The Data Science Process with Azure Machine Learning
It’s no secret today that all our applications and devices are generating tons of data; thus making data analytics a very hot topic these days and Microsoft Azure has all the tools necessary to ingest, manage and process all these data, also called Big Data.
However, all these data in itself is not useful unless processed, interpreted and visualized correctly. Another power behind the data acquired through years is to make Predictive Analytics. That is, using the data to make forecast and predictions.
But, by only using the data gathered, it is difficult to make analysis. To use the data, it needs to be cleansed, transformed and processed to a format that we can use to build Predictive Models. This process is called the Data Science Process.
The Data Science Process
Before the “Buzz Words”, the Cross Industry Standard Process for Data Mining presented a a data mining process model that describes commonly used approaches that data mining experts use to tackle problems.
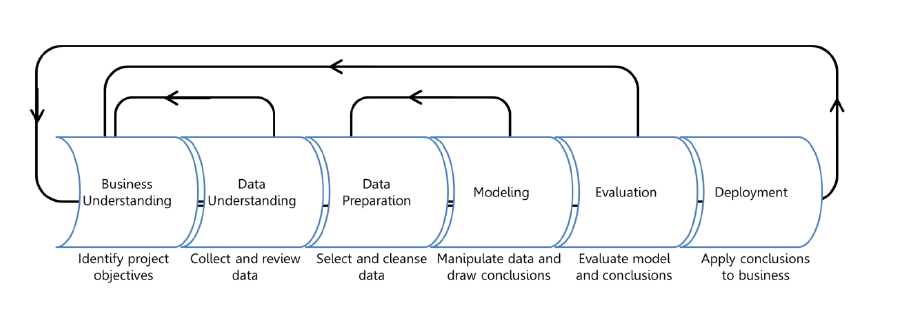
As you can see in the illustration above, the model proposed consisted of not only technical steps but also focused on understanding the business process and applications before going to the data preparation, modelling and evaluation steps.
What I like with what they proposed back then is the iterative approach. When you build a predictive model, you never get it right at once. It involves changing lots of parameters and the data till you reach a certain level of accuracy, precision and consistency of the results.
To perform the steps above, let’s use the Machine Learning studio on Microsoft Azure to see how we can use Predictive Analytics.
In the example below, we shall use the German Credit Data available as part of the samples on Azure Machine Learning Studio.
This data set contains 1000 samples with 20 features and 1 label. Each sample represents a person. The 20 features include both numerical and categorical features. The last column is the label, which denotes the credit risk and has only two possible values: high credit risk = 2, and low credit risk = 1.
Business & Data Understanding
Let’s start by understanding the business and data. The first step is to read about the information available on the data set itself which is available here. Next, we can use some of the tools available on the studio to describe and view the statistics about the data.
You can either right-click on the data set to visualize the contents, use the summarize data module or write custom R/Python scripts.
The easiest way to view the data is to right-click on the data set and click on visualize.
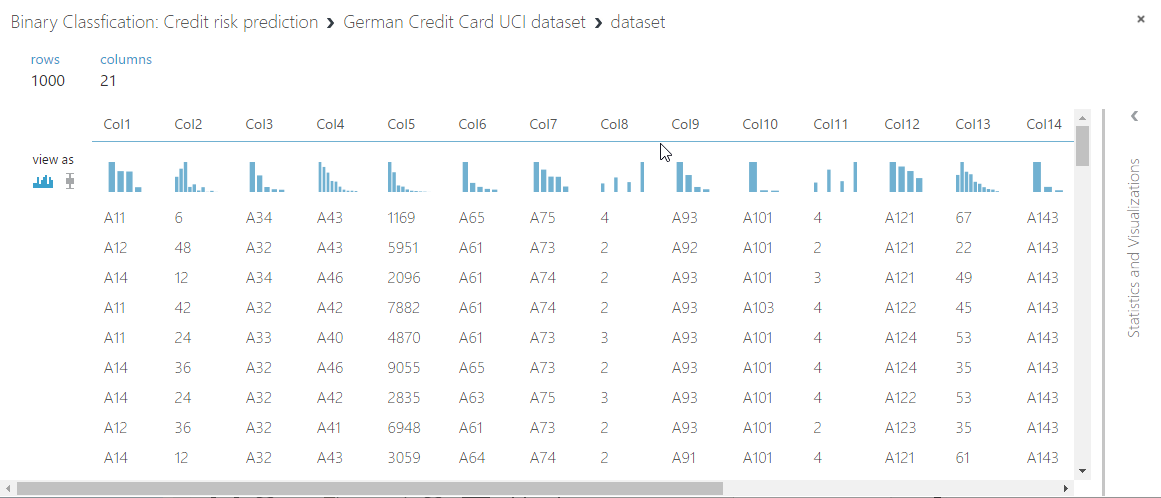
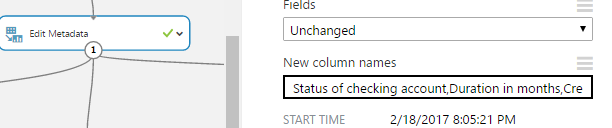
The first thing you’ll notice is that we have no headers on the columns. To understand the data easier, we can use the edit Meta data editor component to give proper names to the columns.
