Service Fabric and Kubernetes: community comparison, part 1 – Distributed Systems Architecture
NOTE: This is a community-driven comparison from the author's experience and perspective.
Special thanks to Matthew Snider from the Service Fabric team for reviewing this article, sharing his insights and tons of facts from the Service Fabric history.
Introduction
During the last decade, distributed services platforms are drawing more and more attention. These platforms are revolutionizing the way we think about systems architecture, bringing multiple theoretical computer science concepts to the wider audience that previously were considered very specialized or unpractical. Notable examples include the distributed consensus and actor models.
This tendency coincides with the rise of NoSQL databases showing that the way we were building systems might be suboptimal, rendering the very popular N-tier architecture obsolete, being eagerly replaced by the architects with Service Oriented designs and eventually Microservices approach.
New concepts started emerging at the companies that were facing issues at the largest scale. It involved significant amounts of R&D costs, risk, etc. Today, public cloud platforms are making those technologies available to the wide audience.
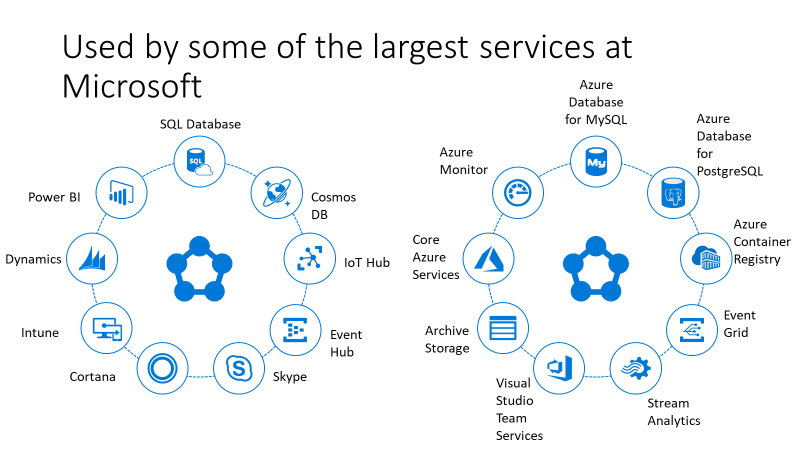
At P2ware, we have been one of the early adopters (outside of Microsoft) of Service Fabric – the distributed services platform that runs many Microsoft services such as Event Hubs, Event Grid, Azure SQL Database, Azure Cosmos DB, Cortana, and the core Azure resource providers (Compute, Networking, Storage).
I would like to share some of what I have learned when adopting Service Fabric and try to compare it with the currently most popular container orchestrator, Kubernetes, which runs numerous different distributed applications today.
Different history, different goals, different design
From e-Home to Azure Stack
Service Fabric’s history starts in 2001. It was developed into a “Software system that weaves together machines across datacenters into logical, scale-free, geo-distributed, hierarchical and consistent distributed system”. From the beginning, it was designed to be resilient, independent, self-healing and ran on site. In a great video Gopal Kakivaya, the founder of the Service Fabric team, mentions that the idea started with Microsoft e-Home an obviously uncontrolled, no-ops environment.
It is no surprise that Service Fabric (under the name Windows Fabric) is responsible for running Microsoft products on-premises such as Lync Server. The bigger surprise is that the same system turned out to be a great fit to run hyper-scale cloud workloads in Azure.
Service Fabric powers many Microsoft services today, including Azure SQL Database, Azure Cosmos DB, Cortana, Microsoft Power BI, Microsoft Intune, Azure Event Hubs, Azure IoT Hub, Dynamics 365, Skype for Business, and many core Azure services.
The entire Microsoft Azure Stack hybrid offering relies on Service Fabric to run all the platform core services. It is also a great example of a no-ops environment which is designed to run in disconnected environments like factory floors and cruise ships.
SQL Data Services
Service Fabric technology was disclosed publicly first at the Microsoft PDC 2008 conference under the name “Distributed Fabric”. At this time it was the basis for SQL Data Services, launched at 2010. Gopal Kakivaya’s talk on SQL Data Services from PDC2008 is available on Channel 9.
Running an advanced relational database on a Cloud scale is huge challenge and it required solving a lot of problems. This project not only laid a strong foundation for resilient state replication and failure detection, but also has constituted a strong self-contained mindset.
To achieve high availability SDS was supposed to minimize the external dependencies and avoid introducing additional single points of failures or circular dependencies. This also helped to significantly simplify the deployment.
