HDInsight HBase: 9 things you must do to get great HBase performance
HBase is a fantastic high end NoSql BigData machine that gives you many options to get great performance, there are no shortage of levers that you can't tweak to further optimize it. Below is the general list of impact-full considerations for great HBase performance in HDInsight
Don't have HDInsight HBase cluster yet ? don't worry
1. Pick appropriate VM's.
There is nothing worse then an under powered HBase so picking up appropriate sized VM's are critical for good performance , however one of the confusion is weather one should pick fewer larger VM's or more smaller VM's for region nodes?
In HDInsight HBase - default setting is to have single WAL (Write Ahead Log) per region server , with more WAL's you will have better performance from underline Azure storage. In our experience we have seen more number of region server's will almost always give you better write performance (as much as twice) .
In other words , if total region cores number is 16 , it will good to have 4 D3V2 (4 cores) machines then 2 D4V2 (8 cores)
Head Nodes
Ambari is the most heavy application that runs on headnode in HDInsight HBase. Usually smaller default headnodes are good for many applications, however if you have a cluster that is bigger then 8 nodes , pick a good D series VM (D3V2 or D4V2)
Region Server Nodes
D1-5 v2 instances are the latest generation of General Purpose Instances. D1-5 v2 instances are based on the 2.4 GHz Intel Xeon® E5-2673 v3 (Haswell) processor, and can achieve 3.1 GHz with Intel Turbo Boost Technology 2.0. D1-5 v2 instances offer a powerful combination of CPU, memory and local disk. For HBase - We recommend picking up D3v2 to D5V2 for decent size workloads
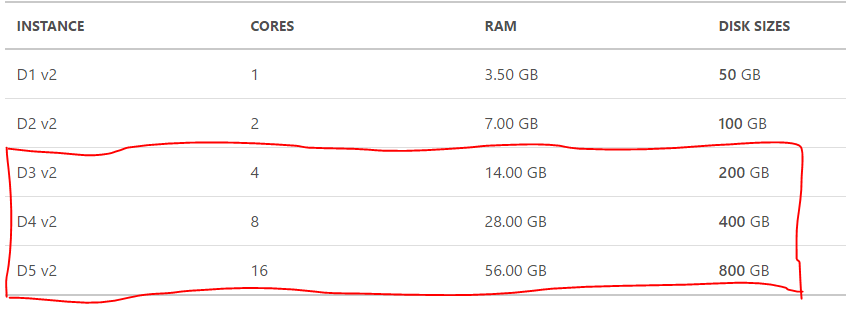
For higher performance you could pick between D13-15 v2 which will give you great HBase performance for more demanding workloads
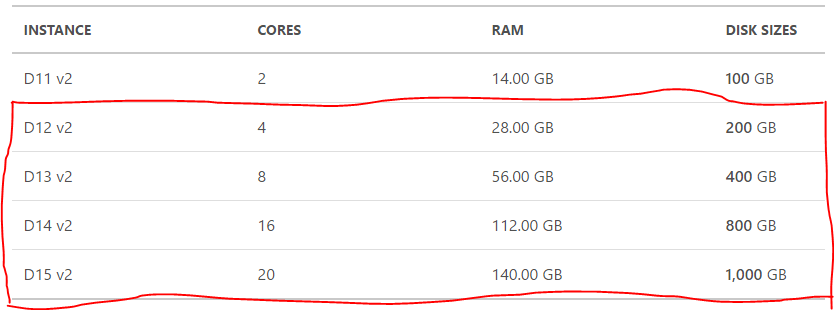
.D15 v2 instance is isolated to hardware dedicated to a single customer.
2. Incorrect Row Key design can really hurt
Does your RowKey’s looks like 1,2,3…….. or 00000001, 00000002, 00000003, or do you have Row Key that starts with date-time (starting with the year)? If you answered yes, bad news is that HBase will not scale for you, you have so many options to improve the HBase performance but there is nothing that will compensate for the bad rowkey design.
When rowkey is in sorted order, all the writes go to the same region and other regions will sit ideal doing nothing. you will see one of your node is very stressed trying to cope up with all the writes where as other nodes are thanking you for not giving them enough work. So, always salt your keys by adding random numbers or characters to the row key prefix.
