Azure Data Architecture Guide – Blog #5: Clickstream analysis
We'll continue to delve into the Azure Data Architecture Guide with our fifth blog entry in this series. The entries for this blog series are:
- Azure Data Architecture Guide – Blog #1: Introduction
- Azure Data Architecture Guide – Blog #2: On-demand big data analytics
- Azure Data Architecture Guide – Blog #3: Advanced analytics and deep learning
- Azure Data Architecture Guide – Blog #4: Hybrid data architecture
- Azure Data Architecture Guide – Blog #5: Clickstream analysis - This one
- Azure Data Architecture Guide – Blog #6: Business intelligence
Like the previous post, we'll work from a technology implementation seen directly in our customer engagements. The example can help lead you to the ADAG content to make the right technology choices for your business.
Clickstream analysis
Engage with your customers and uncover insights from data generated by clickstream logs in real-time, using Azure. Rapidly ingest incoming data through Event Hubs (or leverage Apache Kafka), process it with Spark streaming and Spark ML for predicting product recommendations, then use the Spark to Azure Cosmos DB connector to save the processed data to Cosmos DB for global distribution to your customers, wherever they are.
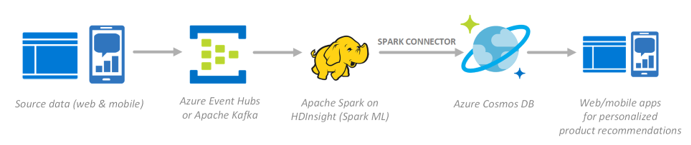
As an alternative to Apache Sparks on HDInsight (Spark ML), you can use Azure Databricks—a fast, easy, and collaborative Apache Spark–based analytics service.
Highlighted services
Related ADAG articles
- Big data architectures
- Scenarios
- Technology choices
Please peruse ADAG to find a clear path for you to architect your data solution on Azure:
![]()
Azure CAT Guidance
"Hands-on solutions, with our heads in the Cloud!"