Maintaining and synchronizing your reference data through the database project
For database application developers working on data driven applications their reference data is as important and meaningful as the database schema itself. In fact, the database schema is incomplete when the reference data is absent. When I say reference data, I am speaking of the non transactional data within the database. This data goes by many different names in different organizations. Here are some of the more popular ones: Static Data, Domain Data, Seed Tables, Static Data, Meta Data, and Look Ups.
I have worked on many projects were we managed the reference data along with the rest of the application’s source code artifacts. It was always critical that these reference data were managed under the same configuration management process as the rest of the application. The reasoning behind this was that I/we (depending on team and gig) typically implemented data driven applications with flexible data models. This often afforded the customer flexibility to comprehend business requirements down the road without expensive code modifications. As a result, without the correct or appropriate reference data these applications would not be very functional or worse misbehave. I have also worked on projects where there was reference data, but in addition the application used hard coded values that controlled the execution of the application. Without predetermined reference data these applications would not run and often have runtime errors. While not good design, I have seen it many times. This typically happens when apps go through a top down design, but I digress…
We often receive questions from the database development community as to how to best manage reference data. Different strokes for different folks comes to mind, but I thought I would share an approach that works really well for average sized reference data tables. This approach is specific to SQL Server 2008, but can be modified to work with the previous versions of SQL Sever with some simple modifications.
Let's assume you have a table called products in your project like(Products.table.sql):
CREATE TABLE [dbo].[Products]
(
Id INT IDENTITY(1,1) NOT NULL CONSTRAINT PkProductsId PRIMARY KEY,
Name NVARCHAR(50) NOT NULL CONSTRAINT UqProductsName UNIQUE,
Description NVARCHAR(250) NULL,
Created DATETIME NOT NULL,
Updated DATETIME NOT NULL,
Deleted DATETIME NULL
)
Next, you then need a way to synchronize changes to this data. For this company we will sell beer. Guess where my mind is? So you create the following script file (SyncProducts.sql):
PRINT 'Starting [dbo].[Products] Syncronization'
GO
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = N'xxxSyncxxProducts')
DROP TABLE [dbo].[xxxSyncxxProducts]
GO
CREATE TABLE [dbo].[xxxSyncxxProducts]
(Name NVARCHAR(50) NOT NULL,
Description NVARCHAR(250) NULL)
GO
SET NOCOUNT ON
INSERT [dbo].[xxxSyncxxProducts](Name, Description)
VALUES
(N'Guinness', 'Irish-Style Stout')
,(N'Carlsberg','Danish Pilsner')
,(N'Scuttlebutt', 'India Pale Ale')
,(N'Corona','Mexican Lager')
--,(N'Your', 'Favorite Beer')
SET NOCOUNT OFF
GO
MERGE [dbo].[Products] AS Target
USING [dbo].[xxxSyncxxProducts] AS Source ON (Target.Name = Source.Name)
WHEN MATCHED
AND Target.Description <> Source.Description
THEN
UPDATE
SET Target.Description = Source.Description,
Target.Updated = GetDate(),
Target.Deleted = NULL
WHEN NOT MATCHED BY TARGET
THEN
INSERT (Name, Description, Created, Updated)
VALUES (Name, Description, GetDate(), GetDate())
WHEN NOT MATCHED BY SOURCE THEN
UPDATE SET Target.Deleted = GetDate();
GO
DROP TABLE [dbo].[xxxSyncxxProducts];
GO
PRINT 'Done Syncronizing [dbo].[Products]'
GO
Finally, you then need a method to execute the synchronization as a part of deployment. This is done by including the script file in the post deployment script like so (Script.PostDeployment.sql):
:r .\RefDataSync\SyncProducts.sql
Here’s what it looks like when it is deployed.
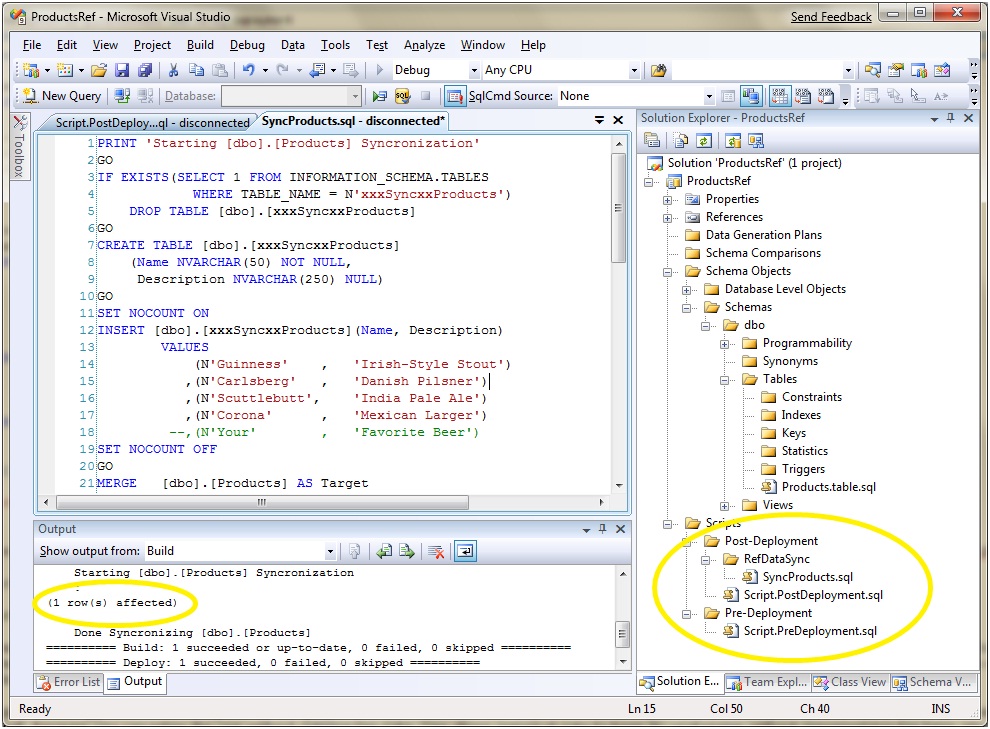
During development, if marketing tells you they have a new beer to drink, I mean sell, you simply checkout the SyncProducts.sql file and make the necessary edits and check it back in. Every time you deploy your project, incremental changes to the database's reference data will be synchronized. also This includes fully populating the table when you deploy a new database. You can also run the script by the opening up the file in Visual Studio and clicking “Execute SQL”. This allows you to make changes out-of-band from the release yet still have the changes captured in SCC.
Note that I am using a logical delete approach which is a personal design preference . You could also blast the records if you like, but then you have to worry about constraints that may get violated. The logical delete works well, because you can retire the row without deleting the data. This allows historical data to keep its relationship without denormalizing the table into an archive.
Let me know what you think about this approach. How could this be made easier and what is it missing?