If you are using Phoenix on top of HBase, Phoenix provides a way to transparently salt the row key with a salting byte for a particular table. You need to specify this in table creation time by specifying a table property “SALT_BUCKETS” typical practice is to set the value of SALT_BUCKET =number of region server
In case of HDInsight, we see some customers taking advantage of cloud elasticity and increasing /decreasing region nodes, for them our guidance is to pick a SALT_BUCKET number that will represent their peak region node count today or in the future, subject to a maximum limit of 256.
Important Note: One thing to keep in mind that you need to set the SALT_BUCKET parameter at table creation time, it’s not possible to alter the Phoenix table at later stage to set or reset this value.
Good HBase Table practices
- As discussed above, salt your keys to avoid hotspoting, draw the inspiration from successful HBase applications such as OpenTSDB and how they have designed their RowKeys https://opentsdb.net/docs/build/html/user_guide/backends/hbase.html
- Try to keep the ColumnFamily names as small as possible, preferably one character
- Keep RowKey as short as is reasonably possible such that they can still be useful for required data access
3.Drastically improve your write throughput by implementing batching
When you make a put call to HBase , it's a one RPC request , imagine you are inserting million’s of rows that will result in millions of RPC calls - with remote storage latencies your write performance will be sub-optimal.
Solution to this is batch puts, try to construct a list of puts and then call HTableInterface.put(List puts), it uses a single RPC call to commit the batch.
So the question becomes, how much big batch size? based on our testing larger batch size’s do very well with HBase but be careful of your client side memory that will be holding on to the batch while it’s filling up to specified batch size.
So, what be the ideal batch size? it depends on your application however batch size of 1-10 MB should do well with HBase , if you are pushing me for absolute precise number. I would say 4 MB.
When you implement batching , don't forget to increase number of connections to HBase. multiple connections will result in better performance.
4. Improve your Read Performance by enabling bucket caching
Azure VM’s have SSD’s that you could utilize to improve your read performance by enabling the bucket cache, we have this setting enabled on newer HBase cluster’s but if you have an older cluster and bucket cache is not turned on, you can turn it on from Ambari. If you are interested in how HBase cache works , follow the article here
5. Avoid major compaction at all cost
Compaction is the process by which HBase cleans up after itself.
There are two types of compactions in HBase: minor and major. Minor compactions will usually pick up a couple of the smaller StoreFiles(hFiles) and rewrite them as one. You can tune the number of HFiles to compact and the frequency of a minor compaction however it is set to a to optimized default value.
In HDInsight HBase and we don't recommend changing this value unless there is a good reason to do so. Major Compaction reads all the Store files for a Region and writes to a single Store file.
Minor compactions are good, major compactions are bad as they block writes to HBase Region while compaction is in process. In HDInsight we try to make sure that major compactions are never triggered. This is ensured with the fine tuning of many hbase properties including region split size , by default we spilt a region after it reaches 3 GB's.
sometime when multiple operations (such as a parallel map-reduce operation that is doing bulk load) can cause a situation resulting in major compaction, there by blocking the writes.
You need to monitor the cluster for such condition and take action if you hit into major compaction too often. Look out for “too many hFiles” in region server logs to identify this problem.
6. Presplit regions for instant great performance
Pre-splitting regions ensures that the initial load is more evenly distributed throughout the cluster, you should always consider using it if you know your key distribution beforehand.
There is no short answer for the optimal number of regions for a given load, but you can start with a lower multiple of the number of region servers as number of splits, then let automated splitting will you start to grow you data size
7. Do not use HBase storage account for anything else
As you may know, Azure storage has limits applied at storage account level so you don't want to share that limit with any other application that might be using the same storage account and eating out on HBase storage performance. So the golden rule is to keep a dedicated storage account for HBase
8. Avoid using HBase cluster for other hadoop applications
Although HDInsight HBase cluster comes with Hadoop applications such as hive, spark etc. Avoid running mixed workloads in HBase cluster. HBase is CPU and Memory intensive with sporadic large sequential I/O access, mixed workloads can lead to unpredictable latencies for HBase and CPU contentions.
9. Disable or Flush HBase tables before you delete the cluster
Do you often delete and recreate the clusters ? a great choice as you are taking full advantage for cloud elasticity. Your data is persisted in Azure Storage and you are bringing up clusters only when you need to read and write the data.
Problem comes when you try creating a large cluster from existing HBase storage as Write Ahead Log (WAL) needs be replayed on regions as data was not flushed from memory when you deleted the cluster[Data is in WAL but not in hFiles]. You can dramatically improve your cluster provisioning time if you disable or flush regions manually before you delete a cluster. if you choose to disable the table , don't forget to re-enable them when cluster comes up