Microservices - Disaster Recovery, GeoHA and GDPR
In Part 1, the affect a microservice architecture has on building a service, including dependent data and how transactions are handled, was discussed. This post will explore some important aspects of a microservice architecture including Disaster Recovery (DR), geographically dispersed solutions and High Availability (GeoHA) and data compliance such as GDPR.
Disaster Recovery
DR is an important consideration in a solution's architecture. Concentrating on the repository, this involves some form of backup and the challenge when there is related data of how to recover from a failure so the entire model is consistent. Take the following diagram of a inventory and order system showing a system at the time of failure. The backup of the customer database is missing an entry for Customer B while the backup of the order service contains an order for Customer B (i.e., Order B1):
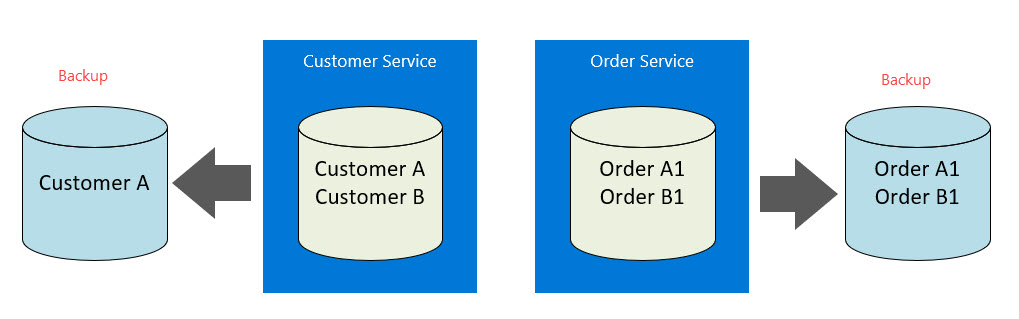
After the customer service repository is restored, the view of the system will become inconsistent as Customer B will still be missing but there is an order for them in the Order Service repository. The more repositories you have, the more this issue becomes challenging.
The CAB, CAP and BAC theorems all equate to a trade-off between consistency and availability. For example, one way of approaching DR across microservices is to periodically backup the entire system as a whole. To ensure consistency, all writes would need to be suspended to ensure there is a consistent backup. By suspended writes, or read-only, availability is sacrificed. At a minimum coordinating a consistent backup would require all microservices to agree on a backup schedule, a read-only or offline mode during the backup, and for the backup duration to wait until the slowest microservice has completed.
Shared Database with isolated schemas
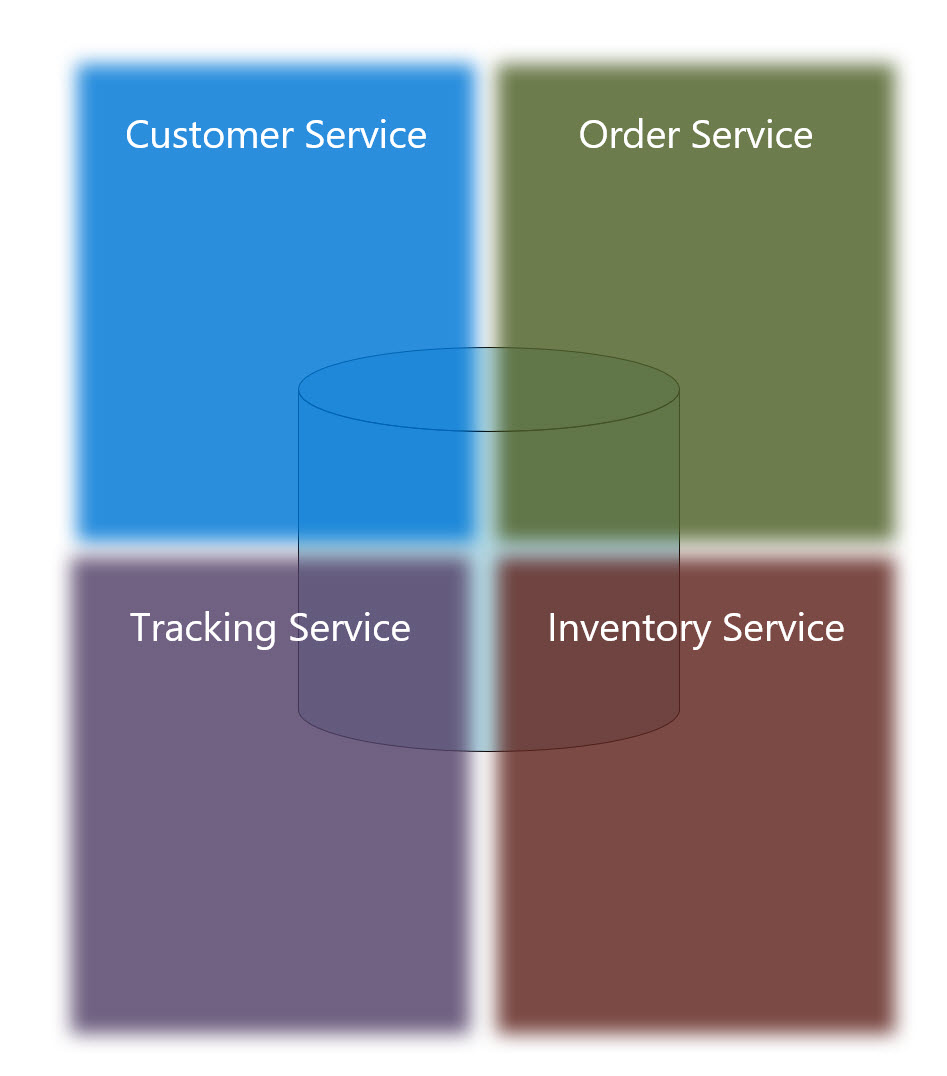
It is worth noting another approach that helps with the backup challenges of DR. This approach uses a single repository but isolates the data using schemas. The schema is not shared between microservices thus achieving isolated data. This does limit the independence of the teams as there becomes shared constraints (e.g., database version and type) so this is not a strict adherence to the principles of microservices but still worth mentioning. The following illustrates this idea:
