Parallel Virtual File Systems on Microsoft Azure – Part 4: BeeGFS on Azure
Written by Kanchan Mehrotra, Tony Wu, and Rakesh Patil from AzureCAT. Reviewed by Solliance. Edited by Nanette Ray.
This article is also available as an eBook:
Find previously published parts of this series here:

BeeGFS is a Linux-based, hardware-independent parallel file system and designed for high-performance and high-throughput environments at Fraunhofer ITWM. (Its original name was FhGFS.) BeeGFS is free to use and offers commercial support.
One advantage of the BeeGFS client service is that it provides a normal mount point that your applications can use to directly access the BeeGFS storage system. Compared to Lustre, BeeGFS seemed more flexible and easier to use in our opinion. Lustre IOPs performance outpaced BeeGFS—a result of the Lustre caching effect, we believe. BeeGFS plans to add native Windows client software this year, which we expect will boost BeeGFS performance to Lustre levels.
BeeGFS consists of four main components, each running as a multithreaded daemon process in the Linux operating system:
- Management service and attached management target disk
- OSS and attached storage target disk
- MDS and attached metadata target disk
- File system client
The BeeGFS User Guide illustrates this system architecture. To set up BeeGFS on Azure, you need a minimum of three nodes—one for the management service, and one each for storage and MDS. It is technically possible to install all four components on one virtual machine, but practically speaking, at least three virtual machines should be used.
All configuration files for a BeeGFS installation must point to the same management service, which maintains a list of all file system components, including client, MDS, MDT, OSS, and storage target. Because the management service is not involved in operations, it’s not performance-critical. You can use an A-series virtual machine to host the management service as head node.
The test environment included:
- A total of 46 virtual machines of DS14v2 size used as clients.
- A total of 20 virtual machines of DS14v2 size used to run both storage servers and metadata servers.
- One virtual machine running as BeeGFS management server.
- A total of six 128-GB Premium solid-state drives (SSD) with locally redundant storage (LRS) used as metadata target servers and software RAID 0 on each metadata server.
- A total of 10 512-GB Premium SSDs with LRS used as storage target with software RAID 0 on each storage server.
- One Premium storage account for each virtual machine hosting its associated Premium SSD used for both metadata target and object storage target.
- OpenMPI (included in CentOS 7.2) as the MPI interface.
- IOR 3.01 and MDTEST 1.91 running on each client virtual machine as benchmarking tools over openMPI.
Installation
The easiest way to deploy a test environment for BeeGFS on Azure is to use a Resource Manager template available on GitHub. The template deploys a BeeGFS cluster of virtual machines running the Openlogic CentOS 7.2 image from Azure Marketplace with the metadata service and storage nodes.
To install BeeGFS, go to GitHub and follow the instructions at https://github.com/smith1511/hpc/tree/master/beegfs-shared-on-centos7.2.
Install the testing tools. If you installed the IOR and MDTest tools as part of the Lustre file system evaluation, you do not need to reinstall them. If not, see the Appendix.
Validate the configuration. On the BeeGFS management server, run the following command:
[root@storage0 azureuser]# beegfs-dfMake sure you have enough free disk space for the metadata target and storage data target. Refer to the following examples.
