Introducing Image Processing in U-SQL
Rukmani Gopalan - Senior Program Manager
Apostolos "Toli" Lerios - Entrepreneur in Residence and Principal Software Engineer
Introduction
It is my great pleasure to coauthor this blog with Apostolos “Toli” Lerios, an expert at image processing and a serial entrepreneur, he has founded multiple startups and also worked as an image architect at Facebook. If you have uploaded a photo on Facebook, you have executed Toli’s code. Operating on images is a complex process, and doing this at scale is even more challenging – our goal was to simplify this problem. What started as an animated discussion over coffee about complex image processing at scale took us down a very interesting journey of using U-SQL to make it easier for big data developers to perform complex code (like image processing) at scale by leveraging the SQL-like declarative syntax and rich extensibility provided by C#.
In this blog post, we are going to utilize this rich programmability model of U-SQL to process complex multimedia data, such as images. The motivation behind this is twofold:
- to leverage the Azure Data Lake Analytics (ADLA)'s scalability to accomplish image processing at scale,
- to co-analyze image and non-image data (e.g. a person’s photo, the photo’s metadata, and auxiliary information such as a person’s name and age) all using ADLA and without resorting to specialized image processing systems distinct from analytics systems.
The post is designed to give you the basic building block for extracting an image and performing image operations, which you can build upon in your big data analytics solution.
U-SQL’s extensibility model
U-SQL supports extensibility in the following ways:
- Inline C# functions: Since U-SQL uses the C# type system, it supports using C# expressions inline in SELECT statements. When you use a C# function to calculate a value, you need to specifically assign the result to a column name via the AS clause.
@customer_name =
SELECT firstname.Substring(0, 1).ToUpper() AS first_initial, lastname
FROM @customers;
- User Defined Functions (UDFs): U-SQL allows you to call within a U-SQL expression C# code wrapped in a UDF and compiled as a .NET assembly. When transforming a rowset, you can pass one or more columns as parameters to a UDF and the return value gets assigned to a named column via the AS clause.
@customer_name =
SELECT GetFullName(firstname, lastname) AS customer_name
FROM @customers;
// C# code, separately compiled into an assembly.
public string GetFullName(string fname, string lname)
{
return fname + " " +lname;
}
- User Defined Operators (UDOs) : U-SQL allows you to call C# code wrapped in a UDO to impose a schema on an unstructured input stream, write table data to an unstructured output stream, or to transform a rowset (filtering rows, adding new columns, etc.).
@customer_name =
EXTRACT GetFullName(firstname, lastname) AS customer_name
FROM @"/input/customers.tsv"
USING new MyCustomerExtractor();
- User Defined Aggregators (UDAGGs): U-SQL allows you to compose your own user-defined aggregation functions in C# to augment the built-in standard SQL aggregation functions such as SUM, AVG, etc.. UDAGGs take one or more parameters, return one result and appear within SELECT statements.
@order_tip_estimate =
SELECT AGG<WeighTips>(customer_bills, customer_tips) AS weighted_tip
FROM @customers;
Image Processing Libraries in U-SQL
We have published C# libraries that supply UDOs and UDFs for processing images with U-SQL in our GitHub site. In this section, we introduce these UDOs and UDFs and, in the next section, we use them within a U-SQL walkthrough to operate on images.
The basic flow behind processing images in U-SQL has three stages:
- Use the custom UDO extractor ImageExtractor to read a (JPEG or non-JPEG) image file and return the image data as a byte[] column value which contains the same exact image as the file in an (always) JPEG representation. Please note that there is a current limitation in U-SQL that a row cannot exceed a size of 4 MB, so you will run into issues if your image size is greater than 4 MB.
- Use the image processing UDFs to manipulate this byte[] (the UDFs support JPEG and non-JPEG representations within this byte[] despite the previous step always producing a JPEG representation). For example, one UDF extracts metadata from an image to produce textual or numeric data. More interesting UDFs derive an output image from an input image; that output represents the visually transformed input (e.g. rotated or scaled/resized), also stored as a byte[] containing an (always) JPEG representation of the output.
- Use the custom UDO outputter ImageOutputter to writes each byte[] to a JPEG image file so that we can view the output images of the aforementioned UDFs.
The primary reason we favor using the JPEG representation of an image inside the byte[] is that U-SQL has a limit on the size of a row (4 MB), so to store an image of large dimensions in a single value, the image must be stored in a compressed, even lossy, form. It is certainly possible to use PNG (compressed, but lossless) or other representations and strike a different tradeoff between column value size, and image dimensions and fidelity. Obviously, use of any compressed format comes with decompression and/or compression overhead within the UDFs that perform certain image operations; moreover, repeated cycles of lossy decompression and compression (e.g. rotating an image by 180 degrees in two steps of 90 degrees each, with intervening compression and decompression) can amplify image noise and introduce visually objectionable artifacts. So use with caution!