At that time SSDs were quite expensive and one of the project goals was to protect the investment in spinning drives. One of the little-known SF features is the shared log file facility (Ktlogger) designed to make the best use of spinning hard drives.
First box product and general development platform
Service Fabric team and product started in 2009 as a rewrite of SQL Data Services and first internal alpha was released in the fall of 2011. Lync Server 2013 (released in October 2012) was the first box product using this technology (named Windows Fabric at that time).
Service Fabric as a general platform for development by 3rd parties was announced in 2015 and previewed at Build that year and then GA’d at Build 2016
Borg and Kubernetes
Kubernetes is a fairly young technology and its first stable release dates to July 21, 2015. However, it is conceptually based on and strongly influenced by Borg – the orchestrator responsible for managing the entire fleet of machines in Google data centers internally. Google has released a paper providing a lot of interesting details about Borg. It is important to note that Borg focuses on orchestration, and not on specific programing models or state management.
The main differences between Kubernetes and Borg:
- Borg is focused on power-users
- Borg orchestrates plain old processes running huge, statically linked, resource-limited executables while Kubernetes orchestrates containers - what makes Kubernetes easier to use, but introduces some additional overhead and disables some advanced (privileged) scenarios
- Kubernetes API server is designed to be much more general and microservices based
Community driven and heterogenous
The microservices-oriented, container-centric and highly unopinionated approach to Kubernetes design has enabled a huge community around Kubernetes to create many microservices and plugins, and easily port their software to the platform. However, each of them is responsible for handling problems like data replication on their own, making the platform highly heterogenous.
Architecture differences
Such different backgrounds must have led to the conception of two completely different results. In this chapter, I will try to compare the most significant (in my opinion) differences.
Centralized
[caption id="attachment_9925" align="aligncenter" width="800"]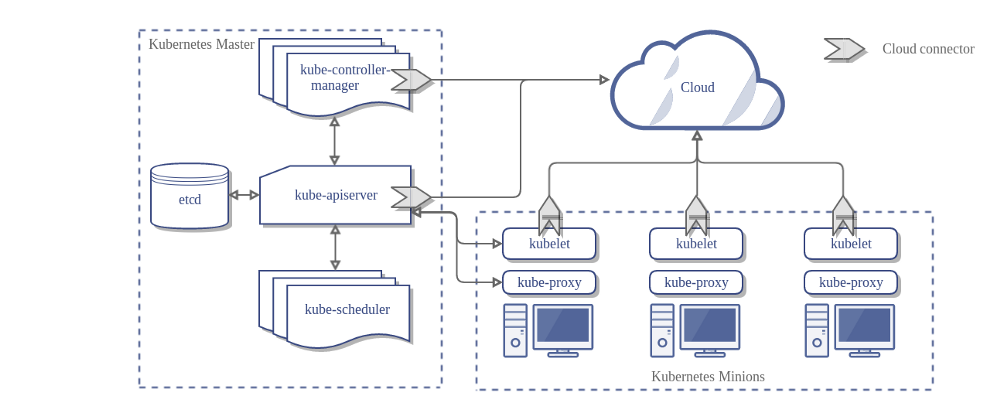 Kubernetes architecture - kubernetes.io[/caption]
Kubernetes architecture - kubernetes.io[/caption]
Paradoxically, Kubernetes is a heavily centralized system. It has an API Server in the middle, and agents called Kubelets installed on all worker nodes. All Kubelets communicate with the API Server, which keeps the state of the cluster persisted in a centralized repository: the etcd cluster. The etcd cluster is a fairly simple Raft-backed distributed KV-store. Most production configurations use between 3 and 7 nodes for etcd clusters.
To maintain the cluster membership information, all the Kubelets are required to maintain a connection with the API Server and send heartbeats every period of time (for example 10 seconds).
Such an approach can have negative effects on the scalability. A good example of such an issue is presented here (with some mitigation proposals – not as great as might seem, what I will explain later).
Decentralized - Ring and Failure Detection
The key to understanding the design of Service Fabric is the following quote:
"The design of fault-tolerant systems will be simple if faulty processes can be reliably detected. […] Distributed consensus, which is at the heart of numerous coordination problems, has trivially simple solution if there is a reliable failure detection service."