METADATA SERVERS: TargetID Pool Total Free % ITotal IFree % ======== ==== ===== ==== = ====== ===== === 1 normal 575.2GiB 575.0GiB 100% 383.8M 383.8M 100% 2 normal 575.2GiB 575.0GiB 100% 383.8M 383.8M 100% 3 normal 575.2GiB 575.0GiB 100% 383.8M 383.8M 100% 4 normal 575.2GiB 575.1GiB 100% 383.8M 383.8M 100% 5 normal 575.2GiB 575.0GiB 100% 383.8M 383.8M 100% STORAGE TARGETS: TargetID Pool Total Free % ITotal IFree % ======== ==== ===== ==== = ====== ===== === 1 normal 10226.7GiB 10226.7GiB 100% 2045.7M 2045.7M 100% 2 normal 10226.7GiB 10226.7GiB 100% 2045.7M 2045.7M 100% 3 normal 10226.7GiB 10226.7GiB 100% 2045.7M 2045.7M 100%To check communication between the BeeGFS management server, object storage server, and metadata server, list the server nodes by running the following command:
[root@storage0 azureuser]# beegfs-check-serversFor example:
Management ========== storage0 [ID: 1]: reachable at 10.0.0.5:8008 (protocol: TCP) Metadata ========== storage26 [ID: 1]: reachable at 10.0.0.31:8005 (protocol: TCP) storage15 [ID: 2]: reachable at 10.0.0.20:8005 (protocol: TCP) storage16 [ID: 3]: reachable at 10.0.0.21:8005 (protocol: TCP) storage0 [ID: 4]: reachable at 10.0.0.5:8005 (protocol: TCP) Storage ========== storage16 [ID: 1]: reachable at 10.0.0.21:8003 (protocol: TCP) storage0 [ID: 2]: reachable at 10.0.0.5:8003 (protocol: TCP) storage25 [ID: 3]: reachable at 10.0.0.30:8003 (protocol: TCP) storage33 [ID: 4]: reachable at 10.0.0.38:8003 (protocol: TCP)
BeeGFS performance tests
To evaluate the performance of BeeGFS, we ran tests to measure maximum throughput and IOPs just as we did with the Lustre and GlusterFS file systems. Several factors affected our BeeGFS test results:
- Quota limits: To test scalability, we added nodes. But the quota for our Azure environment limited our ability to fully test the massive scalability of BeeGFS.
- Virtual machine size: DS14v2 was used for both the BeeGFS client and storage nodes. We compared our results to the published performance numbers for a virtual machine of this size (see Table 1), and our results showed an 80-percent efficiency.
- Count of parallel processes: In our testing, it worked best to run around 32 processes in each client. We recommend running multiple tests to determine the number of processes that drive the best results.
- Tuning parameters: We tested various parameters to see which gave the better result and made the most of the underlying concurrency features of the BeeGFS file system. We found it helped to vary the number of processes to be generated from the clients along with the number of files and size of block and transfer I/O.
Maximum throughput test results
To measure read and write throughput, we used the following IOR syntax:
mpirun -np <n_procs> -<hostfile> ~/<nodefile> /usr/bin/ior -w -r -B -C
-i4 -t32m -b4G -F -o /share/scratch/ior
Where:
<n_proc> is the number of processes, which depends on the number of clients and OSs
<nodefile> needs to be created to reflect the name of clients used to run benchmark
-w indicates write operation
-r indicates read operation
-B indicates to bypass the cache
-i is the number of iterations
-t indicates transfer size
-b indicates file size created by each process
-F indicates file per process
-o is output test file
Table 1 lists the results alongside the Azure virtual machine limits for comparison.
Table 1. Maximum throughput results for BeeGFS 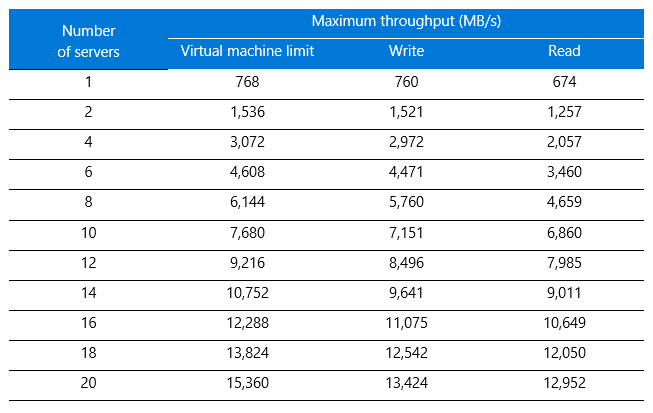
Figure 1 presents the write throughput results, with the y-axis showing maximum throughput and the x-axis showing the number of storage nodes. The blue bars show the Azure maximum limit per virtual machine for driving throughput. (For details, see Azure Linux VM sizes in the Azure documentation.) The orange and gray bars represent the BeeGFS performance for writes and reads, respectively, running on the virtual machine. The scale-out performance output was linear with an average efficiency above 80 percent compared to the raw performance of the virtual machine.
