Hive Metastore in HDInsight –Tips, Tricks & Best Practices
When you create a Hive table, the table definition (column names, data types, comments, etc.) are stored in the Hive Metastore. Hive Metastore is critical part of Hadoop architecture as it acts as a central schema repository which can be used by other access tools like Spark, Interactive Hive (LLAP), Presto, Pig and many other Big Data engines.
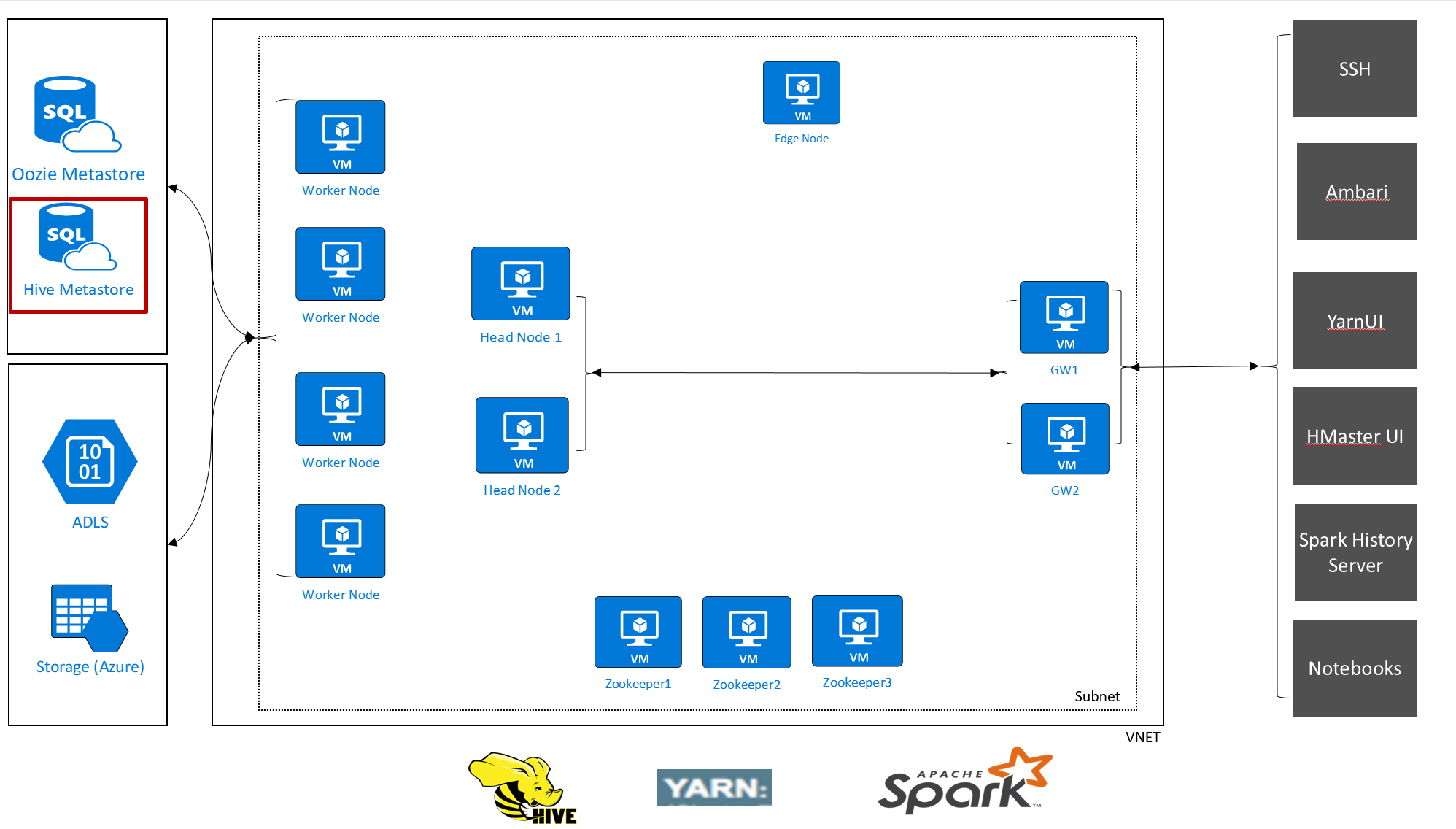
Image – HDInsight Architecture and Hive Metastore
In HDInsight, we use Azure SQL database as Hive Metastore. Azure SQL DB is relational database-as-a-service (DBaaS) hosted in the Azure and give availability SLA of 99.99.
There are two ways you can setup Metastore for your HDInsight clusters
HDInsight default Metastore – If you don’t provide a custom Metastore option, HDInsight will provision
Metastore with every cluster type. Here are some key considerations with default Metastore
- No additional cost. HDInsight provisions Metastore with every cluster type without any additional cost to you.