- Sukumar Ghosh, Distributed Systems - An Algorithmic Approach, Second Edition
The authors of Service Fabric, instead of using a distributed consensus protocol like raft or paxos (which does not scale well with growing number of nodes), or using a centralized store for cluster state (which might use distributed consensus underneath, and which represents a separate point of failure), have focused on designing a fully distributed system. Within Service Fabric’s architecture, this is referred to as the Federation Subsystem.
The Federation Subsystem is responsible for giving a consistent answer to the core question: is the specific node part of the system? In the centralized approach discussed earlier, this answer was given by the API Server based on the heartbeats received from all the nodes. In Service Fabric, the nodes are organized in a ring and heartbeats are only sent to a small subset of nodes called the neighborhood.
The arbitration procedure, which involves more nodes beside the monitors, is only executed in case of problems like missed heartbeats. This significantly decreases the traffic and potential network congestion problems, as the traffic is evenly distributed across the cluster. During arbitration, a quorum of privileged nodes (called arbitration group) is established to help resolve the possible failure detection conflicts, isolate appropriate nodes, and maintain a consistent view of the ring.
This is a simplified description of failure detection and arbitration – you can see the full algorithm in the following paper - Kakivaya et al., EuroSys’18 (nicely summarized in the Morning Paper blog post).
[caption id="attachment_9935" align="aligncenter" width="388"]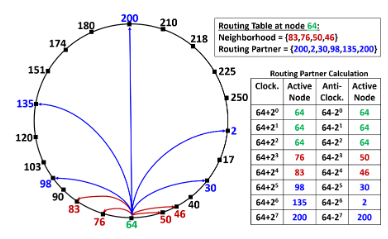 Example routing table for node 64 in Service Fabric ring - Kakivaya et al., EuroSys’18[/caption]
Example routing table for node 64 in Service Fabric ring - Kakivaya et al., EuroSys’18[/caption]
Core infrastructure services
Due to its centralized nature, most of the core infrastructure services in Kubernetes are placed on the master nodes.
Service Fabric uses a different approach, where most system services are standard Service Fabric Reliable Services and are distributed among the entire cluster respecting the placement constraints. For example Azure-hosted Service Fabric clusters run system services on the primary node type only.
[caption id="attachment_9945" align="aligncenter" width="800"]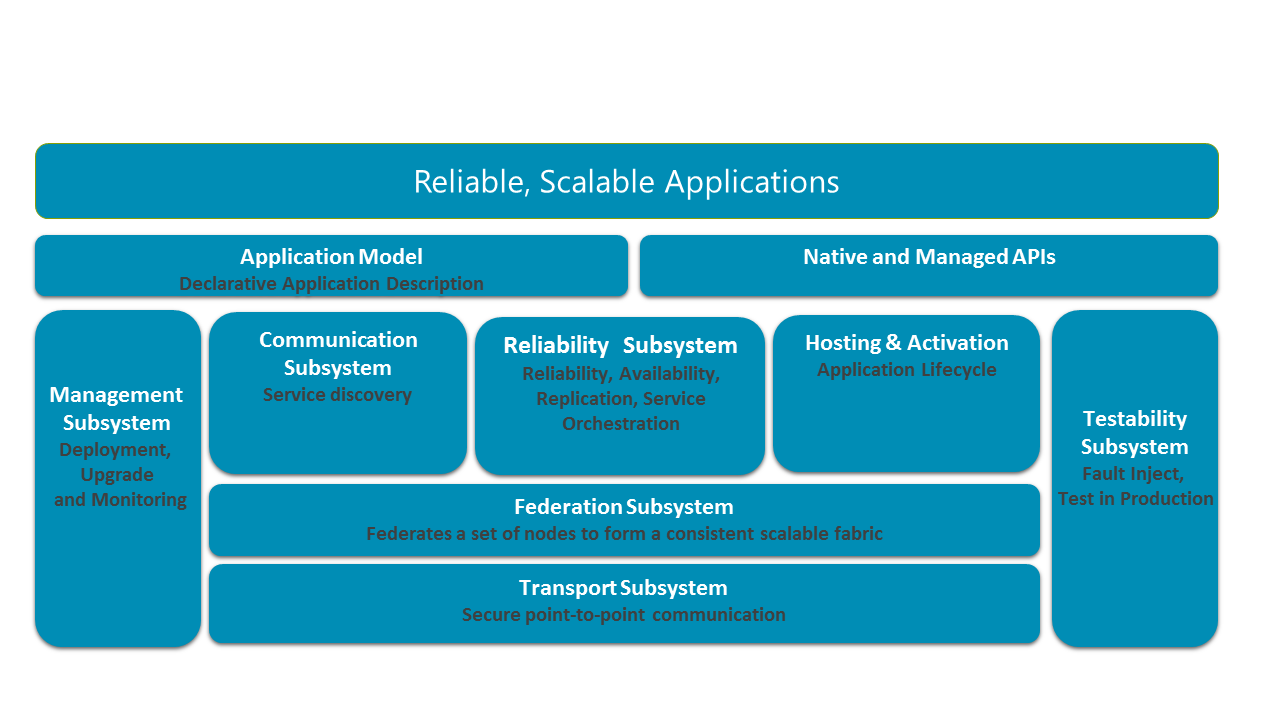 Service Fabric high level architecture - docs.microsoft.com[/caption]
Service Fabric high level architecture - docs.microsoft.com[/caption]
If something goes wrong
A lot of things can go wrong (the more machines in the cluster, the more likely), the most trivial examples being node failure, workload failure, or network outage. To achieve the best availability, failed nodes should be detected ASAP, but this is way more important for stateful workloads than stateless ones.