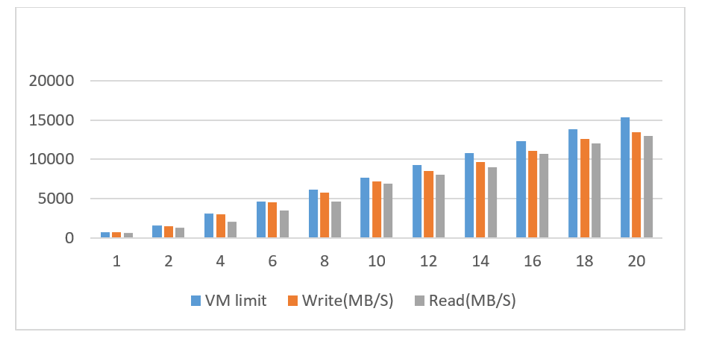
Figure 1. Write throughput results for BeeGFS compared to virtual machine limits
Azure virtual machine limits are not caused by a bottleneck with the premium disk, but rather reflect the limit of the virtual machine itself (see Table 2). Our setup had sufficient raw disk performance:
Raid0 – 10 × P20=10 ×150 MB/s = 1,500 MB/s
For higher performance, you can choose G-series or DS15v2 virtual machines depending on your SSD and virtual machine configuration. To find the best option, make sure the virtual machine-to-disk throughput matches by considering both the virtual machine size and the disk performance.
Table 2. Size and performance specifications for DS14v2 virtual machines 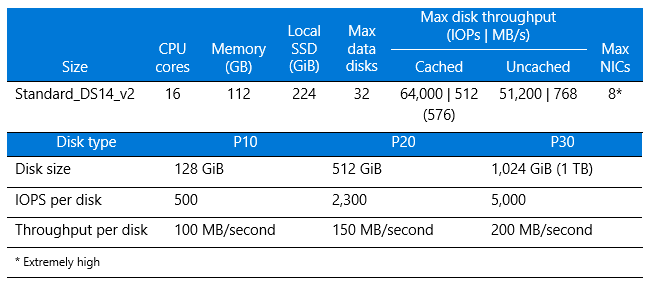
IOPs test results
To measure IOPs on Azure, we used the following syntax:
mpirun -np <n_procs> -<hostfile> ~/nodefile /usr/bin/ior -w -r -B -C -i4
-t4k -b320m -F -o /share/scratch/ior
The results are shown in Table 3.
Table 3. IOPs results for BeeGFS 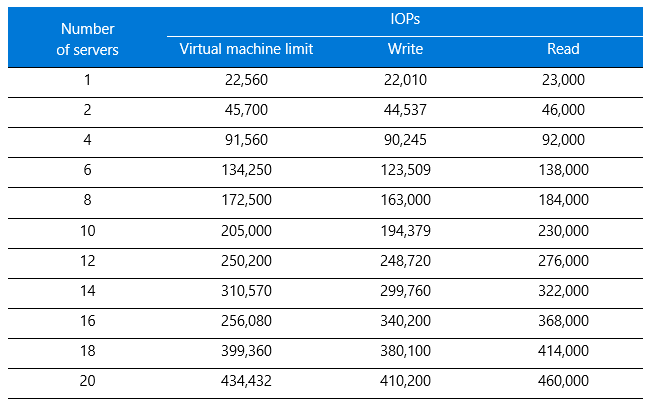
When the results are graphed, you can see the linear progression as servers are added (Figure 2). The y-axis shows IOPS and the x-axis shows the number of servers. Compared to the raw virtual machine performance values shown in gray, BeeGFS write and read IOPs performed with an average efficiency above 80 percent on Azure.
