CQRS in Azure - Part 3
In CQRS in Azure Part 1, CQRS was defined and context was provided to explain why the pattern is relevant to building solutions in Azure. CQRS in Azure - Part 2 and this post illustrates the pattern by using a fictitious inventory system in order expand on the advantages while providing potential strategies for addressing the challenges that arise when moving away from the traditional monolith solution.
A sample project illustrating some of the approaches described is available on MSDN Samples: CQRS in Azure.
The Old Pie Shoppe
In the previous post, two challenges of building the dashboard were explored: adoption of new patterns and staleness of data in the presentation. The adoption of a new pattern can often be a challenge when the new approach involves more effort and/or the benefits are not easily recognized. Pushing back on change can be a good thing in terms of managing budget and delivery, and unfortunately, there is no silver bullet for solving this challenge. The second challenge is a challenge that exists in all solutions where data may change after it has been delivered to the presentation layer.
This post will look at the challenge of keeping the state in the application tier matching the state in the repository. When application tier cache is introduced into a solution, reads from the cache and subsequent writes might not accurately reflect the state in the back-end repository (e.g., database, file storage, DocumentDB, etc.). The goal is the strive towards consistency while not sacrificing on performance. As a reminder, the following is a simple illustration showing where inconsistent reads/writes might occur:
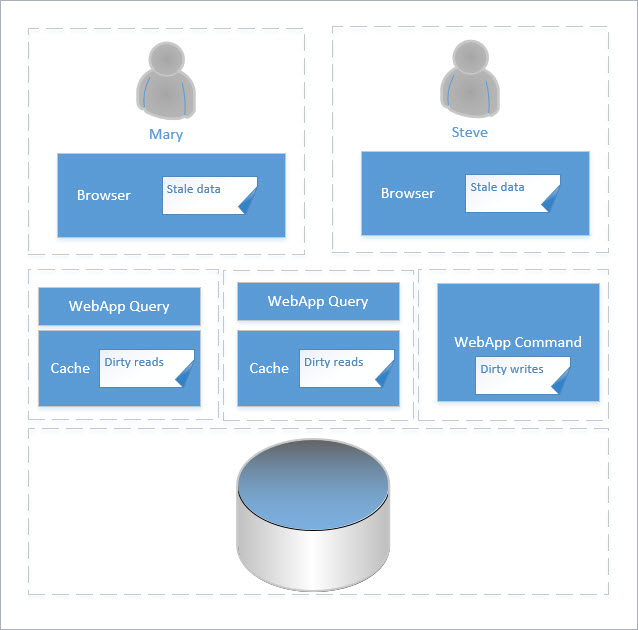
Where is the cache?
In the context of this post, an application-level cache is a software component that stores model state so that it can be delivered faster than a repository read. There is a huge range of possible implementations here from isolated in-memory cache to a distributed cache service to third party components like Azure Redis Cache. The principle is the same though, the cache needs to be updated to reflect the latest state.
Eventually Consistency
Simply put: eventually the state in the solution will become consistent. In the Old Pie Shoppe example, this means the state in cache, the client browsers and in the database will after a period of time all reflect the same data. Typically there is a trade off here between performance and availability and consistency. At an extreme, in order to guarantee the state in the client matches the database, a lock would have to be placed preventing the state in the database from being altered. Obviously impracticable in most solutions so the strive for consistency is tempered with the strive towards a scalable high-performing solution.
Challenge 3: Read Consistency
When caching is implemented between the client and state repositories, read consistency becomes an important factor. Some technologies provide their own mechanisms for handling this, for example DocumentDB, but in the case of the Old Pie Shoppe, a custom approach is required.
Note: for the purpose of this post, database level read consistency is at a lower level and is not discussed. This is primarily to maintain a higher level of abstraction in order to keep the scope of the post smaller. 
Service Bus
In the early days of SOA, the Enterprise Service Bus (ESB) gained considerable popularity and for good reasons. There are many definitions of an ESB and often the definition is skewed depending on the implementation and/or vendor. An ESB does not have to be the centralized inflexible hub that the term often evokes. The purpose of the diagram below is to illustrate how the command notifies interested applications indirectly through the service bus. This gives a number of advantages of direct integration and allows for patterns to be implemented like publish/subscribe, store and forward, as well as optimization like batching and scheduling.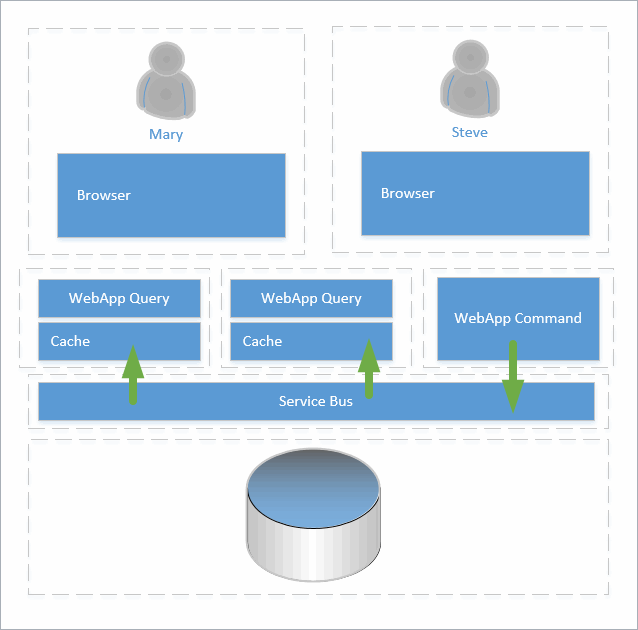
SQL Dependency Notifications
SQL Server Service Broker supports messaging and queuing within the SQL Server Database Engine. For supported versions of SQL Server, a SQL Dependency can be created to report back when the state changes. For more information about notifications, see Planning for Notifications which includes determining the suitability of notifiations and guidance on planning a query notification strategy.Polling
Similar to refreshing the state in the browser, the application will periodically poll the repository for changes. Though a simple approach, the challenge is determining both the granularity and frequency of the polling especially as the application scales.