[caption id="attachment_2586" align="alignnone" width="604"]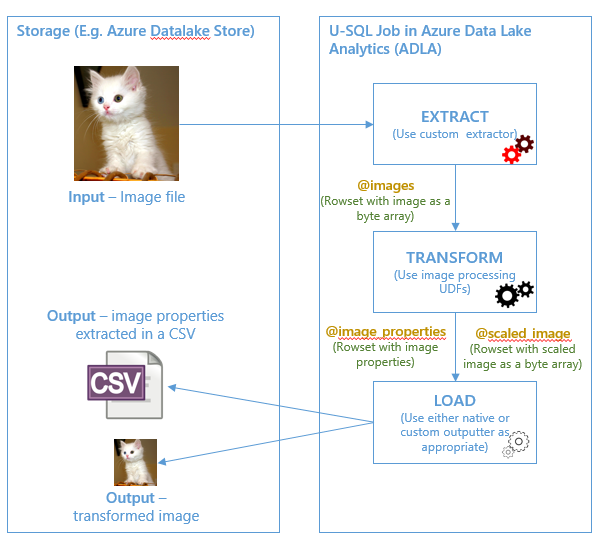 Figure 1 Image Processing using U-SQL workflow[/caption]
Figure 1 Image Processing using U-SQL workflow[/caption]
ImageExtractor
The ImageExtractor is a UDO that derives from the IExtractor interface. It takes an input stream and empty row as inputs, and its job is to fill the row with the stream’s data. The row has one column, which is the representation of an image as a byte[]. The ImageExtractor needs to process the input stream (which is ultimately an image file) as an atomic unit to get the byte[], so it has the AtomicFileProcessing flag set to true. The ImageExtractor is used in U-SQL as follows.
CREATE ASSEMBLY IF NOT EXISTS Images
FROM @"/assemblies/Images.dll"; // only do once
REFERENCE ASSEMBLY Images;
@image_data =
EXTRACT image_data byte[]
FROM @"<replace_this_with_your_input_name>.jpg"
USING new Images.ImageExtractor();
The astute reader of the source code of ImageExtractor will notice that this UDO does not blindly stuff the input stream into a byte[]. Instead, it leverages the power of C# to confirm that the input file is indeed an image file, and then converts it into JPEG format. Can you improve that code? (Hint: what if the input file is already compressed, in any format, to a file size that fits inside a column value?) If you have any suggestions for improvement based on your scenario, do reach out to us at usql@microsoft.com.
ImageOps
This class contains various sample image processing functions that you can use as UDFs in U-SQL.
These functions are built on top of C#’s own Image class as well as on top of some common building blocks.
- One such block comprises the functions byteArrayToImage() and imageToByteArray() which convert between the column value in byte[] form and the C# Image class, performing image format (JPEG or non-JPEG) decompression and JPEG compression at an adjustable JPEG quality.
- A more subtle building block is the drawImage() method which draws an input Image onto a region of an output Bitmap in a manner that clears pixels outside the copy region and also ensures high quality resampling when the input and output region have different dimensions.
- The most esoteric building block is the StreamImage class which pairs together a MemoryStream (tied to the input column value byte[]) and an Image generated from that stream so that the former will not get disposed before the latter; doing so would result in a corrupted Image because the image is lazily decoded from the stream.
The image processing functions comprise a function that fetches metadata as a string, getImageProperty(), and several image-producing functions. All these functions accept the input image as a byte[] and leverage the above utilities to convert it into a StreamImage prior to further processing. The image-producing functions leverage the above utilities to convert an internally generated output image from an Image into a byte[], and return it. Memory leaks are avoided through reliance of the using statement of C#, which is also applicable to StreamImage because the latter implements the IDisposable interface.
The only subtlety when fetching metadata is that C# represents them as a list of PropertyItem instances, which means the key (Id) is always an integer, and the value (Value) is always a byte[] regardless of the semantics of the key and its intended actual representation of a specific type (Type) in byte[] form. So getImageProperty() needs to convert the byte[] into a string in order to return it. The proper conversion should depend on the type and all types should be carefully handled. For simplicity, we used the System.Text.Encoding.UTF8 class to convert PropertyItem instances of string type (type 2, which is an ASCII string but that encoding constraint is not always obeyed by image file creators so we picked UTF8 instead), and the generic ToString() method of byte[] for all other types. Can you do better?
Two of the image producing functions let C# do all the hard work. rotateImage() rotates the input image by 90, 180, or 270 degrees using C#’s Image RotateFlip() method, and simply choosing to do no flipping; one minor subtlety is that this function does not create a separate output Image object, and instead rotates the Image object generated from the input byte[] in-place. scaleImageBy() scales the input image by a specified factor, using a separate output object (a Bitmap, which is a kind of Image).
The last image producing function, scaleImageTo(), scales an input image to specified dimensions but without altering its aspect ratio. That means that, if the specified dimensions and the input image have a different ratio, black bars must be added on the top and bottom or on either side of the input image to border the output image, the way wide movies are sometimes letterboxed on home TVs.