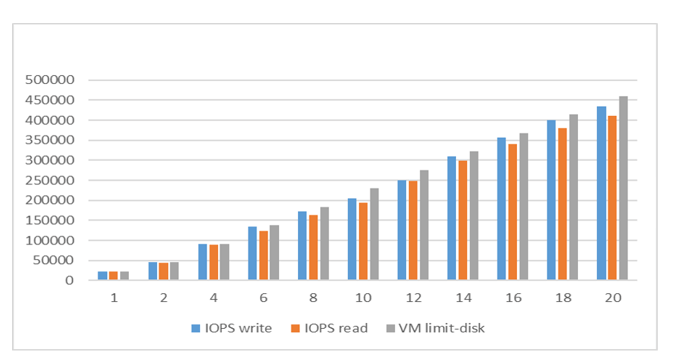
Figure 2. IOPs test results for BeeGFS compared to virtual machine limits
Metadata test results
For the metadata operation testing, we used MDTest with the following syntax on the client node:
mpirun -np <n_procs> -hostfile ~/nodefile /usr/bin/mdtest -C -T -d
/share/scratch/mdtest5/ -i4 -I 2000 -z 2 -b 4 -L -u -F
Here, each client process creates a directory two levels deep and four levels wide, and each folder contains 2,000 files with file creation and state operation tests. Figure 3 shows sample output.
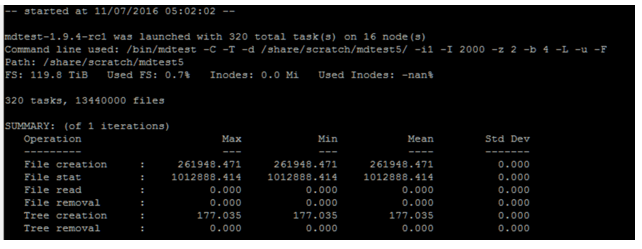
Figure 3. BeeGFS metadata operation test results
BeeGFS evaluation
Our tests demonstrated the linear scale of BeeGFS performance for throughput and IOPs. To increase performance and capacity, we simply added object storage server and metadata server nodes or targets when needed.
The metadata servers showed balanced performance in handling work requests. In general, serving metadata requires a powerful CPU with lots of memory for caching, so we recommend Azure Premium SSD for IOPs and low latency on highly random access patterns with small read and write operations. You can use either RAID 0 or a single Premium SSD. For instance, you can combine P10s as RAID 0 or use a single P20. The lab testing shows that P20 may be better than RAID 0 compared to four or fewer P10s. You don’t typically need two large-capacity SSDs for MDT as the size is around 0.1 to 0.3 percent of total data capacity.
The IOPs results showed 80-percent efficiency on average against the performance baseline of the system. Latency on average was less than a 10-ms response time—acceptable for many types of applications. From a storage I/O perspective, even higher IOPs can be achieved through a large disk queue, but then latency could increase. To decrease the latency, do not increase the disk queue beyond its limit.
For a future testing pass, we’d like to showcase the scale of metadata beyond the 16-node scale we tested. For example, BeeGFS multi-mode could be used to run multiple instances of the BeeGFS service on the same machine with different targets.
We also looked at high availability, because the virtual machines are not redundant, and the storage node or metadata node could possibly malfunction. BeeGFS 6.0 provides HA features for the OSS and OST nodes and the MDS and MDT nodes at the file system level. The Azure infrastructure supports HA through availability sets and virtual machine scale sets for virtual machines, Managed Disks for storage, locally redundant storage, and geo-redundant storage.
Among the HA findings:
- Connectivity among different components can be supported at the same time over InfiniBand, Ethernet, or any other TCP-enabled network and can automatically switch to a redundant connection path in case any of them fails.
- If the management service fails, the system can continue to operate—you just can’t add new clients or servers until it is restored.
Thank you for reading!
This article is also available as an eBook:
![]()
Azure CAT Guidance
"Hands-on solutions, with our heads in the Cloud!"