Introducing: Interactive Hive cluster using LLAP (Long Live and Process)
Earlier in the Fall, we announced the public preview of Hive LLAP (Long Live and Process) in the Azure HDInsight service. LLAP is a new feature in Hive 2.0 allowing in-memory caching making Hive queries much more interactive and faster. This makes HDInsight one of the world’s most performant, flexible and open Big Data solution on the cloud with in-memory caches (using Hive and Spark) and advanced analytics through deep integration with R Services.
Enabling faster time to insights
One of the key reasons that Hadoop has been popular in the marketplace has been the promise of being self-serve as well as faster time to insights since developers and data scientists can directly query the log file and gain valuable insights. However, typically data scientists like to use interactive tools and BI applications which require interactive responses. Today most of Hadoop customers use a primitive approach of moving data from a Hadoop cluster to a relational database for interactive querying. This introduces large latency as well as additional cost for management and maintenance of multiple analytic solutions. Further, this limits the true promise of unlimited scale as that promised by Hadoop.
With LLAP, we allow data scientists to query data interactively in the same storage location where data is prepared. This means that customers do not have to move their data from a Hadoop cluster to another analytic engine for data warehousing scenarios. Using ORC file format, queries can use advanced joins, aggregations and other advanced Hive optimizations against the same data that was created in the data preparation phase.
In addition, LLAP can also cache this data in its containers so that future queries can be queried from in-memory rather than from on-disk. Using caching brings Hadoop closer to other in-memory analytic engines and opens Hadoop up to many new scenarios where interactive is a must like BI reporting and data analysis.
Making Hive up to 25x faster
LLAP on Hive brings many enhancements to the Hive execution engine like Smarter Map Joins, Better MapJoin vectorization, a fully vectorized pipeline and a smarter CBO. Other than these LLAP enhancements, Hive in HDInsight 3.5 (Hive 2.1) also comes with many other query enhancements like faster type conversions, dynamic partitioning optimizations as well vectorization support for text files. Together, these enhancements have brought a speed up of over 25x when comparing LLAP to Hive on Tez.
Hortonworks ran a TPC-DS based benchmark on 15 queries using the hive-testbench repository. The queries were adapated to Hive-SQL but were not modified in any other way. Based on the 15 queries they ran using 10 powerful VMs with a 1 TB dataset, they observed the following latencies across three runs:
For more detailed analysis on this benchmarking as well as results, please refer to this post.
Allowing multiple users to run interactive queries simultaneously
As Hadoop users have pushed the boundaries of interactive query performance some challenges have emerged. One of the key challenges has been the coarse-grained resource-sharing model that Hadoop uses. This allows extremely high throughput on long-running batch jobs but struggles to scale down to interactive performance across a large number of active users.
LLAP solves this challenge by using its own resource management and pre-emption policies within the resources granted to it by YARN. Before LLAP, if a high-priority job appears, entire YARN containers would need to be pre-empted, potentially losing minutes or hours of work. Pre-emption in LLAP works at the “query fragment” level, i.e. less than a query, and means that fast queries can run even while long running queries run in the background. This allows LLAP to support much higher levels of concurrency than ever before possible on Hadoop, even when mixing quick and long-running queries.
Here is a benchmark from Hortonworks showing a 1TB dataset being analyzed by a mixture of interactive queries and longer-running analytical queries. This workload was scaled from 1 user all the way up to 32 users. Most importantly we see a graceful degradation in query time as the concurrency increases.
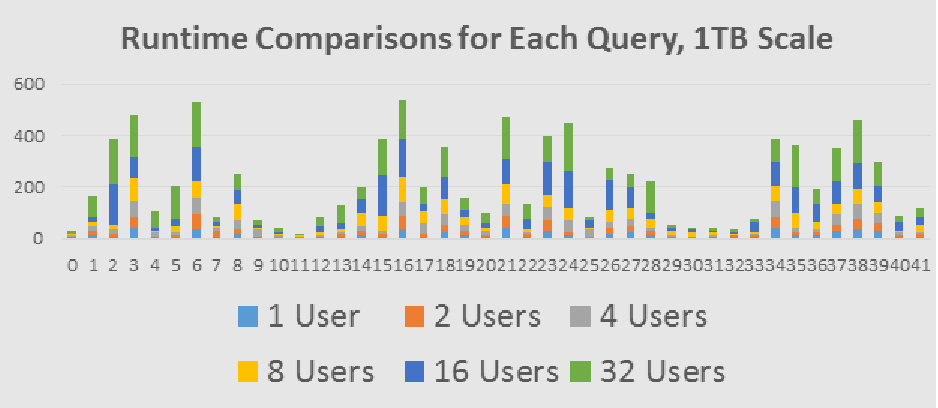
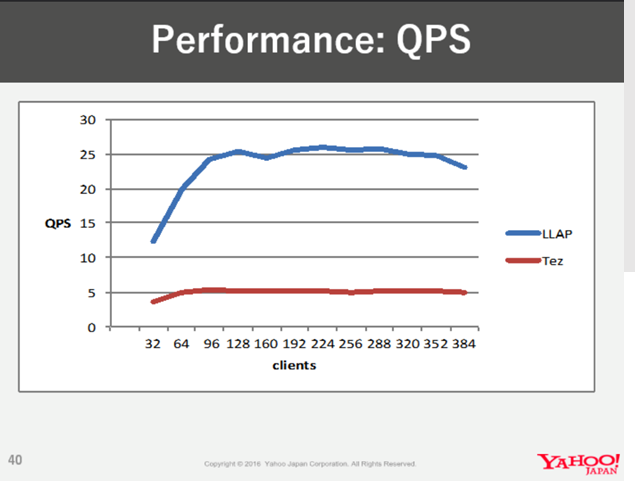
Yahoo! Japan recently showed at Hadoop Summit that they are able to achieve 100k queries per hour on Hive on Tez. They tested both concurrency and observed that they are able to run 100k queries per hour with QPS of 24 on a 70 node LLAP cluster. You can read more about it here.