In case of stateless workloads, one can have multiple instances of a service that will accept the traffic if a single instance is not available. Kubernetes addresses failure detection via liveness probes that allow it to determine whether a specific service instance is up or down. Alternatively, load balancer probes also help detect a malfunctioning service.
False positives are not a big problem here – there is no singleton guarantee. By default, Kubernetes will need around five minutes to determine that a node is dead (it much earlier marks that node as a suspected and it stops scheduling workloads for it).
Split brain and other stateful disasters
On the other hand, for stateful workloads, a false positive can mean disaster. It leads to typical problems like split brain, lost writes and many others. There are many different approaches to dealing with this issue (fencing, STONITH, distributed consensus, leases), but the most important point is that for a strong consistent workloads you cannot have two processes running at the same time where both are able to perform writes. This is the place where fast failure detection brings the most value.
Because Service Fabric was designed to run both stateless and stateful workloads, it tries to detect dead nodes ASAP. Its design allows sending heartbeats much more often in order to detect and correct failure. 5 minutes of unavailability is unacceptable for a stateful service in many scenarios. The default lease duration in Service Fabric is 30 seconds, though different types of failures can be detected sooner, and most network partitions are detected within 10 to 15 seconds.
Eventually consistent databases like Riak (especially with facilities like good CRDT-support) are much better candidates to run on K8S clusters than the strong consistent databases.
Where is the state persisted?
The above helps explain why Kubernetes is good for stateless services but may not the best pick for stateful workloads. However, a fair question is why should we even use stateful services, when are all used to persisting data in a centralized database?
The first and most obvious answer is because the database must be managed as well, and unless you are using DBaaS, you must host it somewhere. The other answer is because local stateful services can be faster than remote data storage. If the database is on the local machine or in-process, it allows workloads to achieve sub-millisecond latencies, especially in conjunction with ephemeral SSD or NVME. A typical machine for a Service Fabric node should ideally have a large ephemeral SSD not use external volumes, allowing the services to make best use of the local hardware.
External volumes pose also a huge risk to the cluster availability by introducing a single point of failure.
Another scenario is to use non-persisted (volatile) stateful services for caching. In a traditional approach such services are implemented as stateless services, but a cheap leader election, failure detection and partitioning allows to use volatile stateful services for such a purpose. Fast failover allows to have a smaller number of instances and in consequence use much less RAM.
How is the state replicated?
Service Fabric provides a unified replication layer that helps to build replicated datastores using proven and well-tested infrastructure. If you remember the earlier discussion on how Service Fabric handles failure detection, you’ll note that this influences the requirements for the replication layer – the individual replication layer no longer needs paxos, raft, zab, or other consensus protocols for replication. The Reliability Subsystem depends on the Federation Subsystem to detect failures and manage membership in the cluster, allowing the Reliability Subsystem for focus on replication. Replication can be simpler since it doesn’t have to manage membership, Replicators can focus on providing atomicity and data durability via techniques such as WAL and ARIES. It’s worth noting that while Service Fabric provides a Replicator and replicated data structures out of the box that implement these patterns, the Replicator component is actually pluggable, and could be different for different workloads.
This approach is used for Service Fabric Reliable Collection-based applications, Azure Cosmos DB, Azure SQL Database, and many others.