Note: the Old Pie Shoppe example project uses both SQL Dependency and Polling depending if the database version is SQL Azure or not. For more detail, please see the Technet Wiki article: SQL Server Notifications - Polling and ServiceBroker.
Challenge 4: Write Consistency
Write consistency poses a challenge for many reasons but most significant is guaranteeing the state of the database does not become corrupt and the intent of the change reflects the intent of the action submitted. In the Old Pie Shoppe, this means if we add 10 objects, we expect the state of the model to be changed to reflect 10 more objects. Likewise, it would be considered an invalid state if the inventory of a item drops below 0.
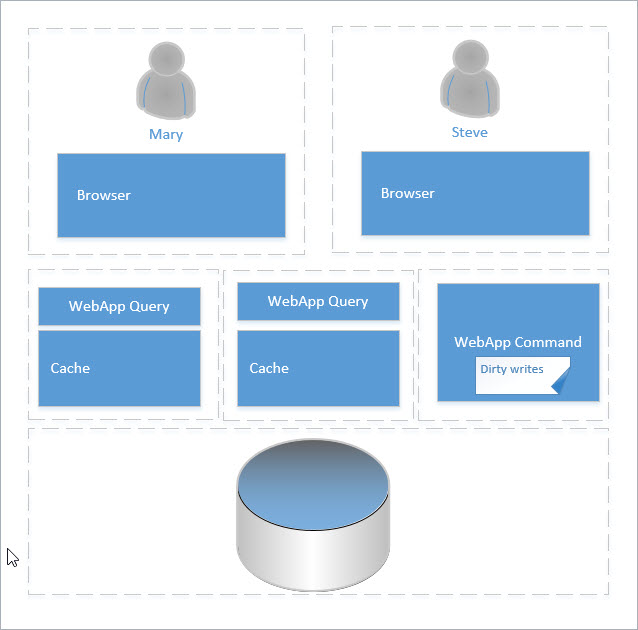
- Locking
A software lock will prevent changes to the state while the action is being performed. Where the lock is applied and how the action is applied depends largely on the scenario. For example, if the intent is to add 4 to the quantity of an object, then the lock would be applied on the object, the quantity read and increased by four, the object would be saved and the lock released. But, if the intent is to set the object's quantity to 12 then the object could be updated without having to read the latest quantity first. Another important consideration is where the lock should be applied. In general, the closer to the object the lock is applied and the more precise the lock is, the less chance the lock will block another action. For example, a database level lock on the quantity of an object would be preferable to a lock originating in the application-tier and encompassing the entire object. - Ledger
Insert Only database design is popular in financial solutions as it provides a solid basis for auditing and history by preventing update or delete operations. The state of a repository is therefore the aggregation of all rows. Of course, the downside is a full read of a table is required to determine the final state. Persistent views, additional tables and/or an application-tier cache can be used to mitigate the overhead of a full read.
Note: the Old Pie Shoppe example project uses an insert only table to maintain the inventory and includes a table constraint to enforce the quantity never dropping below 0.
Old Pie Shoppe - UpdateInventory service?
The UpdateInventory was constructed to illustrate a couple points regarding service design.
- Granularity
The service only adds or removes from the quantity of a specific ingredient in a specific inventory. In hindsight, the service should have been called UpdateInventoryEntry or simply InventoryEntry that only accepts POST operations. - Business Driven
The service was created in response to providing a specific business capability.
As an contrary illustration, the same functionality could have been provided as a composite service that provided the ability to update both the current quantity, the last time the inventory was cleaned and the date of the last inspection. This approach was popular in early days of SOA: the one stop shop service ( 😄 ). This approach initially sounds like a good idea as it is only requires a single code-base and deployment is simpler as there is only one service but it then couples the different capabilities together requiring them to be maintained and scaled as a single unit. A more subtle reason is what do you do when you only want to update the quantity and nothing else? What if only the quantity to be updated is known?
Note: the Old Pie Shoppe example project uses an Azure Function as a serverless microservice. For more details see the TechNet Wiki article: Azure Functions - Entity Framework.
Summary
The Old Pie Shoppe was a simple solution engineered to provide context to the Command Query Responsibility Segregation pattern. Of course CQRS is just a term so emphasis should not be on the term but why the pattern is being mentioned in the context of Azure and enterprise solutions. Arguably cloud solutions provide greater flexibility in being able to leverage different technology and components to solve business needs. As it becomes more common to combine relational databases, no-sql repositories, large object storage (Blob) into a single cohesive solution, techniques and patterns are required to help manage the collective state of a solution.
So, back to the Old Pie Shoppe example project. The example provides polling between the client browser and application in order to minimize the client's view of the state from becoming stale. SQL Server notifications are used to push changes to the repository to the application state.
This is illustrated below:

Click to animate!
Thoughts, comments, alternatives not provided; please comment below. Cheers!
For a recap of the benefits and links to additional CQRS related posts, please see CQRS in Azure - Part 4.