None of the supplied image processing functions need the skills of a rocket scientist to use effectively. Moreover, the Internet is a treasure trove of C# image processing utilities and advanced image processing libraries. The functions in ImageOps are simple, even simplistic, so that they don’t distract from the big picture of the overall data flow, which comprises going from
- a byte[] storing an input image in a JPEG or non-JPEG representation, to
- a C# Image wrapped inside a StreamImage, then
- leveraging C#’s awesome image processing capabilities, and then
- delivering the result of the last step, which
- if a new Image, is converted back into a byte[] containing a JPEG representation of the output image.
What could be simpler?! (Well, avoiding byte[]’s and having U-SQL support an Image column type would indeed be simpler, but all in due time.)
ImageOutputter
The ImageOutputter is a UDO that derives from the IOutputter interface. It takes a row and output stream as inputs, and its job is to stuff the row into the output stream. The row has one column, which is the representation of the image as a byte[]. Currently, U-SQL allows us to output to only one stream (which is ultimately a single file) in a U-SQL statement, which means only a single row can be practically processed, and so a single image is written to a single image file. We are working on enabling dynamic partitioning of output, that will help us output multiple images and therefore process multiple rows. Similar to ImageExtractor, ImageOutputter also has the AtomicFileProcessing flag set to true. The ImageOutputter is used in U-SQL as follows.
OUTPUT @output_image
TO "<replace_this_with_your_output_name>.jpg"
USING new Images.ImageOutputter();
As with ImageExtractor, the astute reader of the source code of ImageOutputter will notice that this UDO does not blindly stuff the byte[] into the output stream. Instead, it leverages the power of C# to confirm that the input byte[] is indeed an image, and then converts it into JPEG format. Can you improve that code to prevent recompression when it is unnecessary?
Sample U-SQL code that works with images
In our walkthrough, you are going to operate on a single image using U-SQL to accomplish these tasks:
- Extract information (copyright information, make and model of the camera and image description) about the image from its embedded metadata.
- Manipulate the image to create a new image (generate a 150x150 thumbnail).
The complete source code in the walkthrough is also posted in our GitHub site.
Step 0 – Reference the image assemblies
First, you will need to reference the Images.dll assembly that contains the UDOs (Extractor and Outputter) and the UDFs to process images. We are working on a blog post that talks in detail about registering and referencing assemblies in U-SQL.
CREATE ASSEMBLY IF NOT EXISTS Images
FROM @"/assemblies/Images.dll";
REFERENCE ASSEMBLY Images;
Note: The code above assumes that you have the Images.dll assembly in the /assemblies folder in your default Azure Data Lake Store (ADLS) account.
Step 1 – Extract image
Before you can operate on images, you first convert an image file into a single-row table with a single column of byte[] type using the ImageExtractor.
@image_data =
EXTRACT image_data byte[]
FROM @"/Samples/input/guard.jpg"
USING new Images.ImageExtractor();
Step 2 – Do transformations as you wish
Now, you can use the Image UDFs in your SELECT statement to perform the image operations. The first SELECT uses getImageProperty() to extract metadata, and the second SELECT creates an image thumbnail via scaleImageTo().
DECLARE @image_copyright_id int = 0x8298;
DECLARE @image_make_id int = 0x010F;
DECLARE @image_model_id int = 0x0110;
DECLARE @image_description_id int = 0x010E;
@image_properties =
SELECT Images.ImageOps.getImageProperty(image_data, @image_copyright_id) AS image_copyright,
Images.ImageOps.getImageProperty(image_data, @image_make_id) AS image_equipment_make,
Images.ImageOps.getImageProperty(image_data, @image_model_id) AS image_equipment_model,
Images.ImageOps.getImageProperty(image_data, @image_description_id) AS image_description
FROM @image_data;
@scaled_image =
SELECT Images.ImageOps.scaleImageTo(image_data, 150, 150) AS thumbnail_image
FROM @image_data;
Step 3 – Output the transformed data
The @image_properties rowset contains four string columns – the copyright information, make and model of the camera and image description – so you can use a native text outputter to output these values. To output the thumbnail, however, you will need to use the ImageOutputter – the current limitation (that we are working on addressing) of this outputter is that you can write one image at a time using this outputter, which is why our sample walkthrough operated on a single image.
OUTPUT @image_properties
TO @"/Samples/output/metadata.csv"
USING Outputters.Csv();
OUTPUT @scaled_image
TO "/Samples/output/thumbnail.jpg"
USING new Images.ImageOutputter();
In conclusion
Thank you for reading this post. This is an illustration of leveraging the seamless integration of SQL and C# and our rich C# assemblies to accomplish image processing at scale with a few lines of U-SQL code. If you have any questions or feedback, please let us know in the comments or by emailing us at usql@microsoft.com.