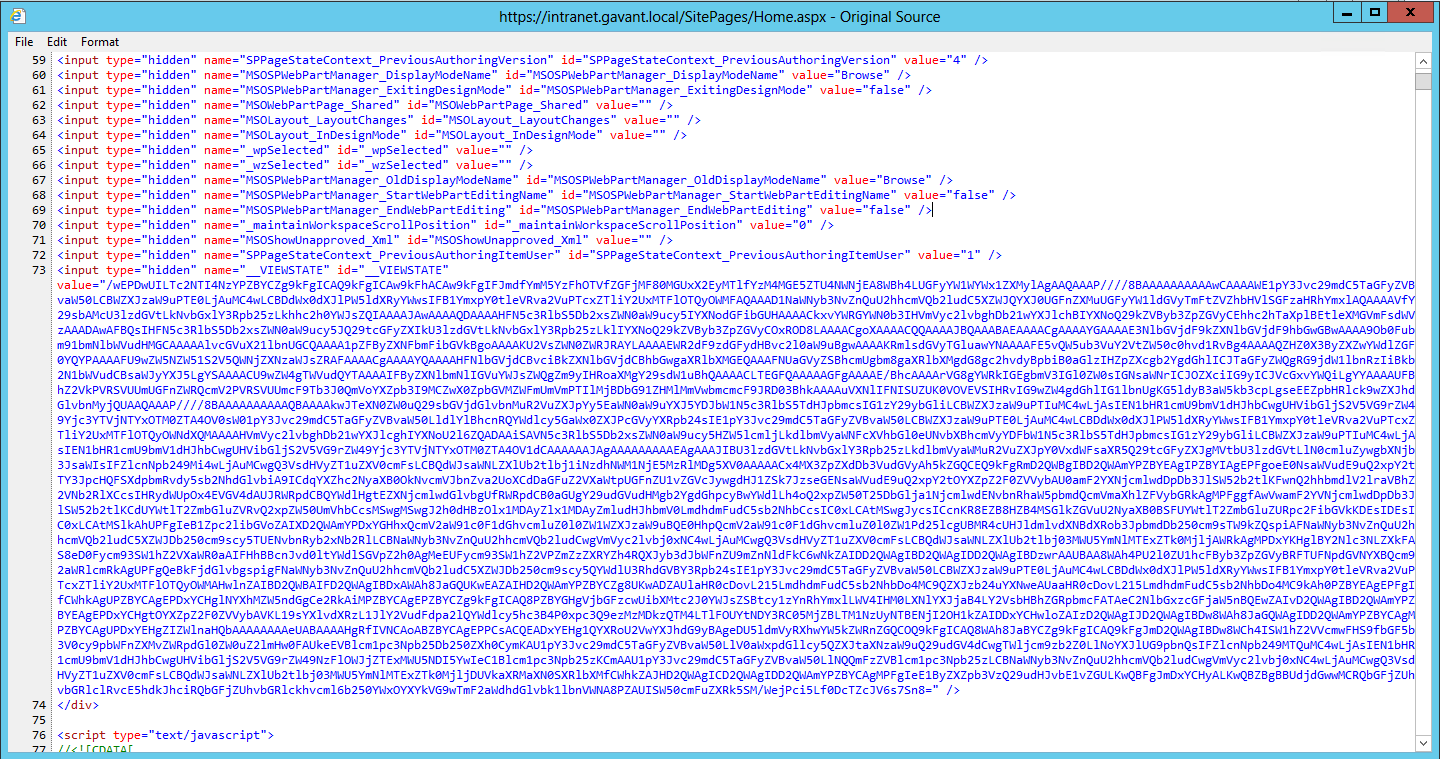
ViewState data in a SharePoint 2010 page (the large field).