- Default Metastore is tied to the cluster life, when you delete the cluster your Metastore and metadata is also deleted
- You cannot share the Default Metastore with additional clusters.
- The default Metastore use Basic Azure SQL DB which gives you 5 DTU [Database Transaction limit]
This is generally good option for relatively simple workload where you don’t have multiple clusters and don’t need metadata preserved beyond the life cycle of the cluster.
Custom Metastore – HDInsight lets you pick custom Metastore. It’s a recommended approach for production clusters due to number reasons such as
- You bring your own Azure SQL database as Metastore
- As lifecycle of Metastore is not tied to a cluster lifecycle, you can create and delete clusters without worrying about the metadata loss.
- Custom Metastore lets you attach multiple clusters and cluster types to same Metastore. Example – Single Metastore can be shared across Interactive Hive, Hive and Spark clusters in HDInsight
- You pay for the cost of Metastore (Azure SQL DB)
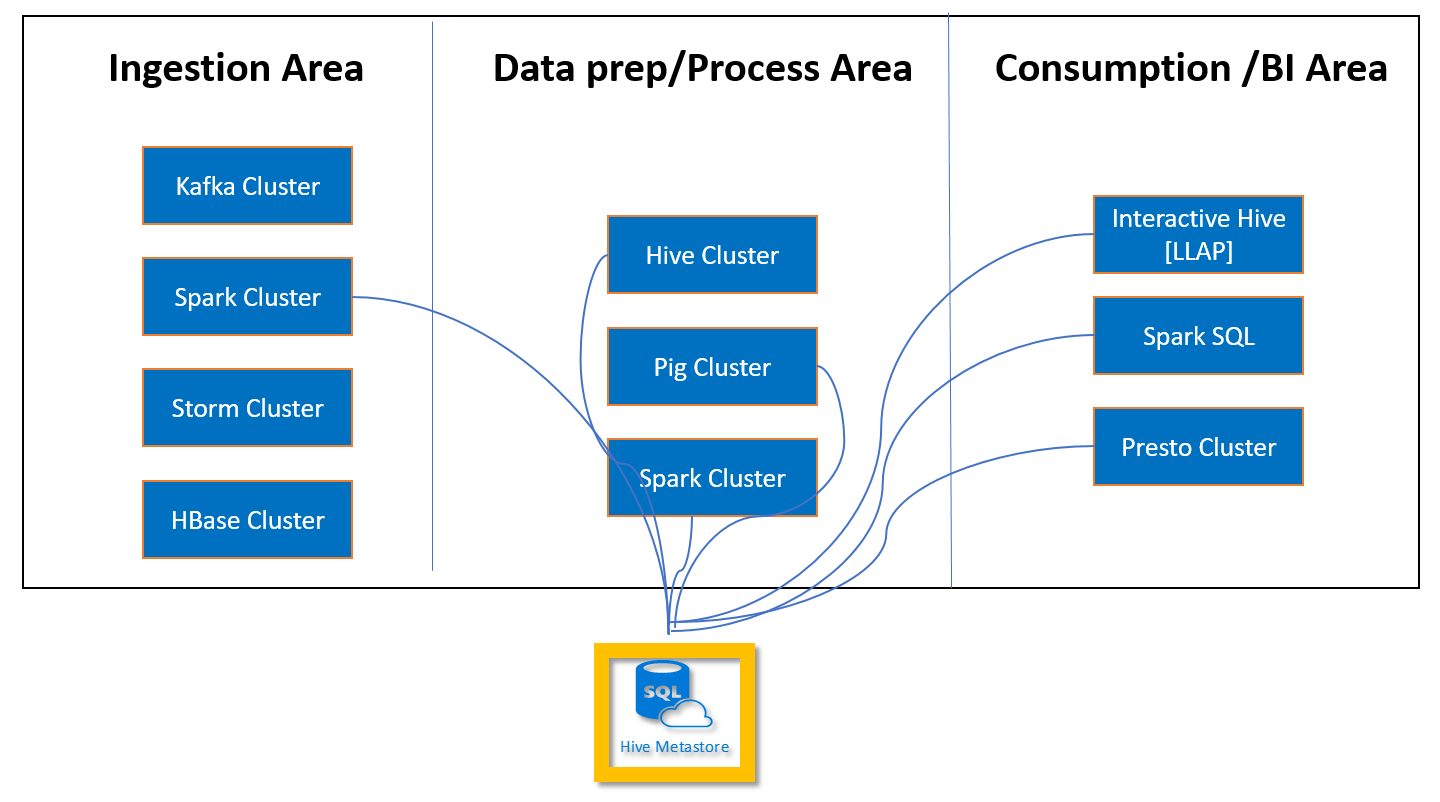
Image – Typical shared custom Metastore scenario in HDInsight
Here are general HDinsight Hive Metastore best practices that you should consider
- Use custom Metastore whenever possible, this will help you separate Compute and Metadata
- Start with S2 tier which will give you 50 DTU and 250 GB of storage, you can always scale the database up in case you see bottlenecks
- Ensure that the Metastore created for one HDInsight cluster version is not shared across different HDInsight cluster versions. This is due to different Hive versions has different schemas. Example - Hive 1.2 and Hive 2.1 clusters trying to use same Metastore.