In the case of Kubernetes, each stateful workload is responsible for handling their own replication and leader election, without real access to the underlying infrastructure. There are 3 most common approaches to this problem:
- Use the shared etcd and leases for failure detection and leader election
- Use a private etcd or Apache Zookeper instance for failure detection and leader election – this helps to deal with some of the centralized etcd scalability issues
- Use a database that handles its own replication, like CockroachDB which uses raft internally for state replication, failure detection and leader election
Persistent Volumes
To be able to run a datastore on a distributed systems platform, you need a place to store the raw data. I already mentioned that Service Fabric makes a great use of ephemeral SSDs, while Kubernetes usually requires mounting an external network volume or block device (with an exception for Rook, described in a later section). This not only introduces an additional point of failure and overhead, but also impacts availability, because especially block-device mounts usually implement additional leasing mechanisms that introduce additional delays and prevent fast failover. For example Azure Disk has a 5 minute-long lease by default, which prevents mounting it to another host node after dirty shutdown for at least 5 minutes.
Service Fabric HA Volume
Still, Volume Mounts are extremely useful for the Lift and Shift Scenarios – there are simply many workloads out there that expect to be writing to a “local” drive. Service Fabric is making it easier to run lift-and-shift workloads on the platform by introducing Service Fabric HA Volumes, which are highly-efficient, replicated, SSD and memory-backed persistent block devices managed by the Service Fabric cluster (benefiting from all the failure detection) that can be mounted to a container. Those mounts are not introducing any new external single point of failure, because they are local to the cluster.
Database in cluster
When hosting a preexisting DBMS in a cluster, multiple approaches might be taken:
- Use Service Fabric native capabilities and integrate at the Replication layer level – involves a significant amount of work, but also provides the deepest integration with the platform around ensuring high availability and reliability. This allows the existing storage engine and replication technology to be used more or less as is. This is how SQL Azure Database is built.
- Utilize the built in Service Fabric replicator to bring replication and HA at a byte[] level to an existing or new data store. This is significantly simpler than writing or modifying existing replication technology or a storage engine, and provides a good tradeoff between complexity, development time, and performance. Many Azure services have integrated with Service fabric at this level, including Intune.
- Utilize the service fabric reliable collections as the data store. We discard this approach for existing RDBMS systems as they are unlikely to be easily mapped to Service Fabric’s reliable collections.
- Utilize Service Fabric HA Volume and run a single container with the database. This approach is a means to getting most of the benefits of 1 or 2, but without having to modify the RDBMS code at all or integrate with the Service Fabric platform.
- Run multiple container instances with the database, utilizing (Local) Persistent Volumes and use DBMS-specific replication and failure detection. CockroachDB, which uses built-in raft, is a good example of such a DBMS. Other examples of such approach (this time using external etcd or zookeeper instance): Stolon for PostgreSQL or an attempt to run Kafka on K8S using a beta feature called Local Persistent Volumes described here. This approach, requiring a lot of hacking and testing, will be probably typical for Kubernetes.There are many possible options here - different kinds of Persistent Volume can be used here - each one with its pros and cons and possible compatibility issues. Local Persistent Volumes are also an option, however it is worth remembering that at least today Kubernetes does not provide strong enough integration with most of cloud providers to mitigate most of the potential data-loss risks (more details in the next section).
Rook
Solutions 1,2, and 3 are not available directly for Kubernetes, but Rook is a CNCF project which aims to make storage within the Kubernetes environment which uses Ceph under the hood. It offers something a bit similar to SF HA Volumes. It is usually not backed by the high performance ephemeral SSDs but by the network Persistent Volumes. It allows to achieve something between 2 and 3.
It is technically possible to use ephemeral SSDs (Local Persistent Volumes) for Rook, but in that case, special considerations are needed, especially in the area of graceful shutdown and scheduled maintenance handling. By default, Kubernetes does not leave enough time to gracefully move data outside the node being shut down. In general, management operations on Services inside a Service Fabric cluster are asynchronous and Service Fabric provides the services running inside it as much time as they need in order to shut down cleanly. However, Service Fabric does not control the infrastructure on which it runs. This means that if the layer that manages the infrastructure wants to shut down a machine, it is free to do so. In most cases Service Fabric will observe this as an unplanned failure. Service Fabric does support APIs that any infrastructure layer could use to first “get permission” from Service Fabric to shut down a given node, ensuring that the workloads had sufficient time to move or for Service Fabric to guarantee that the failure would not impact the workload. With more mature Cloud-platform integration Kubernetes should gain such similar capabilities at some point of time.