By using the summarize data module, you can in one glance view the count, missing data, min, max and other statistics about each feature in the data set.
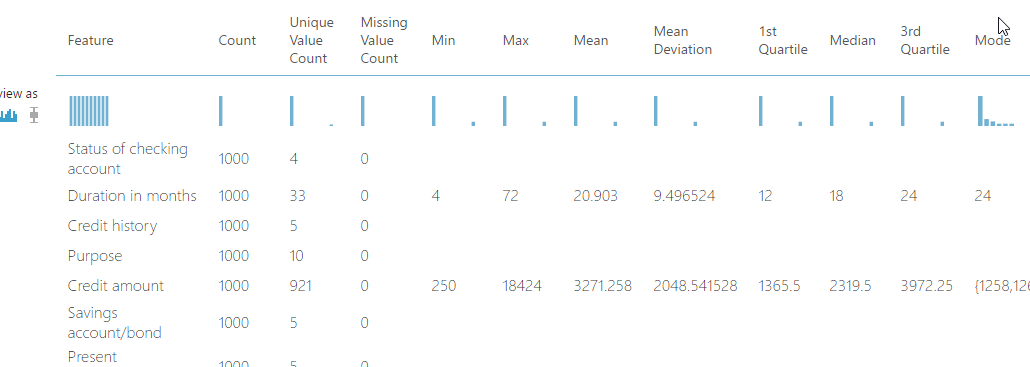
Another important point to this problem is the cost of predicting a bad loan as a good one. (The cost of obtaining a false positive versus a false negative). You will agree that it’s more costly to an institution to predict a bad loan as good than vice versa. To do so, it might be wiser to make the model learn from more records of bad loans than good ones. But this remains a business decision!
Data Preparation
Now it’s time to prepare and cleanse the data. This is where most of your time will be spent! Azure Machine Learning has several tools for Manipulation, Filtering, Sampling and Scaling data built in for data transformation.
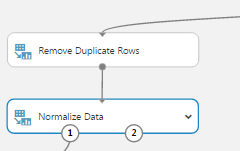
We can therefore continue to build our experiment by easily removing duplicate rows and normalizing the integer values.
The input data set might contain one column with values ranging from 0 to 1, and another column with values ranging from 10,000 to 100,000. The great difference in the scale of the numbers can cause problems when you attempt to combine the values as features during modeling.
Normalization helps you avoid these problem, by transforming the values so that they maintain their general distribution and ratios, yet conform to a common scale. For example, you might change all values to a 0-1 scale, or transform the values by representing them as percentile ranks rather than absolute values.
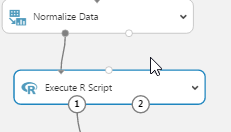
Moreover, if you still need to do more custom transformation, you may use the Apply SQL, Execute R or Execute Python tools to run your own scripts.
In our example, let’s add a small piece of R code to scale the data set and generate more rows containing bad loans (true negative).