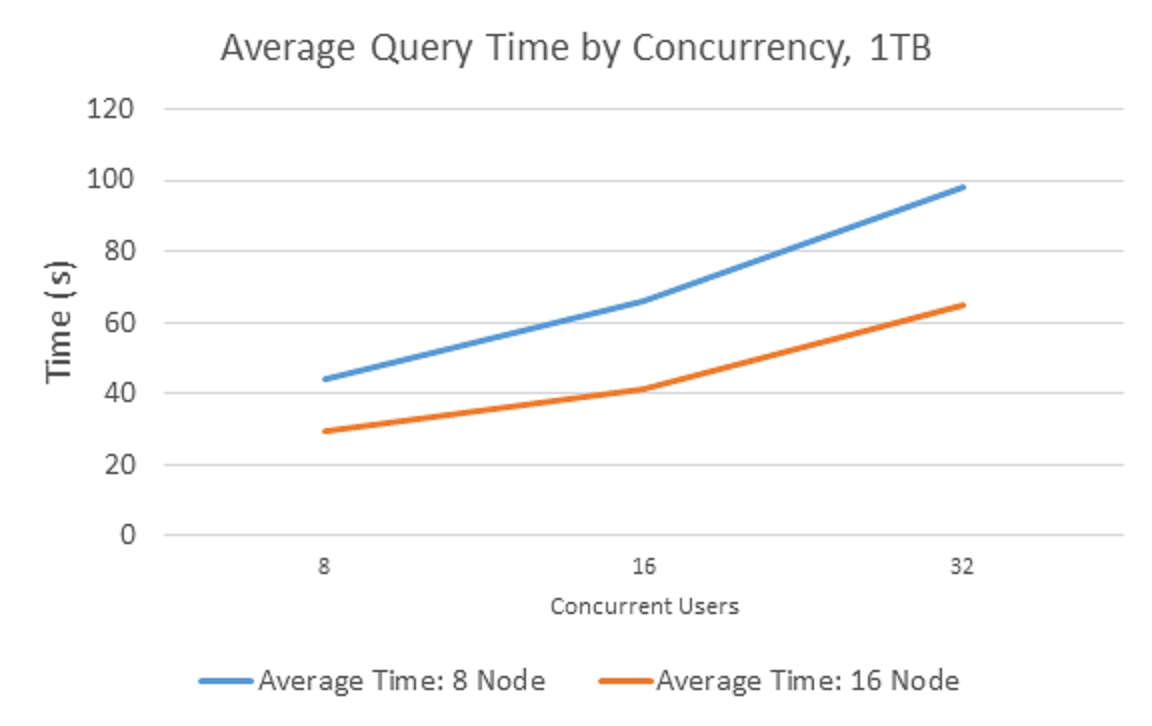
LLAP also delivers the typical Hadoop promise of linear scale. When this same benchmark is run using 8 nodes versus 16 nodes we see good linear scaling as additional hardware is thrown at the problem. LLAP give us the ability scale out to meet SLAs, even as more and more users are added.
Providing enterprise class security over Big Data scenarios
In Azure HDInsight 3.5 we are also announcing the public preview of advanced security features for Enterprise customers. Specifically, the Ranger integration allows administrators to provide authorization and access controls. In addition, administrators can perform per user dynamic column masking by injective Hive UDFs that mask characters using hashing. Administrators can also perform dynamic row filtering based on the user policies set by them. Based on these security policies, customers are able to match the enterprise class security as that provided by other Data Warehouses in the industry.
Separation of capacity for Data Warehousing vs. ETL
One of the biggest pain points of customers using Hadoop on-premise is the need to scale out their cluster every so often due to either storage limitations or running out of compute resources.
On-premise customers use local cluster disk for storage and this limits the amount of data that can be stored in the cluster. Most of our customers envision a Data Lake strategy, i.e. store data now and perform analytics later. However, due to 3x replication as needed by Hadoop the cluster tends to keep running out of storage space. HDInsight has solved this problem by separating storage and compute. Customers can use Azure Data Lake Storage or Azure Blob Storage as their storage and expand storage independent of their compute usage.
With LLAP, customers can now also separate their compute. HDInsight is releasing Hive LLAP as a separate cluster type. This allows customers to have two separate cluster types – one each for data preparation and data warehousing. Both clusters are connected to the same storage account and metastore to enable data and metadata to be synchronized across them. Each cluster can scale based on its own capacity needs, ensuring that a production cluster is not affected by extra load from ad-hoc analytical queries and vice-versa.
Using world class BI tools over unstructured data
Hadoop promises insights over unstructured and semi-structured data. There are many native and third party SerDe’s available which allow Hive to interact with different kinds of data like JSON and XML. Using Hadoop customers are easily able to run analytic queries on the format data was written (like JSON/CSV/XML), rather than modeling it before ingestion.
In addition, Microsoft has partnered with Simba to bring an ODBC driver for Azure HDInsight that can be used with world class BI tools like PowerBI, Tableau and QlikView. Together, this allows data scientists to gain insights over unstructured and semi-structured data using their favorite tool of choice.