In Azure, this integration is referred to as the “Durability Tier” that a given VM Scale Set operates with. (https://docs.microsoft.com/en-us/azure/service-fabric/service-fabric-cluster-capacity#the-durability-characteristics-of-the-cluster).
Design consequences
Hyperconvergence and IoT Edge
Effective failure detection and replication mechanisms combined together with strong decentralization enable efficient use of ephemeral storage, networking resources, and computing resources, making Service Fabric a key element of the hyperconvergence puzzle. Service Fabric can efficiently run on the commodity hardware or even can form clusters using the small IoT Edge devices. This capability was recently demonstrated in Mark Russinovich’s “Die Hard” demo.
Extreme scalability
If you browse the web, there are many stories about etcd tuning exposing their scalability issues. Meanwhile, Subramanian Ramaswamy ran the following demo during the Ignite conference – orchestrating 1 million containers, which is more than 8x the OpenShift limit (120 000).
Failover so fast it can control the network itself
On the other hand, Service Fabric can be tuned to be used as a Network Controller for Software Defined Networking, which presents fast failover capabilities.
Geographical distribution
Cortana already uses Service Fabric in such a manner. The main facility enabling this capability are the hierarchical fault domains, for example: fd:/westeurope/1. This distinction enables the failure detection to differentiate between intra- and inter-region heartbeats, being a bit more forgiving to cross regional networking errors.
The most important limitations of Service Fabric’s geographically distributed approach are:
- There must be at least 3 regions, because no region is privileged and there must be a quorum to be able to determine which region is down
- Service Fabric is strongly consistent – which means that if an eventually consistent geographically distributed solution (one that must survive longer connectivity problems across the regions) is required – multiple separate clusters should be created – which gives Kubernetes the upper hand for eventually consistent systems
Etcd scalability issues and centralized design make strongly consistent cross-regional configurations unfeasible.
Stateful services
Service Fabric has no competition when it comes to orchestrating mission-critical stateful workloads. It is a strongly consistent platform that is able to provide guarantees like RTO < 30 seconds in case of single rack/availability zone failure, or RTO < 60 seconds in case of entire region outage, with RPO = 0 guarantee, while maintaining high performance and extremely low latency from extensive use of RAM and ephemeral SSDs.
Those timeouts are only the guarantees for the worst-case scenarios. A typical failover in case of node failure takes around … 2 seconds – which is mind blowing.
[caption id="attachment_9955" align="aligncenter" width="410"]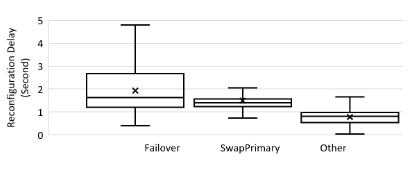 Statistics of different Reconfiguration Delays in the 20 day trace - Kakivaya et al., EuroSys’18[/caption]
Statistics of different Reconfiguration Delays in the 20 day trace - Kakivaya et al., EuroSys’18[/caption]
Benefits of consistent cluster membership
One of the most significant differences between Service Fabric and Kubernetes is the cluster membership consistency. Service Fabric Federation Subsystem, by providing a single strongly consistent cluster membership information, offers multiple benefits:
- Simplifies replicator implementation and effectively helps to avoid distributed systems bugs which are extremely hard to detect, test and mitigate
- Provides name resolution services consistent with the cluster state – enables efficient resolution of primary replicas (Service Mesh/Ingress Proxy can be easily made consistent with the entire cluster state)
- Saves resources by not requiring to run multiple etcd or ZooKeeper instances (which are often required to avoid shared etcd scalability issues)
- Provides optimal failover time
- Provides consistent monitoring view for the entire cluster
- Simplifies and allows the platform to provide unified services and features like Health Management, Rolling Upgrades, Resource Load Balancing, Repair Management and Testability
- Provides a very efficient programming model called Reliable Services
- Provides integrated HA Volumes out of the box for Lift and Shift scenarios
Conclusion
I hope I was able to present how different are the principles used in design of these two platforms. Please leave some comments - it will definitely help to prepare next parts of this series.
Don’t forget to come back for the next parts which are going to cover the less theoretical elements like different programming models, application models, hosting, isolation, microservices patterns and facilities and operational characteristics including resource load balancing, rolling upgrades, cloud provider integration, tooling, monitoring and packaging.