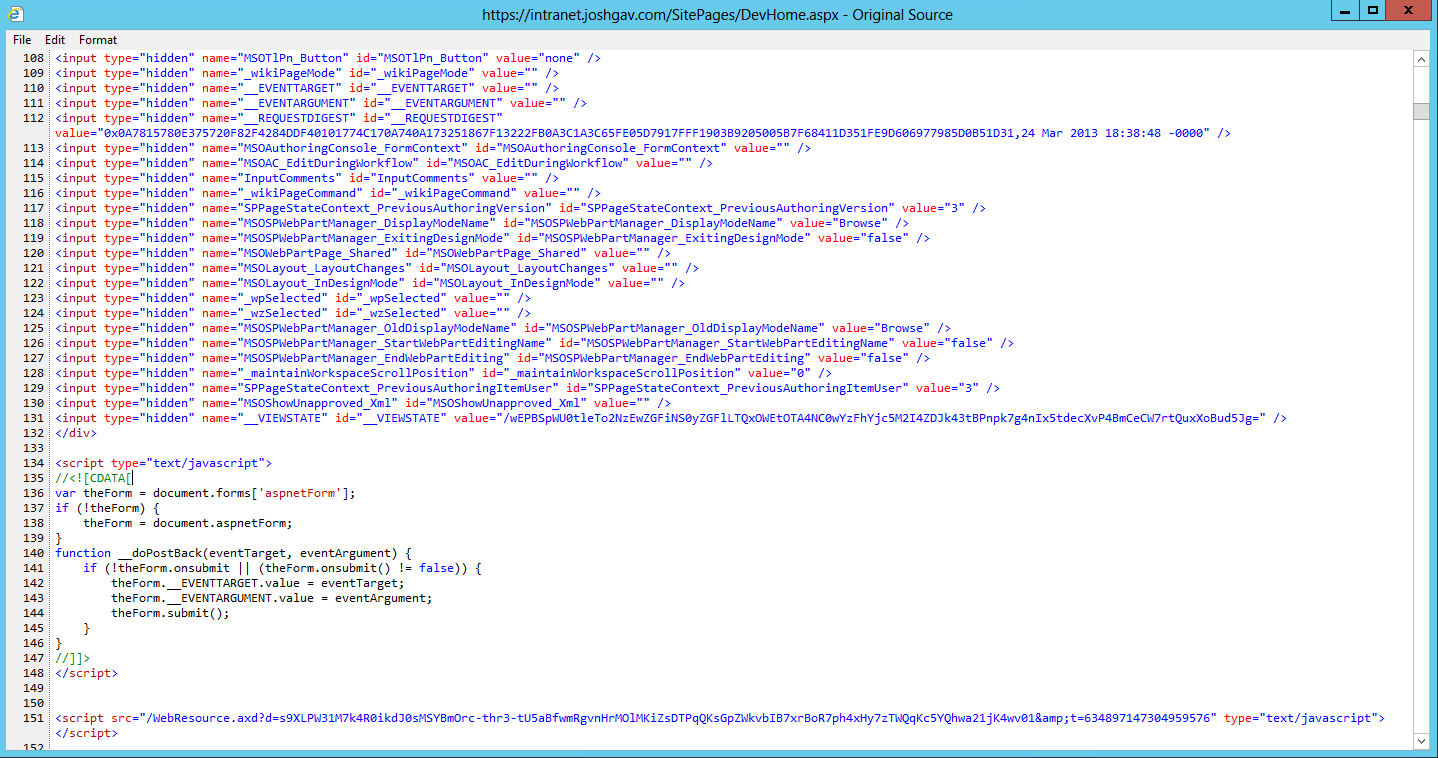
ViewState data in SharePoint 2013 (the last input field).
Where did all that data go? The actual ViewState data is stored in and loaded from the distributed ViewState cache, with entries for specific sessions keyed by the GUID passed back and forth from the browser. Use of this cache is governed by the SPWebService.ViewStateOnServer property, which can be accessed via these commands:
PS:> $ContentService = [Microsoft.SharePoint.Administration.SPWebService]::ContentService
PS:> $ContentService.ViewStateOnServer
These descriptions of the distributed Logon Token Cache and distributed View State Cache will help you recognize why a distributed cache service is helpful along with some of the performance and scalability advantages it presents. Now let’s move on to discuss the distributed cache service itself.
Continue with AppFabric Caching (and SharePoint) (2).