Build hybrid cloud analytics solutions with ADLA Task in SSIS
Today, we are pleased to announce new support for the Azure Data Lake Analytics Task (ADLA Task) in the Azure Feature Pack for Integration Services (SSIS). The ADLA Task enables you to easily extend your existing SSIS workflows with big data compute capability in the cloud powered by ADLA.
More and more customers are storing large amounts of raw data in the cloud. At the same time, some customers continue to process the data on-premises due to legacy or security constraints. Since the movement of big data is very costly, it is a good choice to transform the born-in-the-cloud big data into reasonable size in the cloud, and then only move aggregated data off the cloud and integrate it with existing on-premises data sources.
The rest of this blog shows how you can build hybrid cloud analytics solutions with ADLA Task in Azure Feature Pack.
Extending SSIS with big data capability using ADLA
With ADLA Task in Azure Feature Pack, you can now orchestrate and create U-SQL jobs as a part of the SSIS workflow to process big data in the cloud. As ADLA is a serverless analytics service, you don’t need to worry about cluster creation and initialization, all you need is an ADLA account to start your analytics.
You can get the U-SQL script from different places by using SSIS built-in functions. You can:
- Edit the inline U-SQL script in ADLA Task to call table valued functions and stored procedures in your U-SQL databases.
- Use the U-SQL files stored in ADLS or Azure Blob Storage by leveraging Azure Data Lake Store File System Task and Azure Blob Download Task.
- Use the U-SQL files from local file directly using SSIS File Connection Manager.
- Use an SSIS variable that contains the U-SQL statements. You can also use SSIS expression to generate the U-SQL statements dynamically.
These options enable flexibility for your job. Learn more about how to set up these user cases in this document. 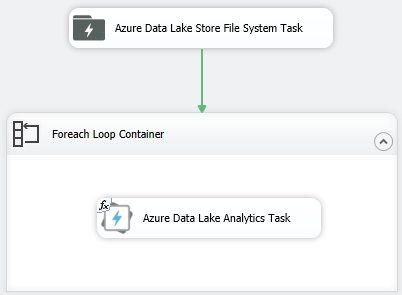
Using SSIS to move cloud compute results back to on-premises
After transforming big data using ADLA, you can then move the processed data back to on-premises for reporting and additional processing. You can use Foreach Loop Container (with Foreach ADLS File Enumerator or Foreach Azure Blob Enumerator) and run Data Flow tasks to copy data from cloud to on-premises databases.
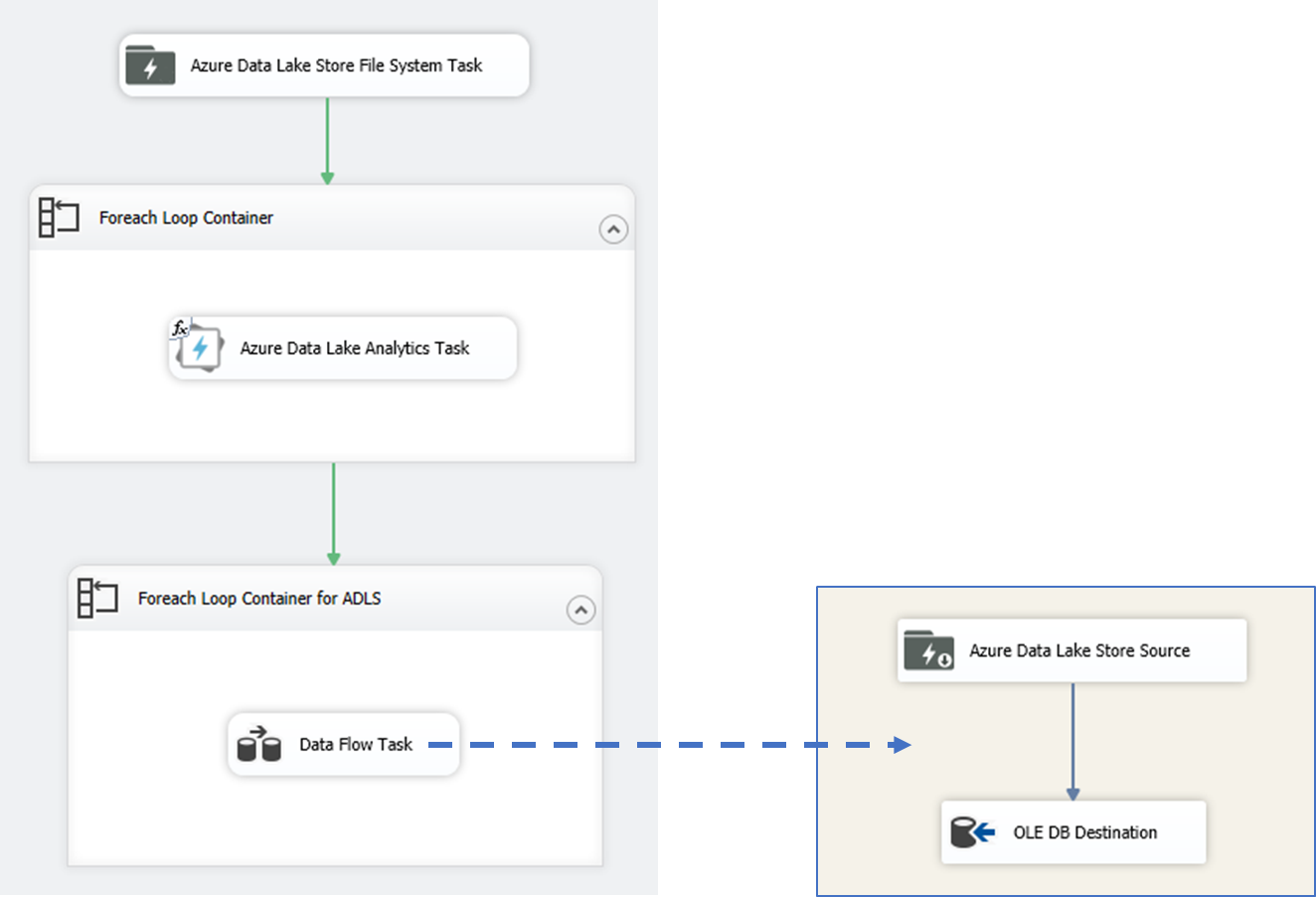
Try it yourself
To build and run the scenarios by yourself, please refer to this document: Schedule U-SQL jobs using SQL Server Integration Services (SSIS). Contact us at adldevtool@microsoft.com for comments and feedback.