Geographically dispersed solutions and High Availability
Latency is introduced with calls across service boundaries. In some scenarios the introduced latency is not detrimental to the performance of the solution but in other scenarios, especially very chatty (high level of interdependence between services) and/or geographically dispersed solutions, the introduced latency can have a large affect on performance. Take the following example showing a microservice that makes two calls to another microservice thus adding an additional 100ms of messaging latency.
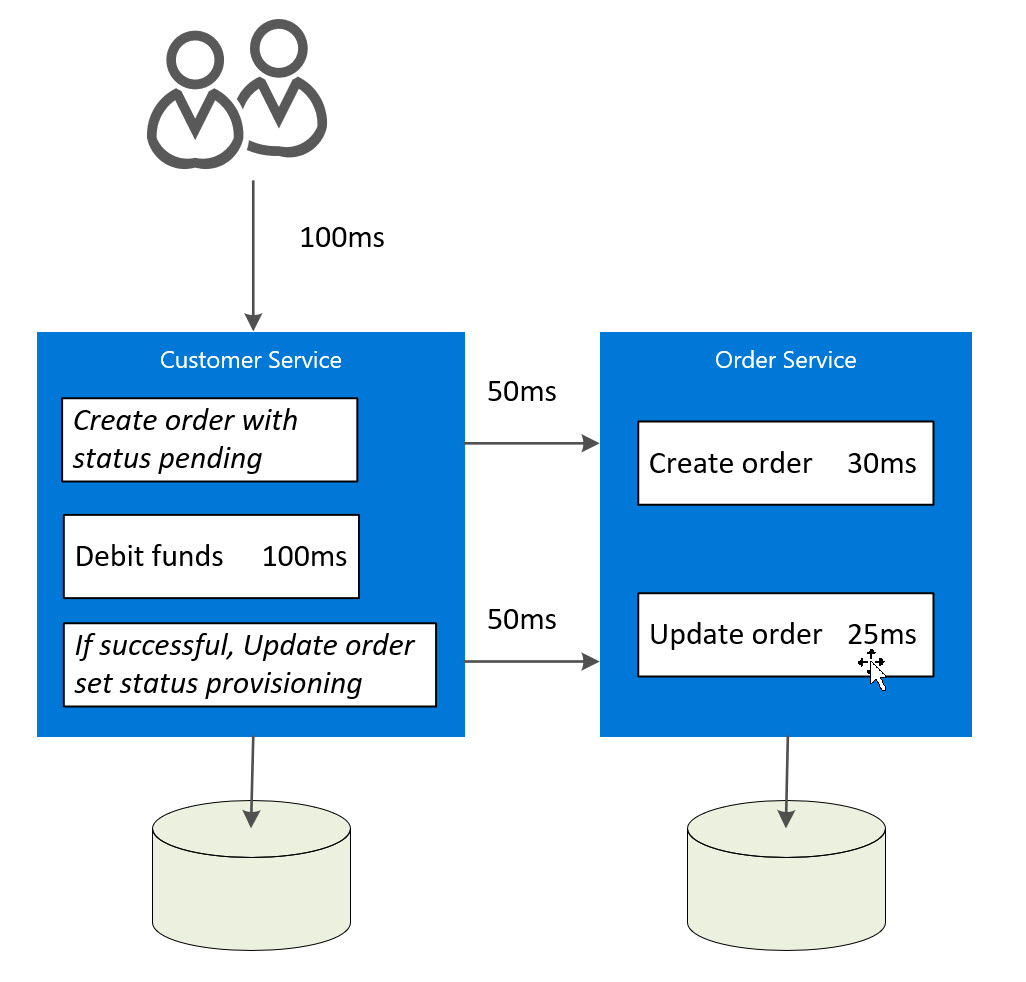
Ignoring the obvious argument that the service would be more suitable for asynchronous processing, this illustrates how a service could evolve to be very slow as additional interdependence with other microservices is added.
Data Compliance
Another important consideration when designing microservices is data compliance which requires systems to have a defined level of control over held data as well trace ability of held data and a requirement to provide held data when requested. With GDPR for example, an individual has the right to obtain personal data help about them. With highly dispersed repositories, obtaining a consolidated view of a data entity becomes more complex. Auditing to show compliance also becomes more complex as each repository and underlying technology will need to be individually assessed. For example, an enterprise system might have DocumentDB, Azure SQL and Azure Storage and with higher levels of trace-ability, the management of these resources cannot be left as a second thought but must be incorporated into the design.
An excellent way to help manage the complexity of data compliance is to start with the Microsoft Trust Center. With white papers, best practice guidance and checklists, there is a wealth of resources to help organizations understand and comply with regulations.
Background
As with other architectural styles, there are good and bad implementations as well as a wide range of interpretation of the architectural principles defining a particular style. Microservices is not an exception to this and often good and bad design decisions are only known in hindsight. The Azure Development Community is comprised of a large number of MVPs, Partners and seasoned architects, designers and developers. With