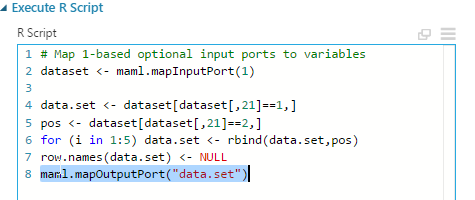
Modelling
Now, it’s the fun time. This is where the magic happens! Azure Machine Learning caters for all the main models and provide industry tested built-in algorithms to create predictive models. The main models are:
- Classification: To find answers to Yes/No questions
- Regression: To predict a numerical value
- Clustering: To group observation into similar looking groups
- Recommendation System: To recommend someone an item.
Before proceeding with the predictive models, we first need to split the data into 2 parts, the train and the test data. The train data will be used for learning by the algorithm and the test data will be used to evaluate is the forecast made by the model using the train accurate. The objective is to avoid using the same data for learning and scoring.
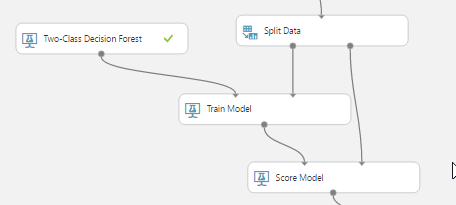
In our example, since we are predicting a Yes/No (classification) problem, we are using a Two-Class decision forest algorithm. We then connect the train data and the algorithm to the train model and this is where learning will occur.
Evaluation
The next step is to connect the test data and the output of the train model to the Score Model. As mentioned above, the score model will compare the data from the test data set versus the data predicted by the train model. It outputs a predicted value for the class, as well as the probability of the predicted value.
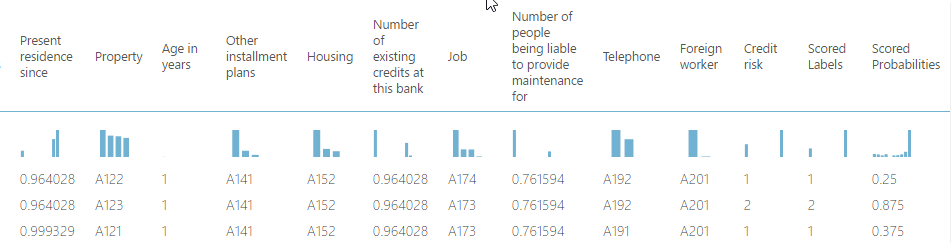
For a more comprehensive evaluation of all the results scored, the evaluate model can be used. It measures the accuracy of a trained classification model or regression model. You provide a data set containing scores generated from a trained model, and the Evaluate Model module computes a set of industry-standard evaluation metrics.
Let’s now connect the output of the Score Model to the Evaluate component.

The metrics generated in our case, for a classification model is as follows:
- Accuracy measures the goodness of a classification model as the proportion of true results to total cases.
- Precision is the proportion of true results over all positive results.
- Recall is the fraction of all correct results returned by the model.
- F-score is computed as the weighted average of precision and recall between 0 and 1, where the ideal F-score value is 1.
- AUC measures the area under the curve plotted with true positives on the y axis and false positives on the x axis. This metric is useful because it provides a single number that lets you compare models of different types.
- Average log loss is a single score used to express the penalty for wrong results. It is calculated as the difference between two probability distributions – the true one, and the one in the model.
- Training log loss is a single score that represents the advantage of the classifier over a random prediction.
Deployment
Now that we have trained our model, it’s time to deploy is and expose it to applications. In Azure Machine Learning, it’s very easy to deploy a predictive model. You just need to click on setup web service, select the web service inputs/outputs and hit deploy!
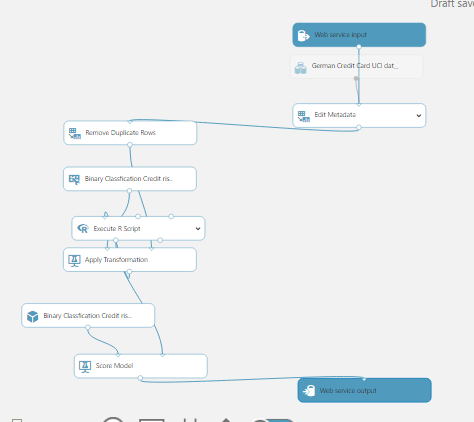
In this blog post, we discussed how to apply the data science process and using a predictive model using Azure Machine Learning. In the next blog post, I’ll explain in more details about each step in the process to optimize the model for more accurate forecasting.
References