- Back-up your custom Metastore periodically for OOPS recovery and DR needs
- Keep Metastore and HDInsight cluster in same region
- Monitor your Metastore for performance and availability with Azure SQL DB Monitoring tools [Azure Portal , Azure Log Analytics]
How to select a custom Metastore during cluster creation?
You can easily point your cluster to a pre-created Azure SQL DB during cluster creation as well as after cluster is created. The option is under storage --> Metastore settings while creating a new Hadoop , Spark or Intractive Hive cluster from Azure portal
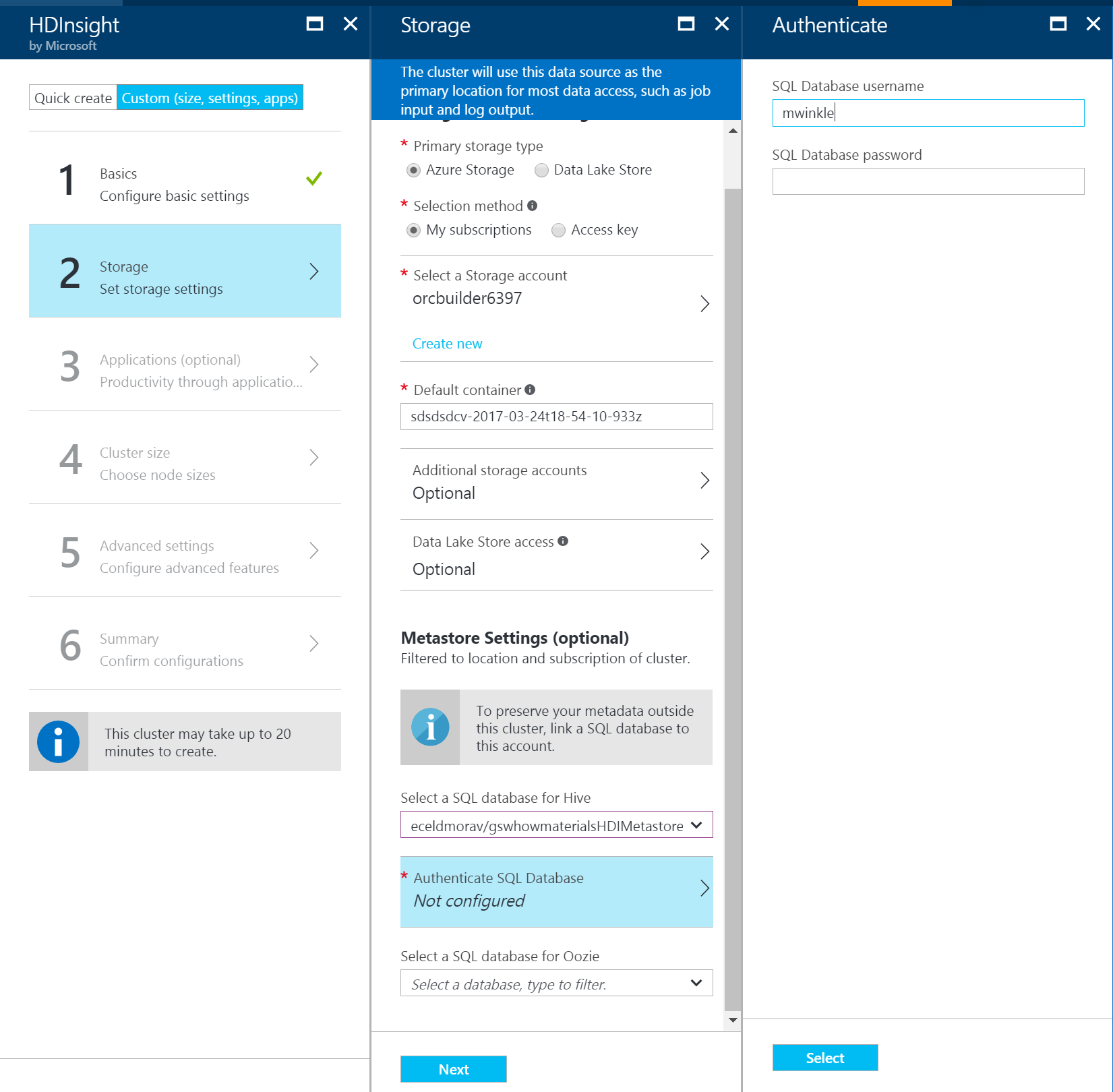
Additionally, You can add additional clusters to the Custom Metastore for Azure Portal as well as from Ambari configurations ( Hive -->Advanced)
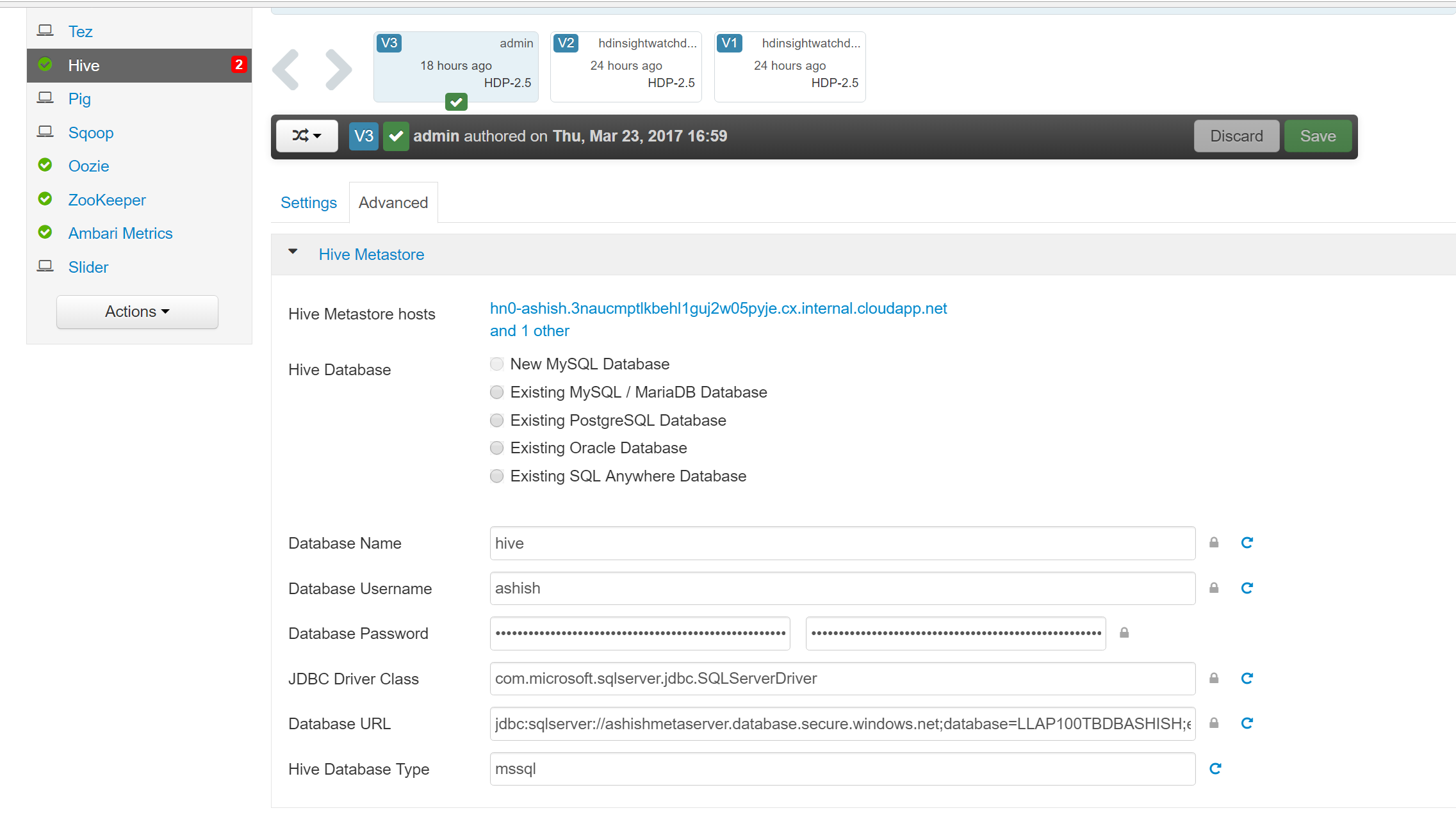
As discussed above Hive Metastore is critical component of Hadoop and Spark architecture and picking up right Metastore strategy will certainly help you with right Architecture and user experience.
Don't have HDInsight cluster ? deploy now. 