such a wide breadth of scope for the AzureDev Community (anything and everything related to Azure) and a wide range of background among the team, opportunities arise to leverage the experiences of the team. This post is a result of a conversation I had with Marcin Kosieradzki who has been involved in building a sophisticated global solution using Service Fabric.
In the conversation, Marcin felt modern service design was more centered around building fine grained services and not about splitting services by business domains. He felt instead splitting by service type and tenant or partition made more sense. This approach combined with stateful services, for example using Azure Service Fabric, provides many benefits to both scalability, resilience and disaster recovery. By scaling vertically (by tenants) instead of horizontally (by teams, this would allow for services to both be geographically located closer as well as scaled to fit each tenant appropriately. Stateful services also provide a high degree of resilience while still benefiting from the simplicity of a single physical repository.
Of course he is right. And so is Garuav in his post Why a developer should build a solution with microservices. They are both right because so much depends on the requirements to be solved, the structure of the enterprise owning the solution and the context or domain of the solution. An internal employee management system has very different requirements than a global sales management system. Likewise a software development company with a mature software delivery process has different skills and development agility than an organization where software development is considered more of a business overhead.
An important thing to consider when choosing architecture is what benefits are trying to be gained. If the development teams are fragmented and geographically dispersed and project delivery is failing because of merge conflicts due to poor coordination between the teams then maybe microservices could help by reducing the interdependence between the teams. For situations were there are long running workflows or batch operations then a Web-Queue-Worker architecture might be more suitable.
Resources
Though the focus is Service Fabric, check out the Hyper-Scale Web section: Service Fabric Patterns and Practices Discussion between Vaclav Turecek and Jeffrey Richter